 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHRIPBench: Benchmarking LLMs in Harm Reduction Information Provision to Support People Who Use Drugs
Jul 29, 2025Millions of individuals' well-being are challenged by the harms of substance use. Harm reduction as a public health strategy is designed to improve their health outcomes and reduce safety risks. Some large language models (LLMs) have demonstrated a decent level of medical knowledge, promising to address the information needs of people who use drugs (PWUD). However, their performance in relevant tasks remains largely unexplored. We introduce HRIPBench, a benchmark designed to evaluate LLM's accuracy and safety risks in harm reduction information provision. The benchmark dataset HRIP-Basic has 2,160 question-answer-evidence pairs. The scope covers three tasks: checking safety boundaries, providing quantitative values, and inferring polysubstance use risks. We build the Instruction and RAG schemes to evaluate model behaviours based on their inherent knowledge and the integration of domain knowledge. Our results indicate that state-of-the-art LLMs still struggle to provide accurate harm reduction information, and sometimes, carry out severe safety risks to PWUD. The use of LLMs in harm reduction contexts should be cautiously constrained to avoid inducing negative health outcomes. WARNING: This paper contains illicit content that potentially induces harms.
Millions of $\text{GeAR}$-s: Extending GraphRAG to Millions of Documents
Jul 23, 2025Recent studies have explored graph-based approaches to retrieval-augmented generation, leveraging structured or semi-structured information -- such as entities and their relations extracted from documents -- to enhance retrieval. However, these methods are typically designed to address specific tasks, such as multi-hop question answering and query-focused summarisation, and therefore, there is limited evidence of their general applicability across broader datasets. In this paper, we aim to adapt a state-of-the-art graph-based RAG solution: $\text{GeAR}$ and explore its performance and limitations on the SIGIR 2025 LiveRAG Challenge.
GeAR: Graph-enhanced Agent for Retrieval-augmented Generation
Dec 24, 2024Retrieval-augmented generation systems rely on effective document retrieval capabilities. By design, conventional sparse or dense retrievers face challenges in multi-hop retrieval scenarios. In this paper, we present GeAR, which advances RAG performance through two key innovations: (i) graph expansion, which enhances any conventional base retriever, such as BM25, and (ii) an agent framework that incorporates graph expansion. Our evaluation demonstrates GeAR's superior retrieval performance on three multi-hop question answering datasets. Additionally, our system achieves state-of-the-art results with improvements exceeding 10% on the challenging MuSiQue dataset, while requiring fewer tokens and iterations compared to other multi-step retrieval systems.
From An LLM Swarm To A PDDL-Empowered HIVE: Planning Self-Executed Instructions In A Multi-Modal Jungle
Dec 17, 2024



In response to the call for agent-based solutions that leverage the ever-increasing capabilities of the deep models' ecosystem, we introduce Hive -- a comprehensive solution for selecting appropriate models and subsequently planning a set of atomic actions to satisfy the end-users' instructions. Hive operates over sets of models and, upon receiving natural language instructions (i.e. user queries), schedules and executes explainable plans of atomic actions. These actions can involve one or more of the available models to achieve the overall task, while respecting end-users specific constraints. Notably, Hive handles tasks that involve multi-modal inputs and outputs, enabling it to handle complex, real-world queries. Our system is capable of planning complex chains of actions while guaranteeing explainability, using an LLM-based formal logic backbone empowered by PDDL operations. We introduce the MuSE benchmark in order to offer a comprehensive evaluation of the multi-modal capabilities of agent systems. Our findings show that our framework redefines the state-of-the-art for task selection, outperforming other competing systems that plan operations across multiple models while offering transparency guarantees while fully adhering to user constraints.
Improving Retrieval-augmented Text-to-SQL with AST-based Ranking and Schema Pruning
Jul 03, 2024

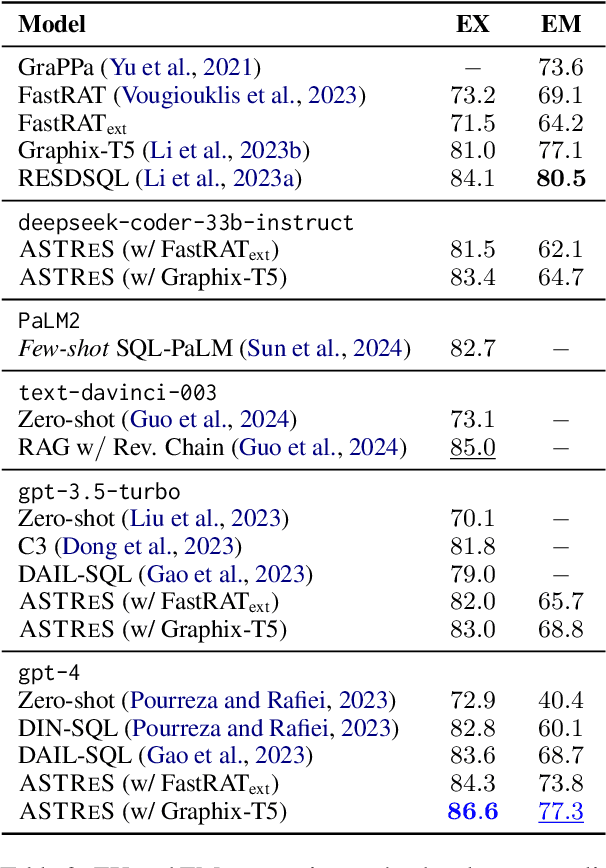

We focus on Text-to-SQL semantic parsing from the perspective of Large Language Models. Motivated by challenges related to the size of commercial database schemata and the deployability of business intelligence solutions, we propose an approach that dynamically retrieves input database information and uses abstract syntax trees to select few-shot examples for in-context learning. Furthermore, we investigate the extent to which an in-parallel semantic parser can be leveraged for generating $\textit{approximated}$ versions of the expected SQL queries, to support our retrieval. We take this approach to the extreme--we adapt a model consisting of less than $500$M parameters, to act as an extremely efficient approximator, enhancing it with the ability to process schemata in a parallelised manner. We apply our approach to monolingual and cross-lingual benchmarks for semantic parsing, showing improvements over state-of-the-art baselines. Comprehensive experiments highlight the contribution of modules involved in this retrieval-augmented generation setting, revealing interesting directions for future work.