 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOON Embedding: Multimodal Representation Learning for E-commerce Search Advertising
Nov 18, 2025We introduce MOON, our comprehensive set of sustainable iterative practices for multimodal representation learning for e-commerce applications. MOON has already been fully deployed across all stages of Taobao search advertising system, including retrieval, relevance, ranking, and so on. The performance gains are particularly significant on click-through rate (CTR) prediction task, which achieves an overall +20.00% online CTR improvement. Over the past three years, this project has delivered the largest improvement on CTR prediction task and undergone five full-scale iterations. Throughout the exploration and iteration of our MOON, we have accumulated valuable insights and practical experience that we believe will benefit the research community. MOON contains a three-stage training paradigm of "Pretraining, Post-training, and Application", allowing effective integration of multimodal representations with downstream tasks. Notably, to bridge the misalignment between the objectives of multimodal representation learning and downstream training, we define the exchange rate to quantify how effectively improvements in an intermediate metric can translate into downstream gains. Through this analysis, we identify the image-based search recall as a critical intermediate metric guiding the optimization of multimodal models. Over three years and five iterations, MOON has evolved along four critical dimensions: data processing, training strategy, model architecture, and downstream application. The lessons and insights gained through the iterative improvements will also be shared. As part of our exploration into scaling effects in the e-commerce field, we further conduct a systematic study of the scaling laws governing multimodal representation learning, examining multiple factors such as the number of training tokens, negative samples, and the length of user behavior sequences.
Creative4U: MLLMs-based Advertising Creative Image Selector with Comparative Reasoning
Aug 18, 2025Creative image in advertising is the heart and soul of e-commerce platform. An eye-catching creative image can enhance the shopping experience for users, boosting income for advertisers and advertising revenue for platforms. With the advent of AIGC technology, advertisers can produce large quantities of creative images at minimal cost. However, they struggle to assess the creative quality to select. Existing methods primarily focus on creative ranking, which fails to address the need for explainable creative selection. In this work, we propose the first paradigm for explainable creative assessment and selection. Powered by multimodal large language models (MLLMs), our approach integrates the assessment and selection of creative images into a natural language generation task. To facilitate this research, we construct CreativePair, the first comparative reasoning-induced creative dataset featuring 8k annotated image pairs, with each sample including a label indicating which image is superior. Additionally, we introduce Creative4U (pronounced Creative for You), a MLLMs-based creative selector that takes into account users' interests. Through Reason-to-Select RFT, which includes supervised fine-tuning with Chain-of-Thought (CoT-SFT) and Group Relative Policy Optimization (GRPO) based reinforcement learning, Creative4U is able to evaluate and select creative images accurately. Both offline and online experiments demonstrate the effectiveness of our approach. Our code and dataset will be made public to advance research and industrial applications.
QFFT, Question-Free Fine-Tuning for Adaptive Reasoning
Jun 15, 2025

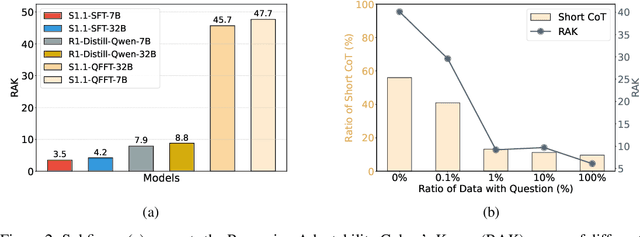

Recent advancements in Long Chain-of-Thought (CoT) reasoning models have improved performance on complex tasks, but they suffer from overthinking, which generates redundant reasoning steps, especially for simple questions. This paper revisits the reasoning patterns of Long and Short CoT models, observing that the Short CoT patterns offer concise reasoning efficiently, while the Long CoT patterns excel in challenging scenarios where the Short CoT patterns struggle. To enable models to leverage both patterns, we propose Question-Free Fine-Tuning (QFFT), a fine-tuning approach that removes the input question during training and learns exclusively from Long CoT responses. This approach enables the model to adaptively employ both reasoning patterns: it prioritizes the Short CoT patterns and activates the Long CoT patterns only when necessary. Experiments on various mathematical datasets demonstrate that QFFT reduces average response length by more than 50\%, while achieving performance comparable to Supervised Fine-Tuning (SFT). Additionally, QFFT exhibits superior performance compared to SFT in noisy, out-of-domain, and low-resource scenarios.
NTIRE 2025 challenge on Text to Image Generation Model Quality Assessment
May 22, 2025This paper reports on the NTIRE 2025 challenge on Text to Image (T2I) generation model quality assessment, which will be held in conjunction with the New Trends in Image Restoration and Enhancement Workshop (NTIRE) at CVPR 2025. The aim of this challenge is to address the fine-grained quality assessment of text-to-image generation models. This challenge evaluates text-to-image models from two aspects: image-text alignment and image structural distortion detection, and is divided into the alignment track and the structural track. The alignment track uses the EvalMuse-40K, which contains around 40K AI-Generated Images (AIGIs) generated by 20 popular generative models. The alignment track has a total of 371 registered participants. A total of 1,883 submissions are received in the development phase, and 507 submissions are received in the test phase. Finally, 12 participating teams submitted their models and fact sheets. The structure track uses the EvalMuse-Structure, which contains 10,000 AI-Generated Images (AIGIs) with corresponding structural distortion mask. A total of 211 participants have registered in the structure track. A total of 1155 submissions are received in the development phase, and 487 submissions are received in the test phase. Finally, 8 participating teams submitted their models and fact sheets. Almost all methods have achieved better results than baseline methods, and the winning methods in both tracks have demonstrated superior prediction performance on T2I model quality assessment.
InterAnimate: Taming Region-aware Diffusion Model for Realistic Human Interaction Animation
Apr 15, 2025Recent video generation research has focused heavily on isolated actions, leaving interactive motions-such as hand-face interactions-largely unexamined. These interactions are essential for emerging biometric authentication systems, which rely on interactive motion-based anti-spoofing approaches. From a security perspective, there is a growing need for large-scale, high-quality interactive videos to train and strengthen authentication models. In this work, we introduce a novel paradigm for animating realistic hand-face interactions. Our approach simultaneously learns spatio-temporal contact dynamics and biomechanically plausible deformation effects, enabling natural interactions where hand movements induce anatomically accurate facial deformations while maintaining collision-free contact. To facilitate this research, we present InterHF, a large-scale hand-face interaction dataset featuring 18 interaction patterns and 90,000 annotated videos. Additionally, we propose InterAnimate, a region-aware diffusion model designed specifically for interaction animation. InterAnimate leverages learnable spatial and temporal latents to effectively capture dynamic interaction priors and integrates a region-aware interaction mechanism that injects these priors into the denoising process. To the best of our knowledge, this work represents the first large-scale effort to systematically study human hand-face interactions. Qualitative and quantitative results show InterAnimate produces highly realistic animations, setting a new benchmark. Code and data will be made public to advance research.
MVPortrait: Text-Guided Motion and Emotion Control for Multi-view Vivid Portrait Animation
Mar 25, 2025Recent portrait animation methods have made significant strides in generating realistic lip synchronization. However, they often lack explicit control over head movements and facial expressions, and cannot produce videos from multiple viewpoints, resulting in less controllable and expressive animations. Moreover, text-guided portrait animation remains underexplored, despite its user-friendly nature. We present a novel two-stage text-guided framework, MVPortrait (Multi-view Vivid Portrait), to generate expressive multi-view portrait animations that faithfully capture the described motion and emotion. MVPortrait is the first to introduce FLAME as an intermediate representation, effectively embedding facial movements, expressions, and view transformations within its parameter space. In the first stage, we separately train the FLAME motion and emotion diffusion models based on text input. In the second stage, we train a multi-view video generation model conditioned on a reference portrait image and multi-view FLAME rendering sequences from the first stage. Experimental results exhibit that MVPortrait outperforms existing methods in terms of motion and emotion control, as well as view consistency. Furthermore, by leveraging FLAME as a bridge, MVPortrait becomes the first controllable portrait animation framework that is compatible with text, speech, and video as driving signals.
HVIS: A Human-like Vision and Inference System for Human Motion Prediction
Feb 24, 2025Grasping the intricacies of human motion, which involve perceiving spatio-temporal dependence and multi-scale effects, is essential for predicting human motion. While humans inherently possess the requisite skills to navigate this issue, it proves to be markedly more challenging for machines to emulate. To bridge the gap, we propose the Human-like Vision and Inference System (HVIS) for human motion prediction, which is designed to emulate human observation and forecast future movements. HVIS comprises two components: the human-like vision encode (HVE) module and the human-like motion inference (HMI) module. The HVE module mimics and refines the human visual process, incorporating a retina-analog component that captures spatiotemporal information separately to avoid unnecessary crosstalk. Additionally, a visual cortex-analogy component is designed to hierarchically extract and treat complex motion features, focusing on both global and local features of human poses. The HMI is employed to simulate the multi-stage learning model of the human brain. The spontaneous learning network simulates the neuronal fracture generation process for the adversarial generation of future motions. Subsequently, the deliberate learning network is optimized for hard-to-train joints to prevent misleading learning. Experimental results demonstrate that our method achieves new state-of-the-art performance, significantly outperforming existing methods by 19.8% on Human3.6M, 15.7% on CMU Mocap, and 11.1% on G3D.
Reasoning Graph Enhanced Exemplars Retrieval for In-Context Learning
Sep 17, 2024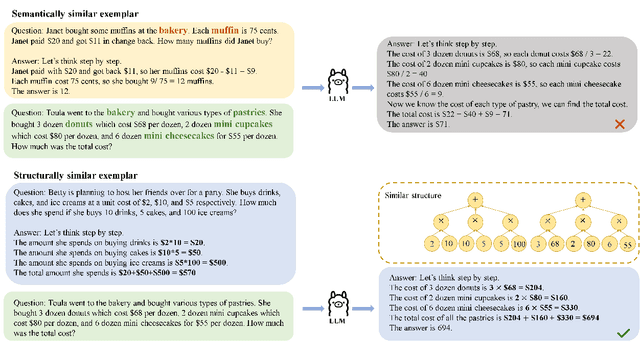
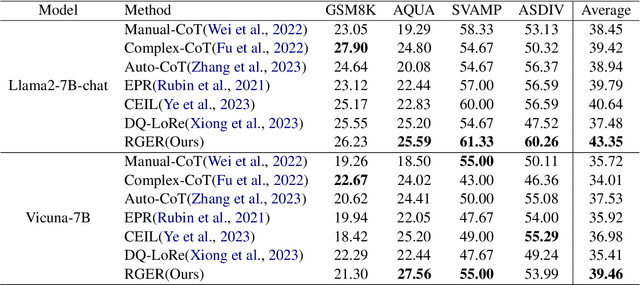
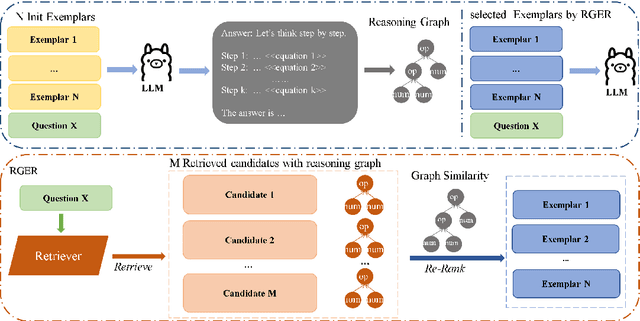

Large language models(LLMs) have exhibited remarkable few-shot learning capabilities and unified the paradigm of NLP tasks through the in-context learning(ICL) technique. Despite the success of ICL, the quality of the exemplar demonstrations can significantly influence the LLM's performance. Existing exemplar selection methods mainly focus on the semantic similarity between queries and candidate exemplars. On the other hand, the logical connections between reasoning steps can be beneficial to depict the problem-solving process as well. In this paper, we proposes a novel method named Reasoning Graph-enhanced Exemplar Retrieval(RGER). RGER first quires LLM to generate an initial response, then expresses intermediate problem-solving steps to a graph structure. After that, it employs graph kernel to select exemplars with semantic and structural similarity. Extensive experiments demonstrate the structural relationship is helpful to the alignment of queries and candidate exemplars. The efficacy of RGER on math and logit reasoning tasks showcases its superiority over state-of-the-art retrieval-based approaches. Our code is released at https://github.com/Yukang-Lin/RGER.
MambaTalk: Efficient Holistic Gesture Synthesis with Selective State Space Models
Mar 14, 2024


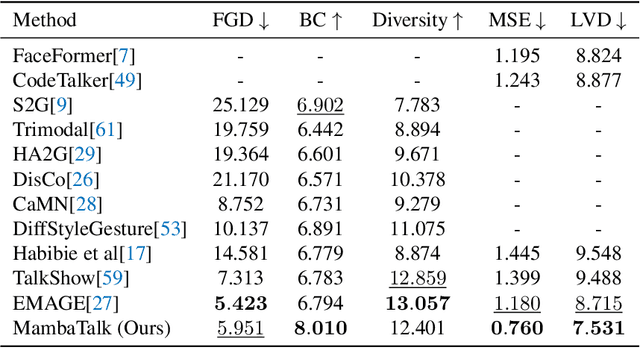
Gesture synthesis is a vital realm of human-computer interaction, with wide-ranging applications across various fields like film, robotics, and virtual reality. Recent advancements have utilized the diffusion model and attention mechanisms to improve gesture synthesis. However, due to the high computational complexity of these techniques, generating long and diverse sequences with low latency remains a challenge. We explore the potential of state space models (SSMs) to address the challenge, implementing a two-stage modeling strategy with discrete motion priors to enhance the quality of gestures. Leveraging the foundational Mamba block, we introduce MambaTalk, enhancing gesture diversity and rhythm through multimodal integration. Extensive experiments demonstrate that our method matches or exceeds the performance of state-of-the-art models.
ZO-AdaMU Optimizer: Adapting Perturbation by the Momentum and Uncertainty in Zeroth-order Optimization
Dec 23, 2023Lowering the memory requirement in full-parameter training on large models has become a hot research area. MeZO fine-tunes the large language models (LLMs) by just forward passes in a zeroth-order SGD optimizer (ZO-SGD), demonstrating excellent performance with the same GPU memory usage as inference. However, the simulated perturbation stochastic approximation for gradient estimate in MeZO leads to severe oscillations and incurs a substantial time overhead. Moreover, without momentum regularization, MeZO shows severe over-fitting problems. Lastly, the perturbation-irrelevant momentum on ZO-SGD does not improve the convergence rate. This study proposes ZO-AdaMU to resolve the above problems by adapting the simulated perturbation with momentum in its stochastic approximation. Unlike existing adaptive momentum methods, we relocate momentum on simulated perturbation in stochastic gradient approximation. Our convergence analysis and experiments prove this is a better way to improve convergence stability and rate in ZO-SGD. Extensive experiments demonstrate that ZO-AdaMU yields better generalization for LLMs fine-tuning across various NLP tasks than MeZO and its momentum variants.