 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen Planning Fails Despite Correct Execution: On Epistemic Calibration for LLM-Based Multi-Agent Systems
May 22, 2026LLM-based multi-agent systems can fail even when planned actions are executed correctly because agents may misjudge their knowledge when evaluating plan feasibility, a phenomenon we term epistemic miscalibration in planning. Unlike execution errors, epistemic miscalibration is latent during planning, as generated plans can remain self-consistent and executable without observable errors; the miscalibration is also dynamic, as new information can alter feasibility assessments, potentially obscuring past miscalibration signals and causing them to recur over time. To address this, we propose the Epistemic Planning Calibration Agentic Workflow (EPC-AW), which assesses whether plans remain supported under varying information conditions rather than directly verifying feasibility. EPC-AW employs Information-consistency-based Plan Selection, selecting plans whose evaluations are stable across agents, together with Consistency-guided Epistemic State Refinement to adapt calibration over time by leveraging past discrepancies to guide future planning. Experiments show that EPC-AW improves system-level success by an average of 9.75%.
PaperScope: A Multi-Modal Multi-Document Benchmark for Agentic Deep Research Across Massive Scientific Papers
Apr 13, 2026Leveraging Multi-modal Large Language Models (MLLMs) to accelerate frontier scientific research is promising, yet how to rigorously evaluate such systems remains unclear. Existing benchmarks mainly focus on single-document understanding, whereas real scientific workflows require integrating evidence from multiple papers, including their text, tables, and figures. As a result, multi-modal, multi-document scientific reasoning remains underexplored and lacks systematic evaluation. To address this gap, we introduce PaperScope, a multi-modal multi-document benchmark designed for agentic deep research. PaperScope presents three advantages: (1) Structured scientific grounding. It is built on a knowledge graph of over 2,000 AI papers spanning three years, providing a structured foundation for research-oriented queries. (2) Semantically dense evidence construction. It integrates semantically related key information nodes and employs optimized random-walk article selector to sample thematically coherent paper sets, thereby ensuring adequate semantic density and task complexity. (3) Multi-task evaluation of scientific reasoning. It contains over 2,000 QA pairs across reasoning, retrieval, summarization, and problem solving, enabling evaluation of multi-step scientific reasoning. Experimental results show that even advanced systems such as OpenAI Deep Research and Tongyi Deep Research achieve limited scores on PaperScope, highlighting the difficulty of long-context retrieval and deep multi-source reasoning. PaperScope thus provides a rigorous benchmark alongside a scalable pipeline for constructing large-scale multi-modal, multi-source deep research datasets.
MemoBrain: Executive Memory as an Agentic Brain for Reasoning
Jan 12, 2026Complex reasoning in tool-augmented agent frameworks is inherently long-horizon, causing reasoning traces and transient tool artifacts to accumulate and strain the bounded working context of large language models. Without explicit memory mechanisms, such accumulation disrupts logical continuity and undermines task alignment. This positions memory not as an auxiliary efficiency concern, but as a core component for sustaining coherent, goal-directed reasoning over long horizons. We propose MemoBrain, an executive memory model for tool-augmented agents that constructs a dependency-aware memory over reasoning steps, capturing salient intermediate states and their logical relations. Operating as a co-pilot alongside the reasoning agent, MemoBrain organizes reasoning progress without blocking execution and actively manages the working context. Specifically, it prunes invalid steps, folds completed sub-trajectories, and preserves a compact, high-salience reasoning backbone under a fixed context budget. Together, these mechanisms enable explicit cognitive control over reasoning trajectories rather than passive context accumulation. We evaluate MemoBrain on challenging long-horizon benchmarks, including GAIA, WebWalker, and BrowseComp-Plus, demonstrating consistent improvements over strong baselines.
MomentSeeker: A Comprehensive Benchmark and A Strong Baseline For Moment Retrieval Within Long Videos
Feb 18, 2025Retrieval augmented generation (RAG) holds great promise in addressing challenges associated with long video understanding. These methods retrieve useful moments from long videos for their presented tasks, thereby enabling multimodal large language models (MLLMs) to generate high-quality answers in a cost-effective way. In this work, we present MomentSeeker, a comprehensive benchmark to evaluate retrieval models' performance in handling general long-video moment retrieval (LVMR) tasks. MomentSeeker offers three key advantages. First, it incorporates long videos of over 500 seconds on average, making it the first benchmark specialized for long-video moment retrieval. Second, it covers a wide range of task categories (including Moment Search, Caption Alignment, Image-conditioned Moment Search, and Video-conditioned Moment Search) and diverse application scenarios (e.g., sports, movies, cartoons, and ego), making it a comprehensive tool for assessing retrieval models' general LVMR performance. Additionally, the evaluation tasks are carefully curated through human annotation, ensuring the reliability of assessment. We further fine-tune an MLLM-based LVMR retriever on synthetic data, which demonstrates strong performance on our benchmark. We perform extensive experiments with various popular multimodal retrievers based on our benchmark, whose results highlight the challenges of LVMR and limitations for existing methods. Our created resources will be shared with community to advance future research in this field.
ICLEval: Evaluating In-Context Learning Ability of Large Language Models
Jun 21, 2024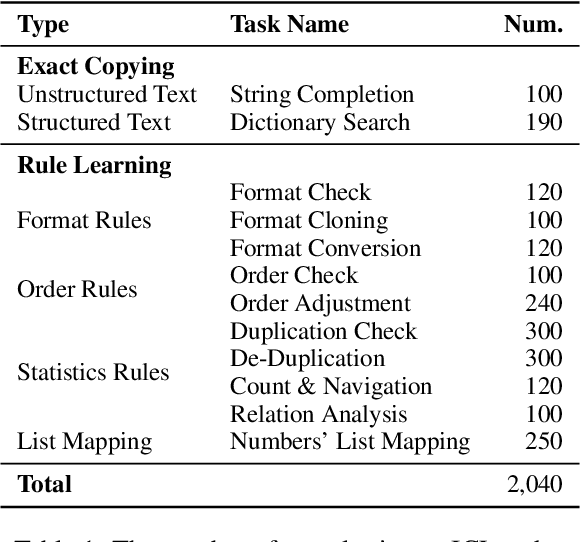
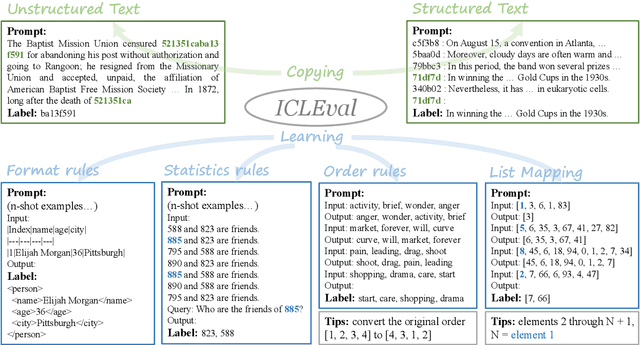
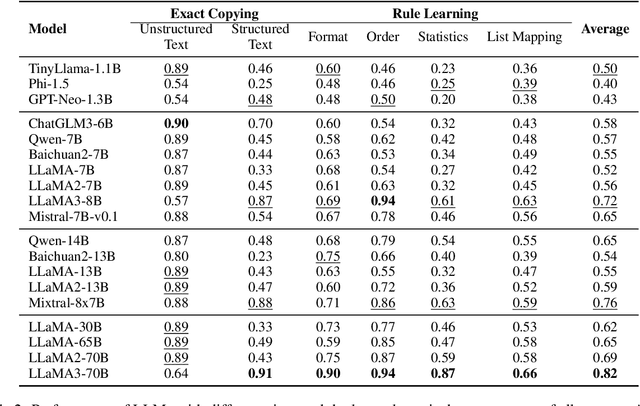
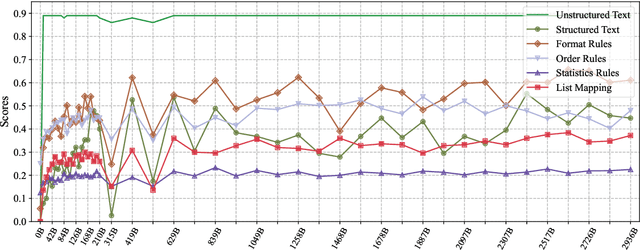
In-Context Learning (ICL) is a critical capability of Large Language Models (LLMs) as it empowers them to comprehend and reason across interconnected inputs. Evaluating the ICL ability of LLMs can enhance their utilization and deepen our understanding of how this ability is acquired at the training stage. However, existing evaluation frameworks primarily focus on language abilities and knowledge, often overlooking the assessment of ICL ability. In this work, we introduce the ICLEval benchmark to evaluate the ICL abilities of LLMs, which encompasses two key sub-abilities: exact copying and rule learning. Through the ICLEval benchmark, we demonstrate that ICL ability is universally present in different LLMs, and model size is not the sole determinant of ICL efficacy. Surprisingly, we observe that ICL abilities, particularly copying, develop early in the pretraining process and stabilize afterward. Our source codes and benchmark are released at https://github.com/yiye3/ICLEval.
An Analysis on Matching Mechanisms and Token Pruning for Late-interaction Models
Mar 20, 2024



With the development of pre-trained language models, the dense retrieval models have become promising alternatives to the traditional retrieval models that rely on exact match and sparse bag-of-words representations. Different from most dense retrieval models using a bi-encoder to encode each query or document into a dense vector, the recently proposed late-interaction multi-vector models (i.e., ColBERT and COIL) achieve state-of-the-art retrieval effectiveness by using all token embeddings to represent documents and queries and modeling their relevance with a sum-of-max operation. However, these fine-grained representations may cause unacceptable storage overhead for practical search systems. In this study, we systematically analyze the matching mechanism of these late-interaction models and show that the sum-of-max operation heavily relies on the co-occurrence signals and some important words in the document. Based on these findings, we then propose several simple document pruning methods to reduce the storage overhead and compare the effectiveness of different pruning methods on different late-interaction models. We also leverage query pruning methods to further reduce the retrieval latency. We conduct extensive experiments on both in-domain and out-domain datasets and show that some of the used pruning methods can significantly improve the efficiency of these late-interaction models without substantially hurting their retrieval effectiveness.
Argue with Me Tersely: Towards Sentence-Level Counter-Argument Generation
Dec 21, 2023



Counter-argument generation -- a captivating area in computational linguistics -- seeks to craft statements that offer opposing views. While most research has ventured into paragraph-level generation, sentence-level counter-argument generation beckons with its unique constraints and brevity-focused challenges. Furthermore, the diverse nature of counter-arguments poses challenges for evaluating model performance solely based on n-gram-based metrics. In this paper, we present the ArgTersely benchmark for sentence-level counter-argument generation, drawing from a manually annotated dataset from the ChangeMyView debate forum. We also propose Arg-LlaMA for generating high-quality counter-argument. For better evaluation, we trained a BERT-based evaluator Arg-Judge with human preference data. We conducted comparative experiments involving various baselines such as LlaMA, Alpaca, GPT-3, and others. The results show the competitiveness of our proposed framework and evaluator in counter-argument generation tasks. Code and data are available at https://github.com/amazingljy1206/ArgTersely.
Hi-ArG: Exploring the Integration of Hierarchical Argumentation Graphs in Language Pretraining
Dec 01, 2023



The knowledge graph is a structure to store and represent knowledge, and recent studies have discussed its capability to assist language models for various applications. Some variations of knowledge graphs aim to record arguments and their relations for computational argumentation tasks. However, many must simplify semantic types to fit specific schemas, thus losing flexibility and expression ability. In this paper, we propose the Hierarchical Argumentation Graph (Hi-ArG), a new structure to organize arguments. We also introduce two approaches to exploit Hi-ArG, including a text-graph multi-modal model GreaseArG and a new pre-training framework augmented with graph information. Experiments on two argumentation tasks have shown that after further pre-training and fine-tuning, GreaseArG supersedes same-scale language models on these tasks, while incorporating graph information during further pre-training can also improve the performance of vanilla language models. Code for this paper is available at https://github.com/ljcleo/Hi-ArG .
IAG: Induction-Augmented Generation Framework for Answering Reasoning Questions
Nov 30, 2023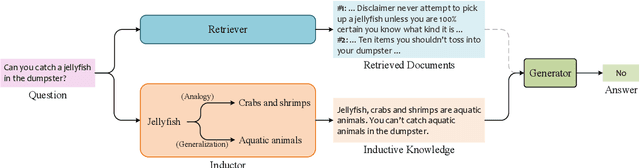
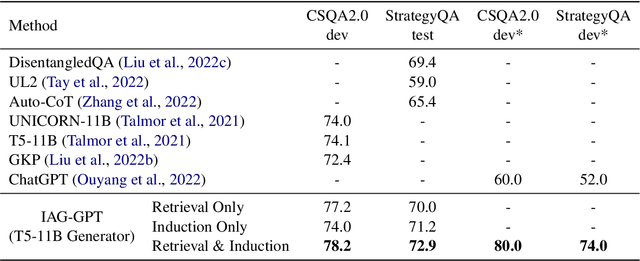
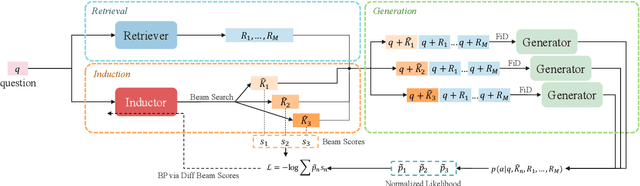
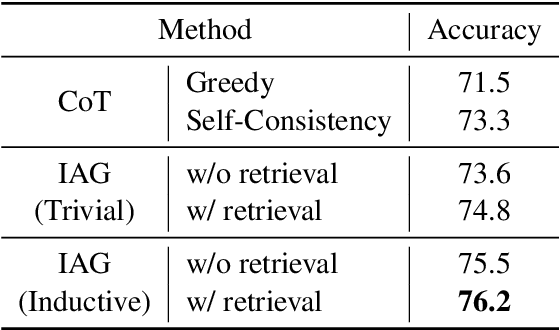
Retrieval-Augmented Generation (RAG), by incorporating external knowledge with parametric memory of language models, has become the state-of-the-art architecture for open-domain QA tasks. However, common knowledge bases are inherently constrained by limited coverage and noisy information, making retrieval-based approaches inadequate to answer implicit reasoning questions. In this paper, we propose an Induction-Augmented Generation (IAG) framework that utilizes inductive knowledge along with the retrieved documents for implicit reasoning. We leverage large language models (LLMs) for deriving such knowledge via a novel prompting method based on inductive reasoning patterns. On top of this, we implement two versions of IAG named IAG-GPT and IAG-Student, respectively. IAG-GPT directly utilizes the knowledge generated by GPT-3 for answer prediction, while IAG-Student gets rid of dependencies on GPT service at inference time by incorporating a student inductor model. The inductor is firstly trained via knowledge distillation and further optimized by back-propagating the generator feedback via differentiable beam scores. Experimental results show that IAG outperforms RAG baselines as well as ChatGPT on two Open-Domain QA tasks. Notably, our best models have won the first place in the official leaderboards of CSQA2.0 (since Nov 1, 2022) and StrategyQA (since Jan 8, 2023).
UFIN: Universal Feature Interaction Network for Multi-Domain Click-Through Rate Prediction
Nov 27, 2023

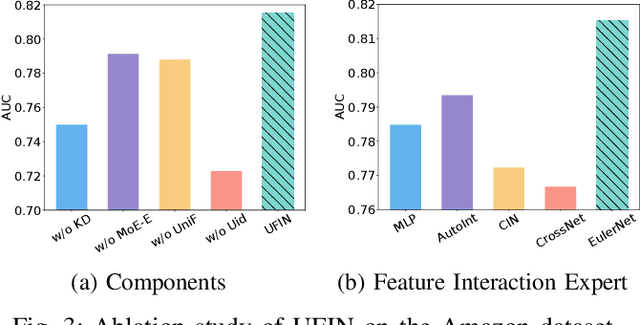

Click-Through Rate (CTR) prediction, which aims to estimate the probability of a user clicking on an item, is a key task in online advertising. Numerous existing CTR models concentrate on modeling the feature interactions within a solitary domain, thereby rendering them inadequate for fulfilling the requisites of multi-domain recommendations in real industrial scenarios. Some recent approaches propose intricate architectures to enhance knowledge sharing and augment model training across multiple domains. However, these approaches encounter difficulties when being transferred to new recommendation domains, owing to their reliance on the modeling of ID features (e.g., item id). To address the above issue, we propose the Universal Feature Interaction Network (UFIN) approach for CTR prediction. UFIN exploits textual data to learn universal feature interactions that can be effectively transferred across diverse domains. For learning universal feature representations, we regard the text and feature as two different modalities and propose an encoder-decoder network founded on a Large Language Model (LLM) to enforce the transfer of data from the text modality to the feature modality. Building upon the above foundation, we further develop a mixtureof-experts (MoE) enhanced adaptive feature interaction model to learn transferable collaborative patterns across multiple domains. Furthermore, we propose a multi-domain knowledge distillation framework to enhance feature interaction learning. Based on the above methods, UFIN can effectively bridge the semantic gap to learn common knowledge across various domains, surpassing the constraints of ID-based models. Extensive experiments conducted on eight datasets show the effectiveness of UFIN, in both multidomain and cross-platform settings. Our code is available at https://github.com/RUCAIBox/UFIN.