 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReasoning Graph Enhanced Exemplars Retrieval for In-Context Learning
Sep 17, 2024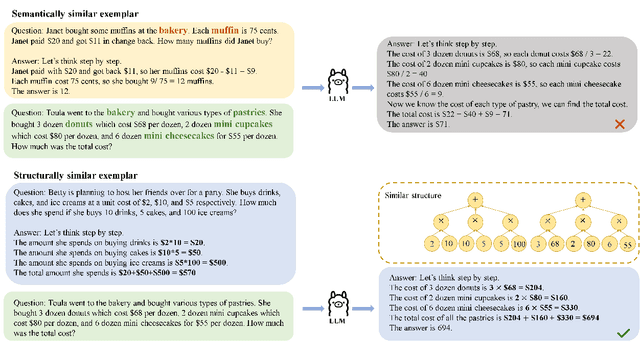
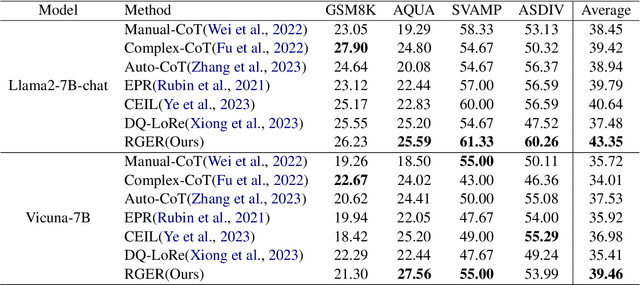
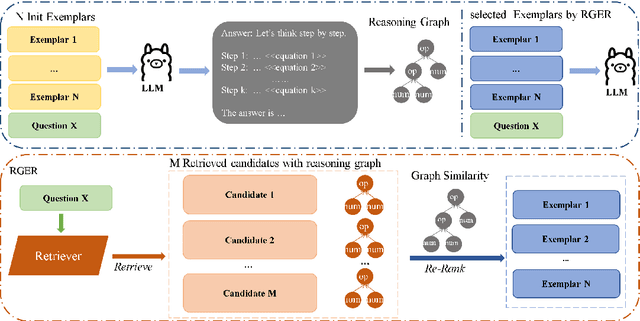

Large language models(LLMs) have exhibited remarkable few-shot learning capabilities and unified the paradigm of NLP tasks through the in-context learning(ICL) technique. Despite the success of ICL, the quality of the exemplar demonstrations can significantly influence the LLM's performance. Existing exemplar selection methods mainly focus on the semantic similarity between queries and candidate exemplars. On the other hand, the logical connections between reasoning steps can be beneficial to depict the problem-solving process as well. In this paper, we proposes a novel method named Reasoning Graph-enhanced Exemplar Retrieval(RGER). RGER first quires LLM to generate an initial response, then expresses intermediate problem-solving steps to a graph structure. After that, it employs graph kernel to select exemplars with semantic and structural similarity. Extensive experiments demonstrate the structural relationship is helpful to the alignment of queries and candidate exemplars. The efficacy of RGER on math and logit reasoning tasks showcases its superiority over state-of-the-art retrieval-based approaches. Our code is released at https://github.com/Yukang-Lin/RGER.
Enhancing Open-Domain Table Question Answering via Syntax- and Structure-aware Dense Retrieval
Sep 19, 2023



Open-domain table question answering aims to provide answers to a question by retrieving and extracting information from a large collection of tables. Existing studies of open-domain table QA either directly adopt text retrieval methods or consider the table structure only in the encoding layer for table retrieval, which may cause syntactical and structural information loss during table scoring. To address this issue, we propose a syntax- and structure-aware retrieval method for the open-domain table QA task. It provides syntactical representations for the question and uses the structural header and value representations for the tables to avoid the loss of fine-grained syntactical and structural information. Then, a syntactical-to-structural aggregator is used to obtain the matching score between the question and a candidate table by mimicking the human retrieval process. Experimental results show that our method achieves the state-of-the-art on the NQ-tables dataset and overwhelms strong baselines on a newly curated open-domain Text-to-SQL dataset.
A Survey on Table Question Answering: Recent Advances
Jul 12, 2022
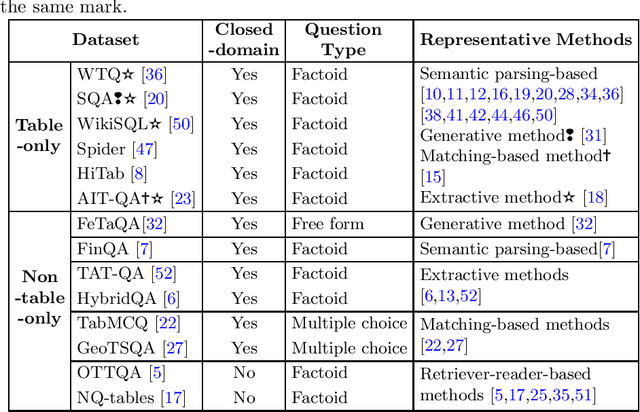


Table Question Answering (Table QA) refers to providing precise answers from tables to answer a user's question. In recent years, there have been a lot of works on table QA, but there is a lack of comprehensive surveys on this research topic. Hence, we aim to provide an overview of available datasets and representative methods in table QA. We classify existing methods for table QA into five categories according to their techniques, which include semantic-parsing-based, generative, extractive, matching-based, and retriever-reader-based methods. Moreover, as table QA is still a challenging task for existing methods, we also identify and outline several key challenges and discuss the potential future directions of table QA.
VLDeformer: Learning Visual-Semantic Embeddings by Vision-Language Transformer Decomposing
Oct 20, 2021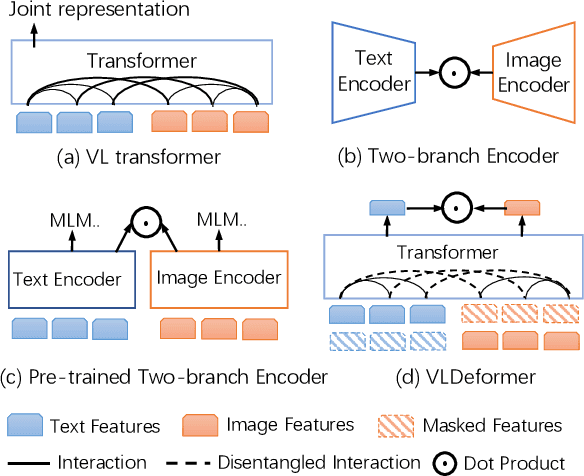
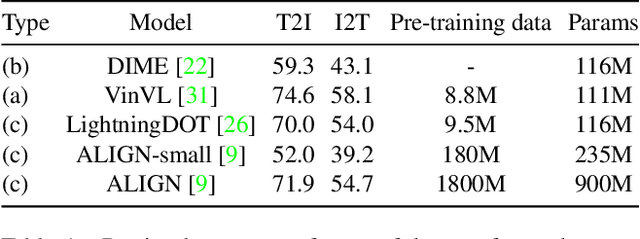
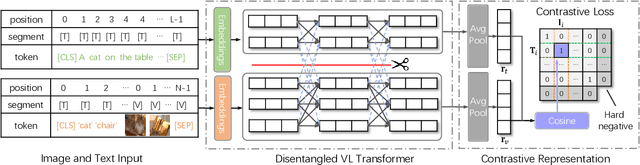
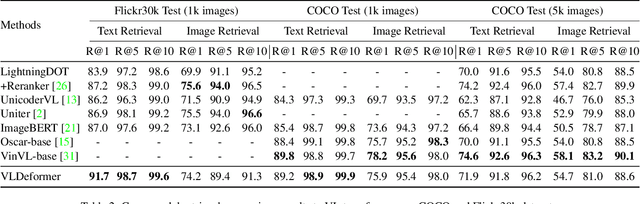
Vision-language transformers (VL transformers) have shown impressive accuracy in cross-modal retrieval. However, most of the existing VL transformers use early-interaction dataflow that computes a joint representation for the text-image input. In the retrieval stage, such models need to infer on all the matched text-image combinations, which causes high computing costs. The goal of this paper is to decompose the early-interaction dataflow inside the pre-trained VL transformer to achieve acceleration while maintaining its outstanding accuracy. To achieve this, we propose a novel Vision-language Transformer Decomposing (VLDeformer) to modify the VL transformer as an individual encoder for a single image or text through contrastive learning, which accelerates retrieval speed by thousands of times. Meanwhile, we propose to compose bi-modal hard negatives for the contrastive learning objective, which enables the VLDeformer to maintain the outstanding accuracy of the backbone VL transformer. Extensive experiments on COCO and Flickr30k datasets demonstrate the superior performance of the proposed method. Considering both effectiveness and efficiency, VLDeformer provides a superior selection for cross-modal retrieval in the similar pre-training datascale.
Decomposing Word Embedding with the Capsule Network
Apr 07, 2020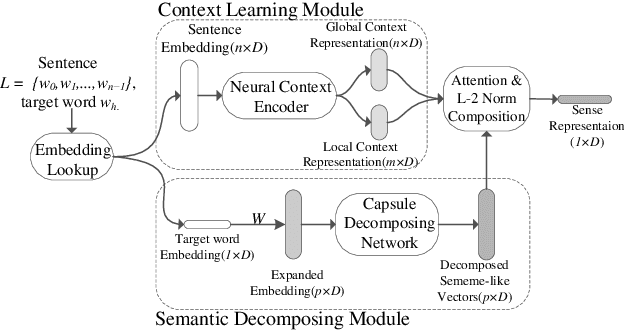
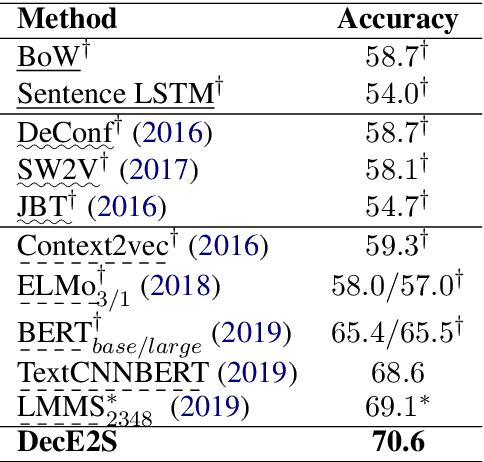
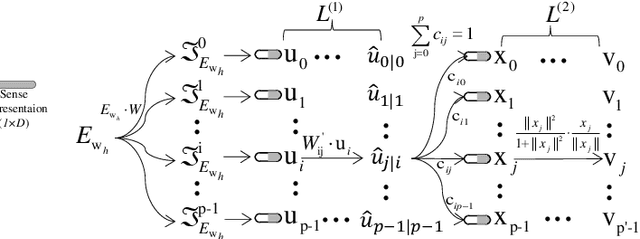
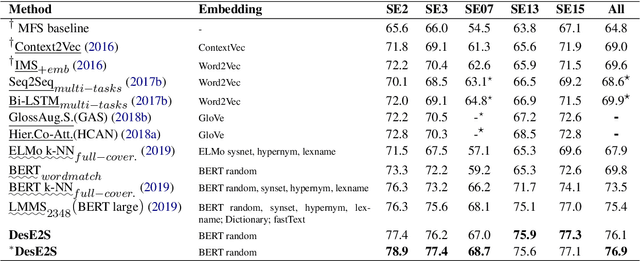
Multi-sense word embeddings have been promising solutions for word sense learning. Nevertheless, building large-scale training corpus and learning appropriate word sense are still open issues. In this paper, we propose a method for Decomposing the word Embedding into context-specific Sense representation, called DecE2S. First, the unsupervised polysemy embedding is fed into capsule network to produce its multiple sememe-like vectors. Second, with attention operations, DecE2S integrates the word context to represent the context-specific sense vector. To train DecE2S, we design a word matching training method for learning the context-specific sense representation. DecE2S was experimentally evaluated on two sense learning tasks, i.e., word in context and word sense disambiguation. Results on two public corpora Word-in-Context and English all-words Word Sense Disambiguation show that, the DesE2S model achieves the new state-of-the-art for the word in context and word sense disambiguation tasks.