 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuro-Symbolic Query Compiler
May 17, 2025Precise recognition of search intent in Retrieval-Augmented Generation (RAG) systems remains a challenging goal, especially under resource constraints and for complex queries with nested structures and dependencies. This paper presents QCompiler, a neuro-symbolic framework inspired by linguistic grammar rules and compiler design, to bridge this gap. It theoretically designs a minimal yet sufficient Backus-Naur Form (BNF) grammar $G[q]$ to formalize complex queries. Unlike previous methods, this grammar maintains completeness while minimizing redundancy. Based on this, QCompiler includes a Query Expression Translator, a Lexical Syntax Parser, and a Recursive Descent Processor to compile queries into Abstract Syntax Trees (ASTs) for execution. The atomicity of the sub-queries in the leaf nodes ensures more precise document retrieval and response generation, significantly improving the RAG system's ability to address complex queries.
Hierarchical Document Refinement for Long-context Retrieval-augmented Generation
May 15, 2025Real-world RAG applications often encounter long-context input scenarios, where redundant information and noise results in higher inference costs and reduced performance. To address these challenges, we propose LongRefiner, an efficient plug-and-play refiner that leverages the inherent structural characteristics of long documents. LongRefiner employs dual-level query analysis, hierarchical document structuring, and adaptive refinement through multi-task learning on a single foundation model. Experiments on seven QA datasets demonstrate that LongRefiner achieves competitive performance in various scenarios while using 10x fewer computational costs and latency compared to the best baseline. Further analysis validates that LongRefiner is scalable, efficient, and effective, providing practical insights for real-world long-text RAG applications. Our code is available at https://github.com/ignorejjj/LongRefiner.
WebThinker: Empowering Large Reasoning Models with Deep Research Capability
Apr 30, 2025Large reasoning models (LRMs), such as OpenAI-o1 and DeepSeek-R1, demonstrate impressive long-horizon reasoning capabilities. However, their reliance on static internal knowledge limits their performance on complex, knowledge-intensive tasks and hinders their ability to produce comprehensive research reports requiring synthesis of diverse web information. To address this, we propose \textbf{WebThinker}, a deep research agent that empowers LRMs to autonomously search the web, navigate web pages, and draft research reports during the reasoning process. WebThinker integrates a \textbf{Deep Web Explorer} module, enabling LRMs to dynamically search, navigate, and extract information from the web when encountering knowledge gaps. It also employs an \textbf{Autonomous Think-Search-and-Draft strategy}, allowing the model to seamlessly interleave reasoning, information gathering, and report writing in real time. To further enhance research tool utilization, we introduce an \textbf{RL-based training strategy} via iterative online Direct Preference Optimization (DPO). Extensive experiments on complex reasoning benchmarks (GPQA, GAIA, WebWalkerQA, HLE) and scientific report generation tasks (Glaive) demonstrate that WebThinker significantly outperforms existing methods and strong proprietary systems. Our approach enhances LRM reliability and applicability in complex scenarios, paving the way for more capable and versatile deep research systems. The code is available at https://github.com/RUC-NLPIR/WebThinker.
RetroLLM: Empowering Large Language Models to Retrieve Fine-grained Evidence within Generation
Dec 16, 2024



Large language models (LLMs) exhibit remarkable generative capabilities but often suffer from hallucinations. Retrieval-augmented generation (RAG) offers an effective solution by incorporating external knowledge, but existing methods still face several limitations: additional deployment costs of separate retrievers, redundant input tokens from retrieved text chunks, and the lack of joint optimization of retrieval and generation. To address these issues, we propose \textbf{RetroLLM}, a unified framework that integrates retrieval and generation into a single, cohesive process, enabling LLMs to directly generate fine-grained evidence from the corpus with constrained decoding. Moreover, to mitigate false pruning in the process of constrained evidence generation, we introduce (1) hierarchical FM-Index constraints, which generate corpus-constrained clues to identify a subset of relevant documents before evidence generation, reducing irrelevant decoding space; and (2) a forward-looking constrained decoding strategy, which considers the relevance of future sequences to improve evidence accuracy. Extensive experiments on five open-domain QA datasets demonstrate RetroLLM's superior performance across both in-domain and out-of-domain tasks. The code is available at \url{https://github.com/sunnynexus/RetroLLM}.
CORAL: Benchmarking Multi-turn Conversational Retrieval-Augmentation Generation
Oct 30, 2024



Retrieval-Augmented Generation (RAG) has become a powerful paradigm for enhancing large language models (LLMs) through external knowledge retrieval. Despite its widespread attention, existing academic research predominantly focuses on single-turn RAG, leaving a significant gap in addressing the complexities of multi-turn conversations found in real-world applications. To bridge this gap, we introduce CORAL, a large-scale benchmark designed to assess RAG systems in realistic multi-turn conversational settings. CORAL includes diverse information-seeking conversations automatically derived from Wikipedia and tackles key challenges such as open-domain coverage, knowledge intensity, free-form responses, and topic shifts. It supports three core tasks of conversational RAG: passage retrieval, response generation, and citation labeling. We propose a unified framework to standardize various conversational RAG methods and conduct a comprehensive evaluation of these methods on CORAL, demonstrating substantial opportunities for improving existing approaches.
IAG: Induction-Augmented Generation Framework for Answering Reasoning Questions
Nov 30, 2023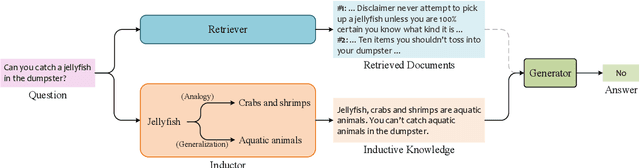
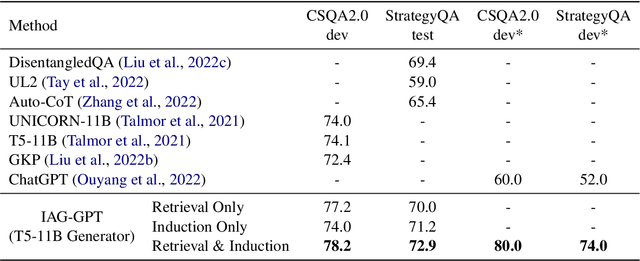
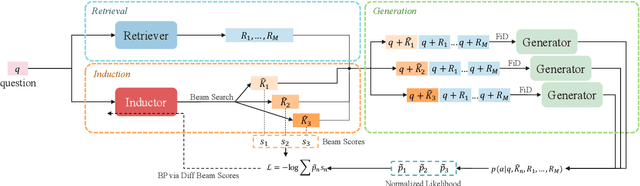
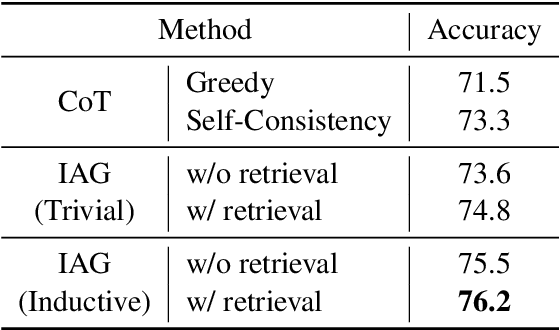
Retrieval-Augmented Generation (RAG), by incorporating external knowledge with parametric memory of language models, has become the state-of-the-art architecture for open-domain QA tasks. However, common knowledge bases are inherently constrained by limited coverage and noisy information, making retrieval-based approaches inadequate to answer implicit reasoning questions. In this paper, we propose an Induction-Augmented Generation (IAG) framework that utilizes inductive knowledge along with the retrieved documents for implicit reasoning. We leverage large language models (LLMs) for deriving such knowledge via a novel prompting method based on inductive reasoning patterns. On top of this, we implement two versions of IAG named IAG-GPT and IAG-Student, respectively. IAG-GPT directly utilizes the knowledge generated by GPT-3 for answer prediction, while IAG-Student gets rid of dependencies on GPT service at inference time by incorporating a student inductor model. The inductor is firstly trained via knowledge distillation and further optimized by back-propagating the generator feedback via differentiable beam scores. Experimental results show that IAG outperforms RAG baselines as well as ChatGPT on two Open-Domain QA tasks. Notably, our best models have won the first place in the official leaderboards of CSQA2.0 (since Nov 1, 2022) and StrategyQA (since Jan 8, 2023).
Zero-Shot Continuous Prompt Transfer: Generalizing Task Semantics Across Language Models
Oct 02, 2023



Prompt tuning in natural language processing (NLP) has become an increasingly popular method for adapting large language models to specific tasks. However, the transferability of these prompts, especially continuous prompts, between different models remains a challenge. In this work, we propose a zero-shot continuous prompt transfer method, where source prompts are encoded into relative space and the corresponding target prompts are searched for transferring to target models. Experimental results confirm the effectiveness of our method, showing that 'task semantics' in continuous prompts can be generalized across various language models. Moreover, we find that combining 'task semantics' from multiple source models can further enhance the generalizability of transfer.
Unsupervised Chunking with Hierarchical RNN
Sep 10, 2023



In Natural Language Processing (NLP), predicting linguistic structures, such as parsing and chunking, has mostly relied on manual annotations of syntactic structures. This paper introduces an unsupervised approach to chunking, a syntactic task that involves grouping words in a non-hierarchical manner. We present a two-layer Hierarchical Recurrent Neural Network (HRNN) designed to model word-to-chunk and chunk-to-sentence compositions. Our approach involves a two-stage training process: pretraining with an unsupervised parser and finetuning on downstream NLP tasks. Experiments on the CoNLL-2000 dataset reveal a notable improvement over existing unsupervised methods, enhancing phrase F1 score by up to 6 percentage points. Further, finetuning with downstream tasks results in an additional performance improvement. Interestingly, we observe that the emergence of the chunking structure is transient during the neural model's downstream-task training. This study contributes to the advancement of unsupervised syntactic structure discovery and opens avenues for further research in linguistic theory.
Pre-training for Information Retrieval: Are Hyperlinks Fully Explored?
Sep 14, 2022
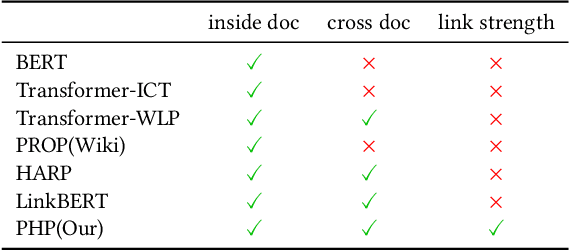
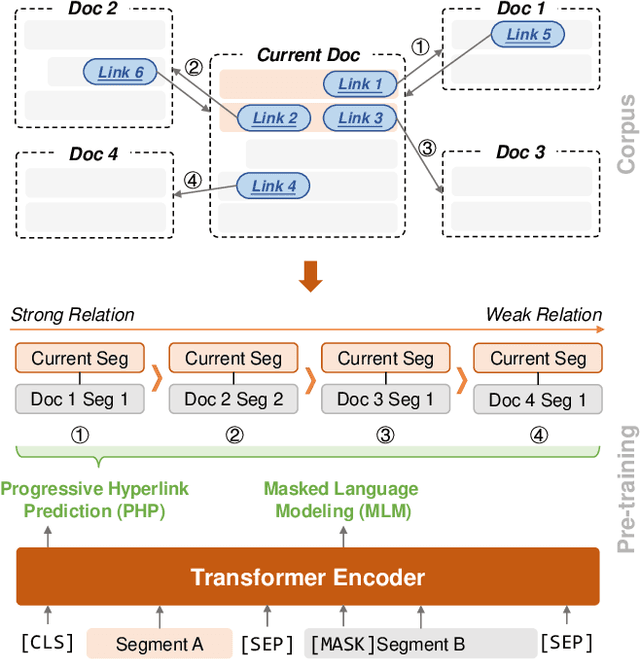
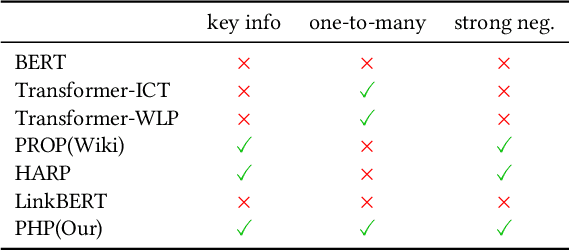
Recent years have witnessed great progress on applying pre-trained language models, e.g., BERT, to information retrieval (IR) tasks. Hyperlinks, which are commonly used in Web pages, have been leveraged for designing pre-training objectives. For example, anchor texts of the hyperlinks have been used for simulating queries, thus constructing tremendous query-document pairs for pre-training. However, as a bridge across two web pages, the potential of hyperlinks has not been fully explored. In this work, we focus on modeling the relationship between two documents that are connected by hyperlinks and designing a new pre-training objective for ad-hoc retrieval. Specifically, we categorize the relationships between documents into four groups: no link, unidirectional link, symmetric link, and the most relevant symmetric link. By comparing two documents sampled from adjacent groups, the model can gradually improve its capability of capturing matching signals. We propose a progressive hyperlink predication ({PHP}) framework to explore the utilization of hyperlinks in pre-training. Experimental results on two large-scale ad-hoc retrieval datasets and six question-answering datasets demonstrate its superiority over existing pre-training methods.
Coarse-to-Fine: Hierarchical Multi-task Learning for Natural Language Understanding
Aug 19, 2022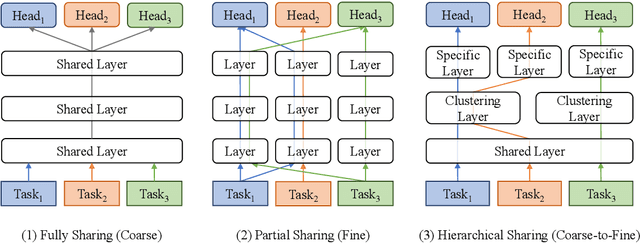
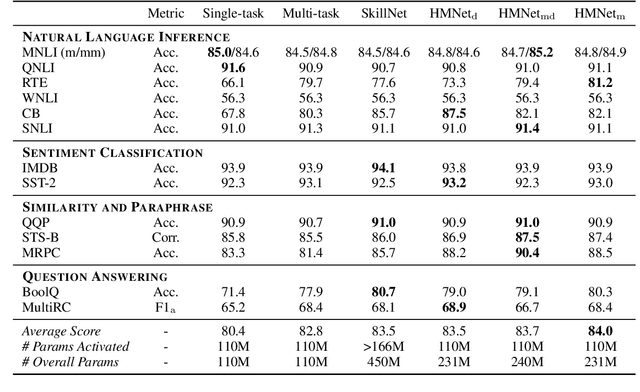
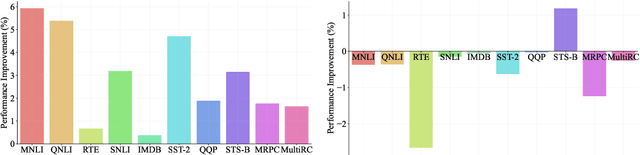
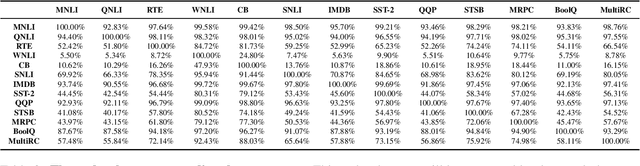
Generalized text representations are the foundation of many natural language understanding tasks. To fully utilize the different corpus, it is inevitable that models need to understand the relevance among them. However, many methods ignore the relevance and adopt a single-channel model (a coarse paradigm) directly for all tasks, which lacks enough rationality and interpretation. In addition, some existing works learn downstream tasks by stitches skill block(a fine paradigm), which might cause irrationalresults due to its redundancy and noise. Inthis work, we first analyze the task correlation through three different perspectives, i.e., data property, manual design, and model-based relevance, based on which the similar tasks are grouped together. Then, we propose a hierarchical framework with a coarse-to-fine paradigm, with the bottom level shared to all the tasks, the mid-level divided to different groups, and the top-level assigned to each of the tasks. This allows our model to learn basic language properties from all tasks, boost performance on relevant tasks, and reduce the negative impact from irrelevant tasks. Our experiments on 13 benchmark datasets across five natural language understanding tasks demonstrate the superiority of our method.