 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoMC: Localized Multidirectional Correction for Refusal Suppression in Routed Foundation Models
Jun 10, 2026We study controlled post-training refusal suppression in routed MoE and hybrid-MoE foundation models, aiming to increase non-refusal target-response behavior while preserving general capability under a compact intervention footprint. Existing broad direction-based edits can perturb general-purpose computation, whereas support-only expert edits often lack sufficient capacity to correct heterogeneous refusal representations. To address this limitation, we introduce Localized Multidirectional Correction (LoMC), a support-gated intervention framework that follows a support-then-correction execution order: it first identifies a compact edit support, then aggregates prototype correction directions into layer-wise correction directions, and finally applies rank-one layer-wise correction only within the selected support. By using the edit support as a structural gating constraint, LoMC increases correction capacity without expanding the intervention scope. Experiments on text-only and multimodal safety benchmarks across four routed backbones show that LoMC substantially improves non-refusal target-response behavior while maintaining general capability under a compact intervention footprint.
Causal Probing for Internal Visual Representations in Multimodal Large Language Models
May 07, 2026Despite the remarkable success of Multimodal Large Language Models (MLLMs) across diverse tasks, the internal mechanisms governing how they encode and ground distinct visual concepts remain poorly understood. To bridge this gap, we propose a causal framework based on activation steering to actively probe and manipulate internal visual representations. Through systematic intervention across four visual concept categories, our results reveal a divergence in concept encoding: entities exhibit distinct localized memorization, whereas abstract concepts are globally distributed across the network. Critically, this divergence uncovers a mechanistic driver of scaling laws: increasing model depth is indispensable for encoding distributed and complex abstract concepts, whereas entity localization remains remarkably invariant to scale. Furthermore, reverse steering uncovers that blocking explicit output triggers a surge in latent activations, exposing a compensatory mechanism between perception and generation. Finally, extending our analysis to visual reasoning, we expose a disconnect between perception and reasoning although MLLMs successfully recognize geometric relations, they treat them merely as static visual features, failing to trigger the procedural execution necessary for abstract problem-solving.
NTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild
Apr 13, 2026This paper presents an overview of the NTIRE 2026 Challenge on Robust AI-Generated Image Detection in the Wild, held in conjunction with the NTIRE workshop at CVPR 2026. The goal of this challenge was to develop detection models capable of distinguishing real images from generated ones in realistic scenarios: the images are often transformed (cropped, resized, compressed, blurred) for practical usage, and therefore, the detection models should be robust to such transformations. The challenge is based on a novel dataset consisting of 108,750 real and 185,750 AI-generated images from 42 generators comprising a large variety of open-source and closed-source models of various architectures, augmented with 36 image transformations. Methods were evaluated using ROC AUC on the full test set, including both transformed and untransformed images. A total of 511 participants registered, with 20 teams submitting valid final solutions. This report provides a comprehensive overview of the challenge, describes the proposed solutions, and can be used as a valuable reference for researchers and practitioners in increasing the robustness of the detection models to real-world transformations.
Zooming without Zooming: Region-to-Image Distillation for Fine-Grained Multimodal Perception
Feb 16, 2026Multimodal Large Language Models (MLLMs) excel at broad visual understanding but still struggle with fine-grained perception, where decisive evidence is small and easily overwhelmed by global context. Recent "Thinking-with-Images" methods alleviate this by iteratively zooming in and out regions of interest during inference, but incur high latency due to repeated tool calls and visual re-encoding. To address this, we propose Region-to-Image Distillation, which transforms zooming from an inference-time tool into a training-time primitive, thereby internalizing the benefits of agentic zooming into a single forward pass of an MLLM. In particular, we first zoom in to micro-cropped regions to let strong teacher models generate high-quality VQA data, and then distill this region-grounded supervision back to the full image. After training on such data, the smaller student model improves "single-glance" fine-grained perception without tool use. To rigorously evaluate this capability, we further present ZoomBench, a hybrid-annotated benchmark of 845 VQA data spanning six fine-grained perceptual dimensions, together with a dual-view protocol that quantifies the global--regional "zooming gap". Experiments show that our models achieve leading performance across multiple fine-grained perception benchmarks, and also improve general multimodal cognition on benchmarks such as visual reasoning and GUI agents. We further discuss when "Thinking-with-Images" is necessary versus when its gains can be distilled into a single forward pass. Our code is available at https://github.com/inclusionAI/Zooming-without-Zooming.
VideoVeritas: AI-Generated Video Detection via Perception Pretext Reinforcement Learning
Feb 09, 2026The growing capability of video generation poses escalating security risks, making reliable detection increasingly essential. In this paper, we introduce VideoVeritas, a framework that integrates fine-grained perception and fact-based reasoning. We observe that while current multi-modal large language models (MLLMs) exhibit strong reasoning capacity, their granular perception ability remains limited. To mitigate this, we introduce Joint Preference Alignment and Perception Pretext Reinforcement Learning (PPRL). Specifically, rather than directly optimizing for detection task, we adopt general spatiotemporal grounding and self-supervised object counting in the RL stage, enhancing detection performance with simple perception pretext tasks. To facilitate robust evaluation, we further introduce MintVid, a light yet high-quality dataset containing 3K videos from 9 state-of-the-art generators, along with a real-world collected subset that has factual errors in content. Experimental results demonstrate that existing methods tend to bias towards either superficial reasoning or mechanical analysis, while VideoVeritas achieves more balanced performance across diverse benchmarks.
Adaptive and Balanced Re-initialization for Long-timescale Continual Test-time Domain Adaptation
Feb 06, 2026Continual test-time domain adaptation (CTTA) aims to adjust models so that they can perform well over time across non-stationary environments. While previous methods have made considerable efforts to optimize the adaptation process, a crucial question remains: Can the model adapt to continually changing environments over a long time? In this work, we explore facilitating better CTTA in the long run using a re-initialization (or reset) based method. First, we observe that the long-term performance is associated with the trajectory pattern in label flip. Based on this observed correlation, we propose a simple yet effective policy, Adaptive-and-Balanced Re-initialization (ABR), towards preserving the model's long-term performance. In particular, ABR performs weight re-initialization using adaptive intervals. The adaptive interval is determined based on the change in label flip. The proposed method is validated on extensive CTTA benchmarks, achieving superior performance.
VTONGuard: Automatic Detection and Authentication of AI-Generated Virtual Try-On Content
Jan 20, 2026With the rapid advancement of generative AI, virtual try-on (VTON) systems are becoming increasingly common in e-commerce and digital entertainment. However, the growing realism of AI-generated try-on content raises pressing concerns about authenticity and responsible use. To address this, we present VTONGuard, a large-scale benchmark dataset containing over 775,000 real and synthetic try-on images. The dataset covers diverse real-world conditions, including variations in pose, background, and garment styles, and provides both authentic and manipulated examples. Based on this benchmark, we conduct a systematic evaluation of multiple detection paradigms under unified training and testing protocols. Our results reveal each method's strengths and weaknesses and highlight the persistent challenge of cross-paradigm generalization. To further advance detection, we design a multi-task framework that integrates auxiliary segmentation to enhance boundary-aware feature learning, achieving the best overall performance on VTONGuard. We expect this benchmark to enable fair comparisons, facilitate the development of more robust detection models, and promote the safe and responsible deployment of VTON technologies in practice.
Veritas: Generalizable Deepfake Detection via Pattern-Aware Reasoning
Aug 28, 2025



Deepfake detection remains a formidable challenge due to the complex and evolving nature of fake content in real-world scenarios. However, existing academic benchmarks suffer from severe discrepancies from industrial practice, typically featuring homogeneous training sources and low-quality testing images, which hinder the practical deployments of current detectors. To mitigate this gap, we introduce HydraFake, a dataset that simulates real-world challenges with hierarchical generalization testing. Specifically, HydraFake involves diversified deepfake techniques and in-the-wild forgeries, along with rigorous training and evaluation protocol, covering unseen model architectures, emerging forgery techniques and novel data domains. Building on this resource, we propose Veritas, a multi-modal large language model (MLLM) based deepfake detector. Different from vanilla chain-of-thought (CoT), we introduce pattern-aware reasoning that involves critical reasoning patterns such as "planning" and "self-reflection" to emulate human forensic process. We further propose a two-stage training pipeline to seamlessly internalize such deepfake reasoning capacities into current MLLMs. Experiments on HydraFake dataset reveal that although previous detectors show great generalization on cross-model scenarios, they fall short on unseen forgeries and data domains. Our Veritas achieves significant gains across different OOD scenarios, and is capable of delivering transparent and faithful detection outputs.
Interpretable and Reliable Detection of AI-Generated Images via Grounded Reasoning in MLLMs
Jun 08, 2025
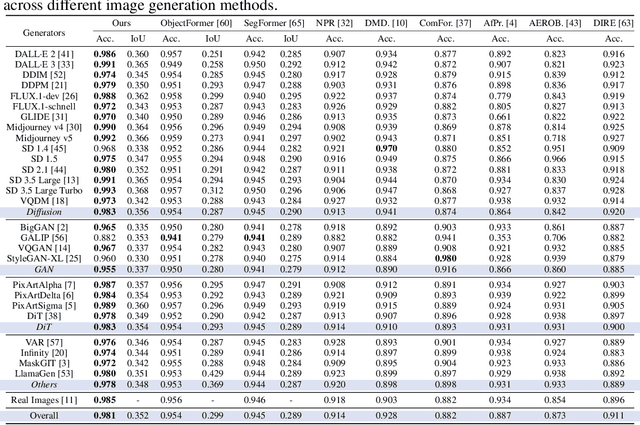


The rapid advancement of image generation technologies intensifies the demand for interpretable and robust detection methods. Although existing approaches often attain high accuracy, they typically operate as black boxes without providing human-understandable justifications. Multi-modal Large Language Models (MLLMs), while not originally intended for forgery detection, exhibit strong analytical and reasoning capabilities. When properly fine-tuned, they can effectively identify AI-generated images and offer meaningful explanations. However, existing MLLMs still struggle with hallucination and often fail to align their visual interpretations with actual image content and human reasoning. To bridge this gap, we construct a dataset of AI-generated images annotated with bounding boxes and descriptive captions that highlight synthesis artifacts, establishing a foundation for human-aligned visual-textual grounded reasoning. We then finetune MLLMs through a multi-stage optimization strategy that progressively balances the objectives of accurate detection, visual localization, and coherent textual explanation. The resulting model achieves superior performance in both detecting AI-generated images and localizing visual flaws, significantly outperforming baseline methods.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.