 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAniME: Adaptive Multi-Agent Planning for Long Animation Generation
Aug 27, 2025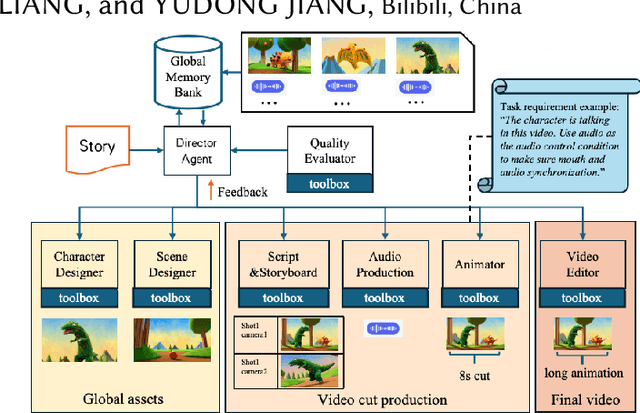
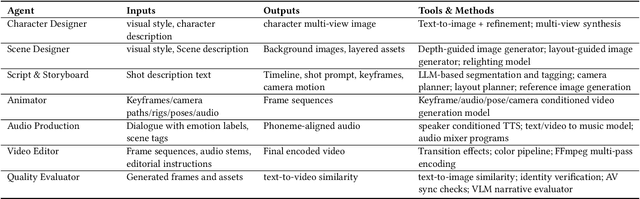

We present AniME, a director-oriented multi-agent system for automated long-form anime production, covering the full workflow from a story to the final video. The director agent keeps a global memory for the whole workflow, and coordinates several downstream specialized agents. By integrating customized Model Context Protocol (MCP) with downstream model instruction, the specialized agent adaptively selects control conditions for diverse sub-tasks. AniME produces cinematic animation with consistent characters and synchronized audio visual elements, offering a scalable solution for AI-driven anime creation.
AsyncDSB: Schedule-Asynchronous Diffusion Schrödinger Bridge for Image Inpainting
Dec 11, 2024

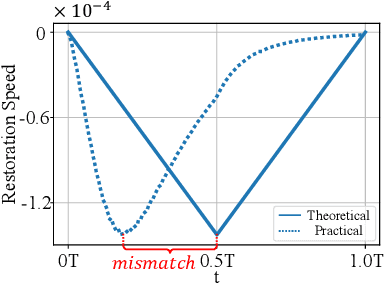
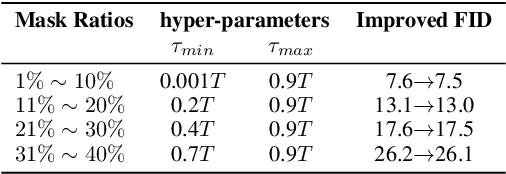
Image inpainting is an important image generation task, which aims to restore corrupted image from partial visible area. Recently, diffusion Schr\"odinger bridge methods effectively tackle this task by modeling the translation between corrupted and target images as a diffusion Schr\"odinger bridge process along a noising schedule path. Although these methods have shown superior performance, in this paper, we find that 1) existing methods suffer from a schedule-restoration mismatching issue, i.e., the theoretical schedule and practical restoration processes usually exist a large discrepancy, which theoretically results in the schedule not fully leveraged for restoring images; and 2) the key reason causing such issue is that the restoration process of all pixels are actually asynchronous but existing methods set a synchronous noise schedule to them, i.e., all pixels shares the same noise schedule. To this end, we propose a schedule-Asynchronous Diffusion Schr\"odinger Bridge (AsyncDSB) for image inpainting. Our insight is preferentially scheduling pixels with high frequency (i.e., large gradients) and then low frequency (i.e., small gradients). Based on this insight, given a corrupted image, we first train a network to predict its gradient map in corrupted area. Then, we regard the predicted image gradient as prior and design a simple yet effective pixel-asynchronous noise schedule strategy to enhance the diffusion Schr\"odinger bridge. Thanks to the asynchronous schedule at pixels, the temporal interdependence of restoration process between pixels can be fully characterized for high-quality image inpainting. Experiments on real-world datasets show that our AsyncDSB achieves superior performance, especially on FID with around 3% - 14% improvement over state-of-the-art baseline methods.
FashionSAP: Symbols and Attributes Prompt for Fine-grained Fashion Vision-Language Pre-training
Apr 11, 2023
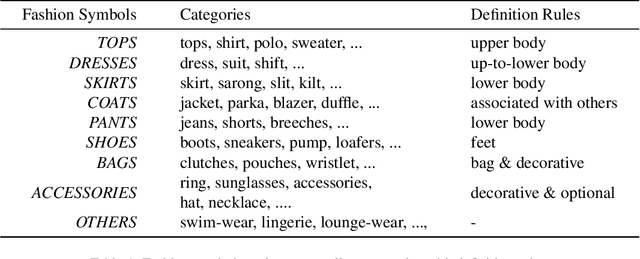
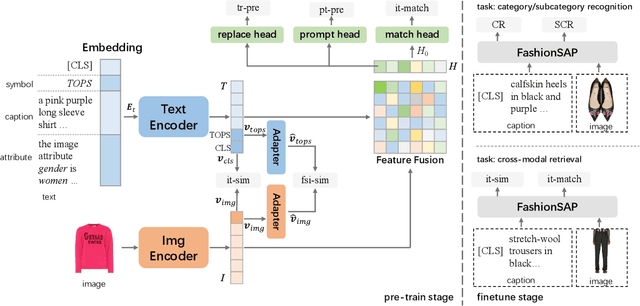
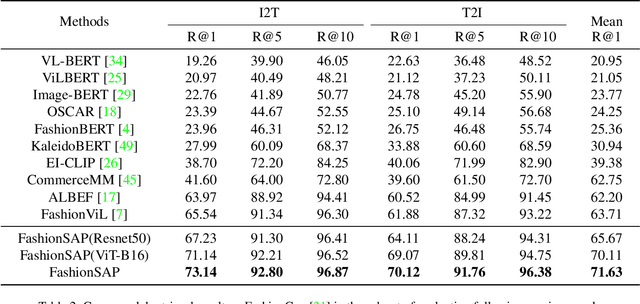
Fashion vision-language pre-training models have shown efficacy for a wide range of downstream tasks. However, general vision-language pre-training models pay less attention to fine-grained domain features, while these features are important in distinguishing the specific domain tasks from general tasks. We propose a method for fine-grained fashion vision-language pre-training based on fashion Symbols and Attributes Prompt (FashionSAP) to model fine-grained multi-modalities fashion attributes and characteristics. Firstly, we propose the fashion symbols, a novel abstract fashion concept layer, to represent different fashion items and to generalize various kinds of fine-grained fashion features, making modelling fine-grained attributes more effective. Secondly, the attributes prompt method is proposed to make the model learn specific attributes of fashion items explicitly. We design proper prompt templates according to the format of fashion data. Comprehensive experiments are conducted on two public fashion benchmarks, i.e., FashionGen and FashionIQ, and FashionSAP gets SOTA performances for four popular fashion tasks. The ablation study also shows the proposed abstract fashion symbols, and the attribute prompt method enables the model to acquire fine-grained semantics in the fashion domain effectively. The obvious performance gains from FashionSAP provide a new baseline for future fashion task research.
Replacement as a Self-supervision for Fine-grained Vision-language Pre-training
Mar 09, 2023



Fine-grained supervision based on object annotations has been widely used for vision and language pre-training (VLP). However, in real-world application scenarios, aligned multi-modal data is usually in the image-caption format, which only provides coarse-grained supervision. It is cost-expensive to collect object annotations and build object annotation pre-extractor for different scenarios. In this paper, we propose a fine-grained self-supervision signal without object annotations from a replacement perspective. First, we propose a homonym sentence rewriting (HSR) algorithm to provide token-level supervision. The algorithm replaces a verb/noun/adjective/quantifier word of the caption with its homonyms from WordNet. Correspondingly, we propose a replacement vision-language modeling (RVLM) framework to exploit the token-level supervision. Two replaced modeling tasks, i.e., replaced language contrastive (RLC) and replaced language modeling (RLM), are proposed to learn the fine-grained alignment. Extensive experiments on several downstream tasks demonstrate the superior performance of the proposed method.
VLDeformer: Learning Visual-Semantic Embeddings by Vision-Language Transformer Decomposing
Oct 20, 2021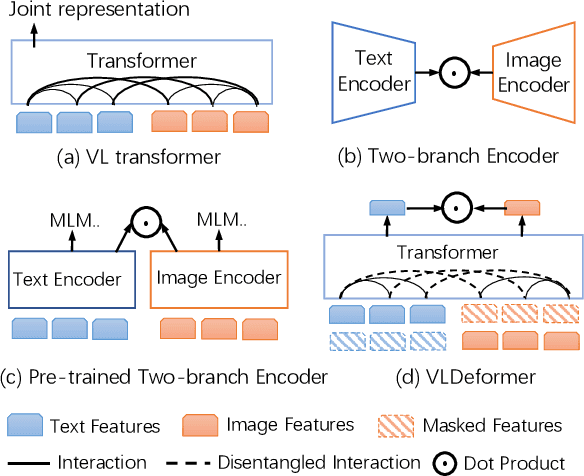
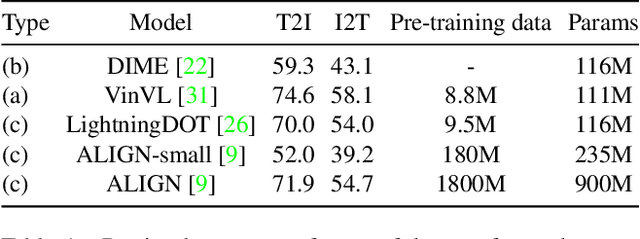
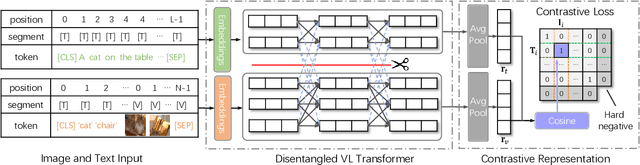
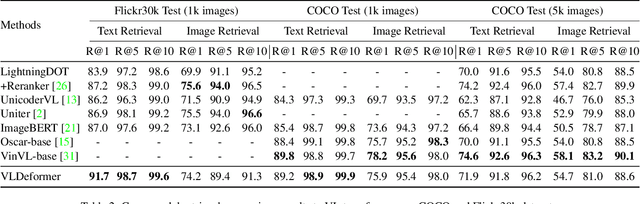
Vision-language transformers (VL transformers) have shown impressive accuracy in cross-modal retrieval. However, most of the existing VL transformers use early-interaction dataflow that computes a joint representation for the text-image input. In the retrieval stage, such models need to infer on all the matched text-image combinations, which causes high computing costs. The goal of this paper is to decompose the early-interaction dataflow inside the pre-trained VL transformer to achieve acceleration while maintaining its outstanding accuracy. To achieve this, we propose a novel Vision-language Transformer Decomposing (VLDeformer) to modify the VL transformer as an individual encoder for a single image or text through contrastive learning, which accelerates retrieval speed by thousands of times. Meanwhile, we propose to compose bi-modal hard negatives for the contrastive learning objective, which enables the VLDeformer to maintain the outstanding accuracy of the backbone VL transformer. Extensive experiments on COCO and Flickr30k datasets demonstrate the superior performance of the proposed method. Considering both effectiveness and efficiency, VLDeformer provides a superior selection for cross-modal retrieval in the similar pre-training datascale.
Multi-hop Graph Convolutional Network with High-order Chebyshev Approximation for Text Reasoning
Jun 08, 2021

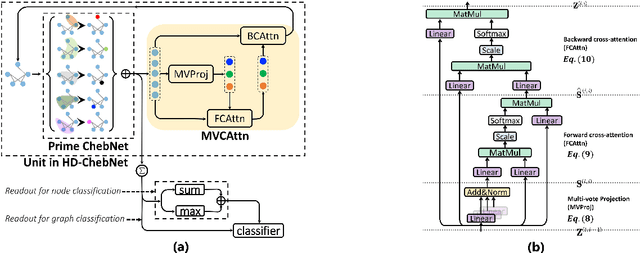
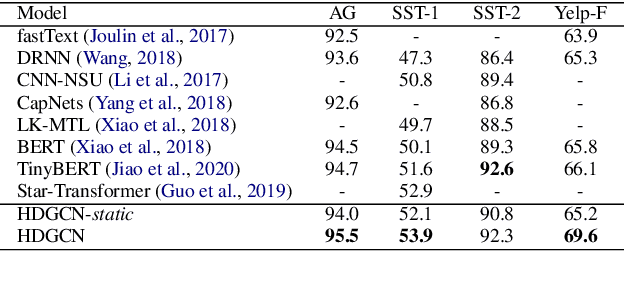
Graph convolutional network (GCN) has become popular in various natural language processing (NLP) tasks with its superiority in long-term and non-consecutive word interactions. However, existing single-hop graph reasoning in GCN may miss some important non-consecutive dependencies. In this study, we define the spectral graph convolutional network with the high-order dynamic Chebyshev approximation (HDGCN), which augments the multi-hop graph reasoning by fusing messages aggregated from direct and long-term dependencies into one convolutional layer. To alleviate the over-smoothing in high-order Chebyshev approximation, a multi-vote-based cross-attention (MVCAttn) with linear computation complexity is also proposed. The empirical results on four transductive and inductive NLP tasks and the ablation study verify the efficacy of the proposed model. Our source code is available at https://github.com/MathIsAll/HDGCN-pytorch.
Prototype Completion with Primitive Knowledge for Few-Shot Learning
Sep 12, 2020
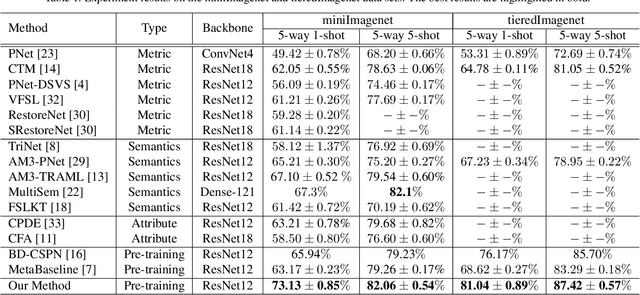
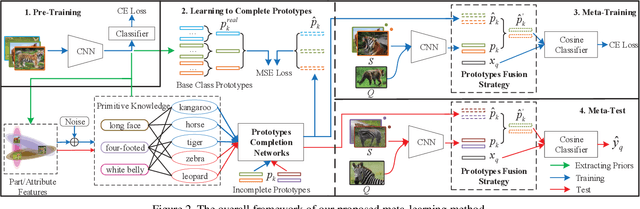
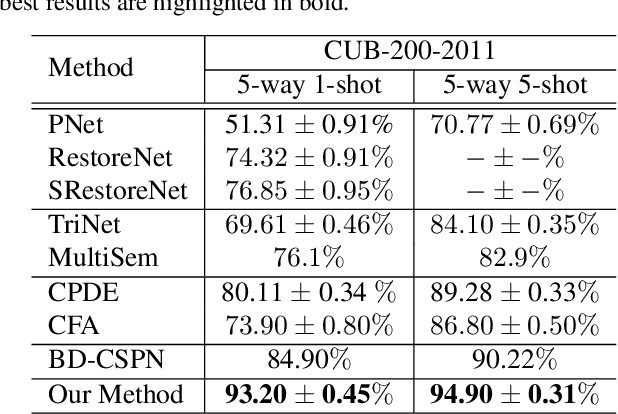
Few-shot learning is a challenging task, which aims to learn a classifier for novel classes with few labeled samples. Previous studies mainly focus on two-phase meta-learning methods. Recently, researchers find that introducing an extra pre-training phase can significantly improve the performance. The key idea is to learn a feature extractor with pre-training and then fine-tune it through the nearest centroid based meta-learning. However, results show that the fine-tuning step makes very marginal improvements. We thus argue that the current meta-learning scheme does not fully explore the power of the pre-training. The reason roots in the fact that in the pre-trained feature space, the base classes already form compact clusters while novel classes spread as groups with large variances. In this case, fine-tuning the feature extractor is less meaningful than estimating more representative prototypes. However, making such an estimation from few labeled samples is challenging because they may miss representative attribute features. In this paper, we propose a novel prototype completion based meta-learning framework. The framework first introduces primitive knowledge (i.e., class-level attribute or part annotations) and extracts representative attribute features as priors. A prototype completion network is then designed to learn to complement the missing attribute features with the priors. Finally, we develop a Gaussian based prototype fusion strategy to combine the mean-based and the complemented prototypes, which can effectively exploit the unlabeled samples. Extensive experimental results on three real-world data sets demonstrate that our method: (i) can obtain more accurate prototypes; (ii) outperforms state-of-the-art techniques by 2% - 9% on classification accuracy.
Neural Image Inpainting Guided with Descriptive Text
Apr 22, 2020
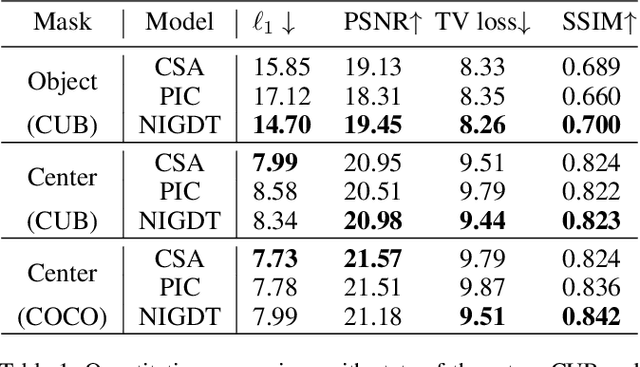
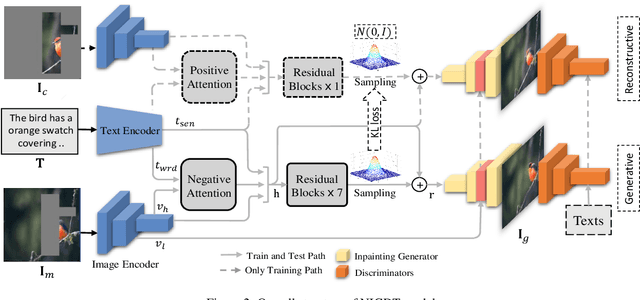
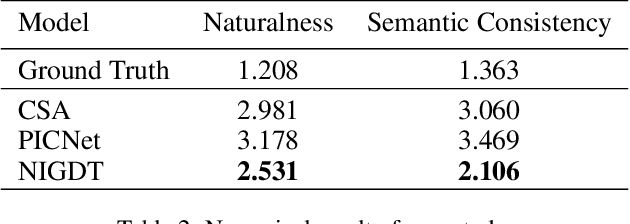
Neural image inpainting has achieved promising performance in generating semantically plausible content. Most of the recent works mainly focus on inpainting images depending on vision information, while neglecting the semantic information implied in human languages. To acquire more semantically accurate inpainting images, this paper proposes a novel inpainting model named \textit{N}eural \textit{I}mage Inpainting \textit{G}uided with \textit{D}escriptive \textit{T}ext (NIGDT). First, a dual multi-modal attention mechanism is designed to extract the explicit semantic information about corrupted regions. The mechanism is trained to combine the descriptive text and two complementary images through reciprocal attention maps. Second, an image-text matching loss is designed to enforce the model output following the descriptive text. Its goal is to maximize the semantic similarity of the generated image and the text. Finally, experiments are conducted on two open datasets with captions. Experimental results show that the proposed NIGDT model outperforms all compared models on both quantitative and qualitative comparison. The results also demonstrate that the proposed model can generate images consistent with the guidance text, which provides a flexible way for user-guided inpainting. Our systems and code will be released soon.
Integrate Image Representation to Text Model on Sentence Level: a Semi-supervised Framework
Dec 01, 2019

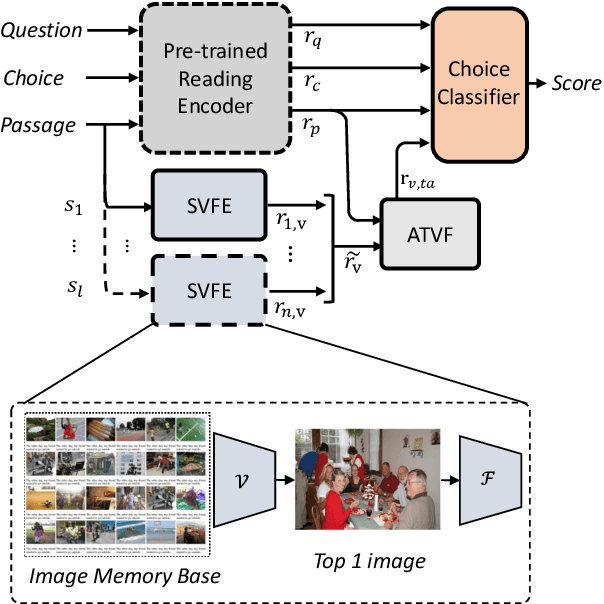

Integrating visual features has been proved useful in language representation learning. Nevertheless, in most existing multi-modality models, alignment of visual and textual data is prerequisite. In this paper, we propose a novel semi-supervised visual integration framework for sentence level language representation. The uniqueness include: 1) the integration is conducted via a semi-supervised approach, which can bring image to textual NLU tasks by pre-training a visualization network, 2) visual representations are dynamically integrated in both training and predicting stages. To verify the efficacy of the proposed framework, we conduct the experiments on the SemEval 2018 Task 11 and reach new state-of-the-art on this reading comprehension task. Considering that the visual integration framework only requires image database, and no extra alignment is required for training and prediction, it provides an efficient and feasible method for multi-modality language learning.