 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Extensive Evaluation of PDDL Capabilities in off-the-shelf LLMs
Feb 27, 2025


In recent advancements, large language models (LLMs) have exhibited proficiency in code generation and chain-of-thought reasoning, laying the groundwork for tackling automatic formal planning tasks. This study evaluates the potential of LLMs to understand and generate Planning Domain Definition Language (PDDL), an essential representation in artificial intelligence planning. We conduct an extensive analysis across 20 distinct models spanning 7 major LLM families, both commercial and open-source. Our comprehensive evaluation sheds light on the zero-shot LLM capabilities of parsing, generating, and reasoning with PDDL. Our findings indicate that while some models demonstrate notable effectiveness in handling PDDL, others pose limitations in more complex scenarios requiring nuanced planning knowledge. These results highlight the promise and current limitations of LLMs in formal planning tasks, offering insights into their application and guiding future efforts in AI-driven planning paradigms.
GeAR: Graph-enhanced Agent for Retrieval-augmented Generation
Dec 24, 2024Retrieval-augmented generation systems rely on effective document retrieval capabilities. By design, conventional sparse or dense retrievers face challenges in multi-hop retrieval scenarios. In this paper, we present GeAR, which advances RAG performance through two key innovations: (i) graph expansion, which enhances any conventional base retriever, such as BM25, and (ii) an agent framework that incorporates graph expansion. Our evaluation demonstrates GeAR's superior retrieval performance on three multi-hop question answering datasets. Additionally, our system achieves state-of-the-art results with improvements exceeding 10% on the challenging MuSiQue dataset, while requiring fewer tokens and iterations compared to other multi-step retrieval systems.
From An LLM Swarm To A PDDL-Empowered HIVE: Planning Self-Executed Instructions In A Multi-Modal Jungle
Dec 17, 2024



In response to the call for agent-based solutions that leverage the ever-increasing capabilities of the deep models' ecosystem, we introduce Hive -- a comprehensive solution for selecting appropriate models and subsequently planning a set of atomic actions to satisfy the end-users' instructions. Hive operates over sets of models and, upon receiving natural language instructions (i.e. user queries), schedules and executes explainable plans of atomic actions. These actions can involve one or more of the available models to achieve the overall task, while respecting end-users specific constraints. Notably, Hive handles tasks that involve multi-modal inputs and outputs, enabling it to handle complex, real-world queries. Our system is capable of planning complex chains of actions while guaranteeing explainability, using an LLM-based formal logic backbone empowered by PDDL operations. We introduce the MuSE benchmark in order to offer a comprehensive evaluation of the multi-modal capabilities of agent systems. Our findings show that our framework redefines the state-of-the-art for task selection, outperforming other competing systems that plan operations across multiple models while offering transparency guarantees while fully adhering to user constraints.
Debatrix: Multi-dimensinal Debate Judge with Iterative Chronological Analysis Based on LLM
Mar 12, 2024



How can we construct an automated debate judge to evaluate an extensive, vibrant, multi-turn debate? This task is challenging, as judging a debate involves grappling with lengthy texts, intricate argument relationships, and multi-dimensional assessments. At the same time, current research mainly focuses on short dialogues, rarely touching upon the evaluation of an entire debate. In this paper, by leveraging Large Language Models (LLMs), we propose Debatrix, which makes the analysis and assessment of multi-turn debates more aligned with majority preferences. Specifically, Debatrix features a vertical, iterative chronological analysis and a horizontal, multi-dimensional evaluation collaboration. To align with real-world debate scenarios, we introduced the PanelBench benchmark, comparing our system's performance to actual debate outcomes. The findings indicate a notable enhancement over directly using LLMs for debate evaluation. Source code and benchmark data are available online at https://github.com/ljcleo/Debatrix .
Argue with Me Tersely: Towards Sentence-Level Counter-Argument Generation
Dec 21, 2023



Counter-argument generation -- a captivating area in computational linguistics -- seeks to craft statements that offer opposing views. While most research has ventured into paragraph-level generation, sentence-level counter-argument generation beckons with its unique constraints and brevity-focused challenges. Furthermore, the diverse nature of counter-arguments poses challenges for evaluating model performance solely based on n-gram-based metrics. In this paper, we present the ArgTersely benchmark for sentence-level counter-argument generation, drawing from a manually annotated dataset from the ChangeMyView debate forum. We also propose Arg-LlaMA for generating high-quality counter-argument. For better evaluation, we trained a BERT-based evaluator Arg-Judge with human preference data. We conducted comparative experiments involving various baselines such as LlaMA, Alpaca, GPT-3, and others. The results show the competitiveness of our proposed framework and evaluator in counter-argument generation tasks. Code and data are available at https://github.com/amazingljy1206/ArgTersely.
Hi-ArG: Exploring the Integration of Hierarchical Argumentation Graphs in Language Pretraining
Dec 01, 2023



The knowledge graph is a structure to store and represent knowledge, and recent studies have discussed its capability to assist language models for various applications. Some variations of knowledge graphs aim to record arguments and their relations for computational argumentation tasks. However, many must simplify semantic types to fit specific schemas, thus losing flexibility and expression ability. In this paper, we propose the Hierarchical Argumentation Graph (Hi-ArG), a new structure to organize arguments. We also introduce two approaches to exploit Hi-ArG, including a text-graph multi-modal model GreaseArG and a new pre-training framework augmented with graph information. Experiments on two argumentation tasks have shown that after further pre-training and fine-tuning, GreaseArG supersedes same-scale language models on these tasks, while incorporating graph information during further pre-training can also improve the performance of vanilla language models. Code for this paper is available at https://github.com/ljcleo/Hi-ArG .
IAG: Induction-Augmented Generation Framework for Answering Reasoning Questions
Nov 30, 2023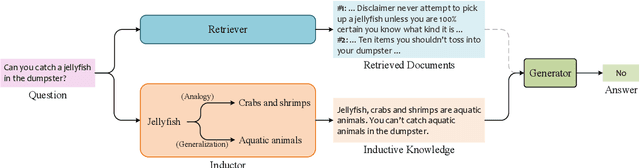
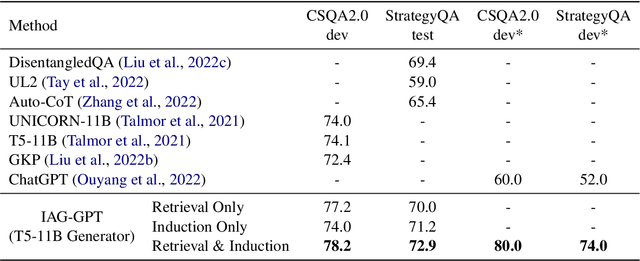
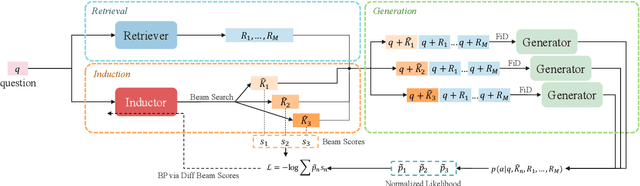
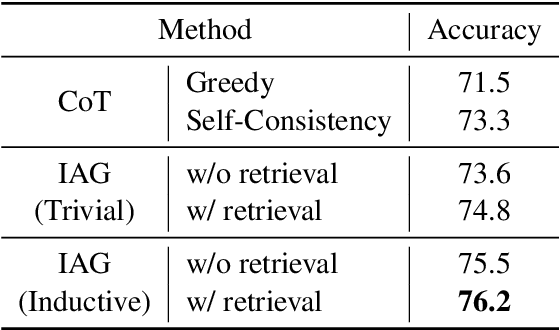
Retrieval-Augmented Generation (RAG), by incorporating external knowledge with parametric memory of language models, has become the state-of-the-art architecture for open-domain QA tasks. However, common knowledge bases are inherently constrained by limited coverage and noisy information, making retrieval-based approaches inadequate to answer implicit reasoning questions. In this paper, we propose an Induction-Augmented Generation (IAG) framework that utilizes inductive knowledge along with the retrieved documents for implicit reasoning. We leverage large language models (LLMs) for deriving such knowledge via a novel prompting method based on inductive reasoning patterns. On top of this, we implement two versions of IAG named IAG-GPT and IAG-Student, respectively. IAG-GPT directly utilizes the knowledge generated by GPT-3 for answer prediction, while IAG-Student gets rid of dependencies on GPT service at inference time by incorporating a student inductor model. The inductor is firstly trained via knowledge distillation and further optimized by back-propagating the generator feedback via differentiable beam scores. Experimental results show that IAG outperforms RAG baselines as well as ChatGPT on two Open-Domain QA tasks. Notably, our best models have won the first place in the official leaderboards of CSQA2.0 (since Nov 1, 2022) and StrategyQA (since Jan 8, 2023).
Optimizing Factual Accuracy in Text Generation through Dynamic Knowledge Selection
Aug 30, 2023
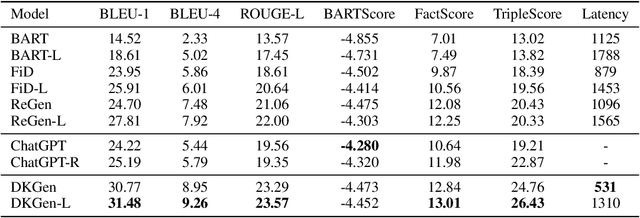
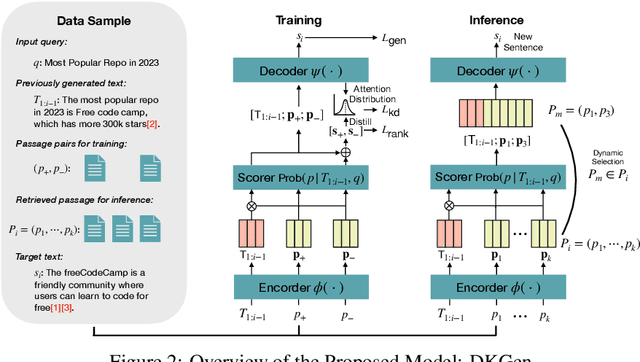
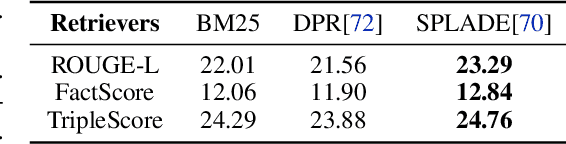
Language models (LMs) have revolutionized the way we interact with information, but they often generate nonfactual text, raising concerns about their reliability. Previous methods use external knowledge as references for text generation to enhance factuality but often struggle with the knowledge mix-up(e.g., entity mismatch) of irrelevant references. Besides,as the length of the output text grows, the randomness of sampling can escalate, detrimentally impacting the factual accuracy of the generated text. In this paper, we present DKGen, which divide the text generation process into an iterative process. In each iteration, DKGen takes the input query, the previously generated text and a subset of the reference passages as input to generate short text. During the process, the subset is dynamically selected from the full passage set based on their relevance to the previously generated text and the query, largely eliminating the irrelevant references from input. To further enhance DKGen's ability to correctly use these external knowledge, DKGen distills the relevance order of reference passages to the cross-attention distribution of decoder. We train and evaluate DKGen on a large-scale benchmark dataset. Experiment results show that DKGen outperforms all baseline models.
WebBrain: Learning to Generate Factually Correct Articles for Queries by Grounding on Large Web Corpus
Apr 10, 2023



In this paper, we introduce a new NLP task -- generating short factual articles with references for queries by mining supporting evidence from the Web. In this task, called WebBrain, the ultimate goal is to generate a fluent, informative, and factually-correct short article (e.g., a Wikipedia article) for a factual query unseen in Wikipedia. To enable experiments on WebBrain, we construct a large-scale dataset WebBrain-Raw by extracting English Wikipedia articles and their crawlable Wikipedia references. WebBrain-Raw is ten times larger than the previous biggest peer dataset, which can greatly benefit the research community. From WebBrain-Raw, we construct two task-specific datasets: WebBrain-R and WebBrain-G, which are used to train in-domain retriever and generator, respectively. Besides, we empirically analyze the performances of the current state-of-the-art NLP techniques on WebBrain and introduce a new framework ReGen, which enhances the generation factualness by improved evidence retrieval and task-specific pre-training for generation. Experiment results show that ReGen outperforms all baselines in both automatic and human evaluations.
Pre-training for Information Retrieval: Are Hyperlinks Fully Explored?
Sep 14, 2022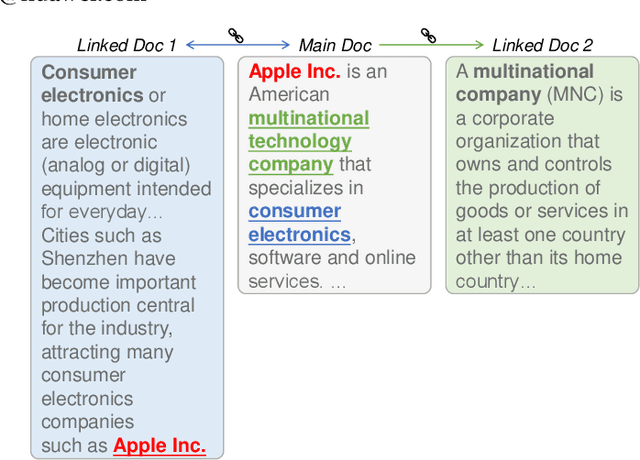
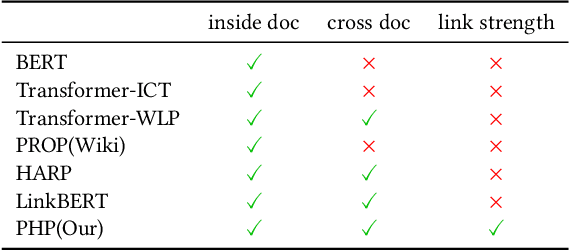
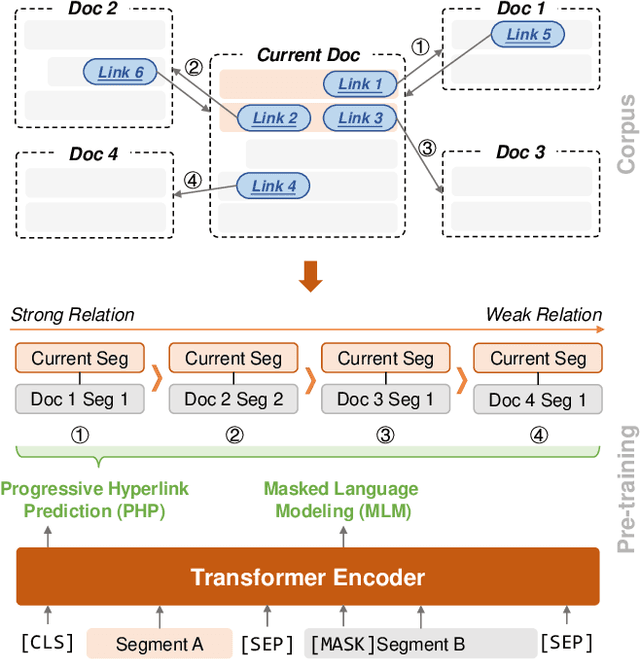
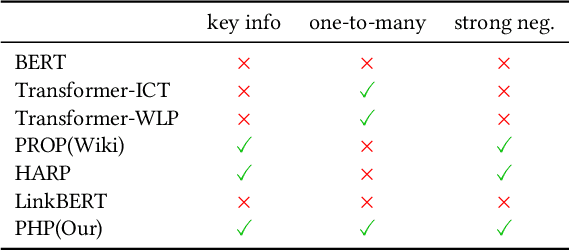
Recent years have witnessed great progress on applying pre-trained language models, e.g., BERT, to information retrieval (IR) tasks. Hyperlinks, which are commonly used in Web pages, have been leveraged for designing pre-training objectives. For example, anchor texts of the hyperlinks have been used for simulating queries, thus constructing tremendous query-document pairs for pre-training. However, as a bridge across two web pages, the potential of hyperlinks has not been fully explored. In this work, we focus on modeling the relationship between two documents that are connected by hyperlinks and designing a new pre-training objective for ad-hoc retrieval. Specifically, we categorize the relationships between documents into four groups: no link, unidirectional link, symmetric link, and the most relevant symmetric link. By comparing two documents sampled from adjacent groups, the model can gradually improve its capability of capturing matching signals. We propose a progressive hyperlink predication ({PHP}) framework to explore the utilization of hyperlinks in pre-training. Experimental results on two large-scale ad-hoc retrieval datasets and six question-answering datasets demonstrate its superiority over existing pre-training methods.