 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Extensive Evaluation of PDDL Capabilities in off-the-shelf LLMs
Feb 27, 2025


In recent advancements, large language models (LLMs) have exhibited proficiency in code generation and chain-of-thought reasoning, laying the groundwork for tackling automatic formal planning tasks. This study evaluates the potential of LLMs to understand and generate Planning Domain Definition Language (PDDL), an essential representation in artificial intelligence planning. We conduct an extensive analysis across 20 distinct models spanning 7 major LLM families, both commercial and open-source. Our comprehensive evaluation sheds light on the zero-shot LLM capabilities of parsing, generating, and reasoning with PDDL. Our findings indicate that while some models demonstrate notable effectiveness in handling PDDL, others pose limitations in more complex scenarios requiring nuanced planning knowledge. These results highlight the promise and current limitations of LLMs in formal planning tasks, offering insights into their application and guiding future efforts in AI-driven planning paradigms.
GeAR: Graph-enhanced Agent for Retrieval-augmented Generation
Dec 24, 2024Retrieval-augmented generation systems rely on effective document retrieval capabilities. By design, conventional sparse or dense retrievers face challenges in multi-hop retrieval scenarios. In this paper, we present GeAR, which advances RAG performance through two key innovations: (i) graph expansion, which enhances any conventional base retriever, such as BM25, and (ii) an agent framework that incorporates graph expansion. Our evaluation demonstrates GeAR's superior retrieval performance on three multi-hop question answering datasets. Additionally, our system achieves state-of-the-art results with improvements exceeding 10% on the challenging MuSiQue dataset, while requiring fewer tokens and iterations compared to other multi-step retrieval systems.
From An LLM Swarm To A PDDL-Empowered HIVE: Planning Self-Executed Instructions In A Multi-Modal Jungle
Dec 17, 2024



In response to the call for agent-based solutions that leverage the ever-increasing capabilities of the deep models' ecosystem, we introduce Hive -- a comprehensive solution for selecting appropriate models and subsequently planning a set of atomic actions to satisfy the end-users' instructions. Hive operates over sets of models and, upon receiving natural language instructions (i.e. user queries), schedules and executes explainable plans of atomic actions. These actions can involve one or more of the available models to achieve the overall task, while respecting end-users specific constraints. Notably, Hive handles tasks that involve multi-modal inputs and outputs, enabling it to handle complex, real-world queries. Our system is capable of planning complex chains of actions while guaranteeing explainability, using an LLM-based formal logic backbone empowered by PDDL operations. We introduce the MuSE benchmark in order to offer a comprehensive evaluation of the multi-modal capabilities of agent systems. Our findings show that our framework redefines the state-of-the-art for task selection, outperforming other competing systems that plan operations across multiple models while offering transparency guarantees while fully adhering to user constraints.
Large Language Models and Knowledge Graphs: Opportunities and Challenges
Aug 11, 2023Large Language Models (LLMs) have taken Knowledge Representation -- and the world -- by storm. This inflection point marks a shift from explicit knowledge representation to a renewed focus on the hybrid representation of both explicit knowledge and parametric knowledge. In this position paper, we will discuss some of the common debate points within the community on LLMs (parametric knowledge) and Knowledge Graphs (explicit knowledge) and speculate on opportunities and visions that the renewed focus brings, as well as related research topics and challenges.
The Query Translation Landscape: a Survey
Oct 07, 2019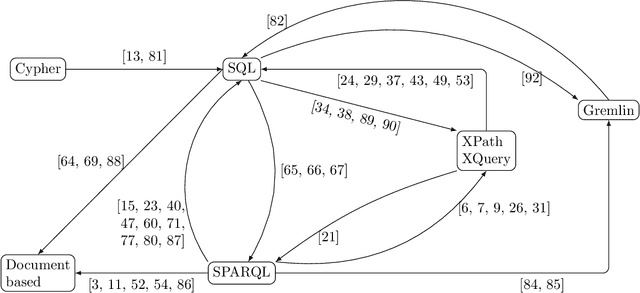
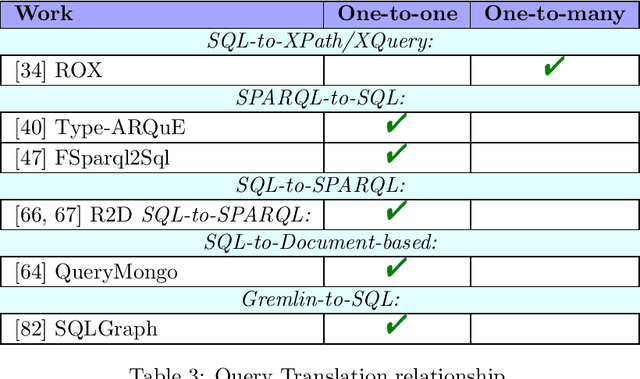
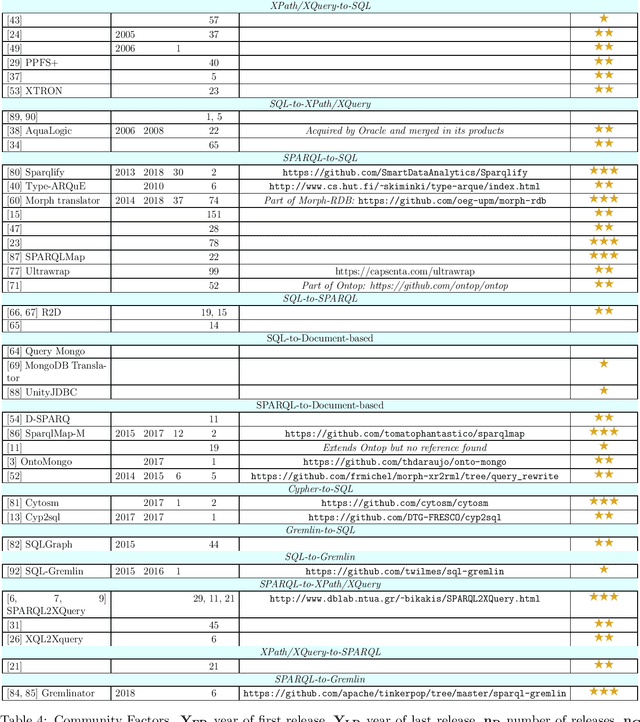
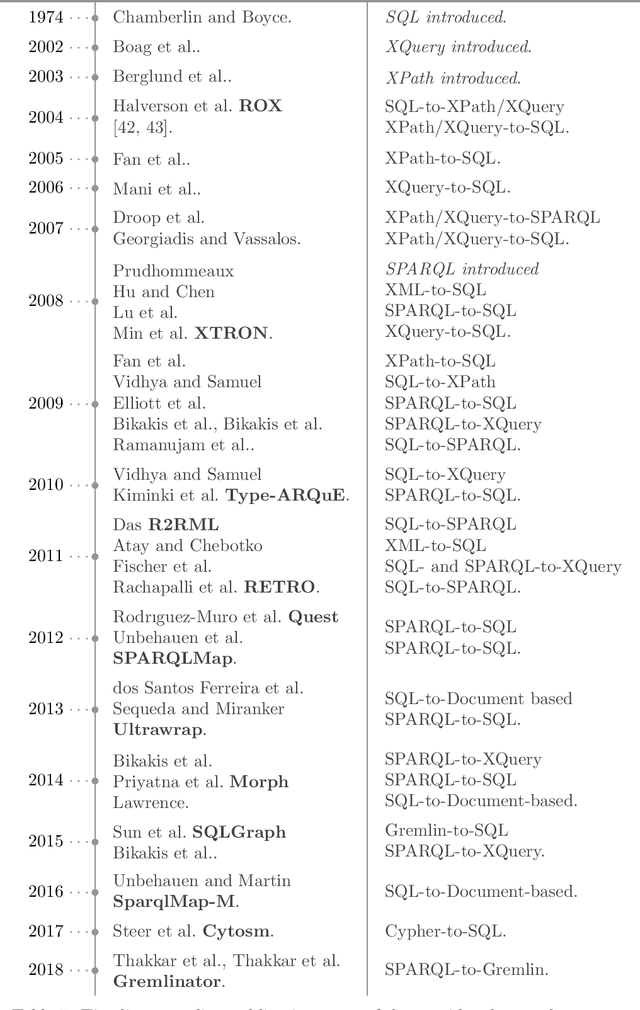
Whereas the availability of data has seen a manyfold increase in past years, its value can be only shown if the data variety is effectively tackled ---one of the prominent Big Data challenges. The lack of data interoperability limits the potential of its collective use for novel applications. Achieving interoperability through the full transformation and integration of diverse data structures remains an ideal that is hard, if not impossible, to achieve. Instead, methods that can simultaneously interpret different types of data available in different data structures and formats have been explored. On the other hand, many query languages have been designed to enable users to interact with the data, from relational, to object-oriented, to hierarchical, to the multitude emerging NoSQL languages. Therefore, the interoperability issue could be solved not by enforcing physical data transformation, but by looking at techniques that are able to query heterogeneous sources using one uniform language. Both industry and research communities have been keen to develop such techniques, which require the translation of a chosen 'universal' query language to the various data model specific query languages that make the underlying data accessible. In this article, we survey more than forty query translation methods and tools for popular query languages, and classify them according to eight criteria. In particular, we study which query language is a most suitable candidate for that 'universal' query language. Further, the results enable us to discover the weakly addressed and unexplored translation paths, to discover gaps and to learn lessons that can benefit future research in the area.
MDE: Multi Distance Embeddings for Link Prediction in Knowledge Graphs
Jun 10, 2019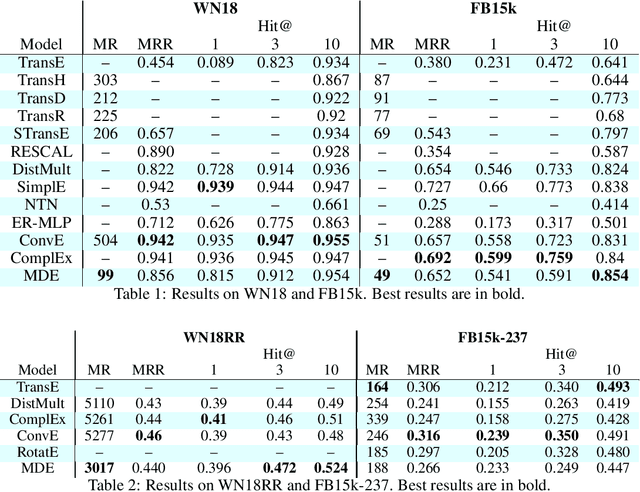
Over the past decade, knowledge graphs became popular for capturing structured domain knowledge. Relational learning models enable the prediction of missing links inside knowledge graphs. More specifically, latent distance approaches model the relationships among entities via a distance between latent representations. Translating embedding models (e.g., TransE) are among the most popular latent distance approaches which use one distance function to learn multiple relation patterns. However, they are not capable of capturing symmetric relations. They also force relations with reflexive patterns to become symmetric and transitive. In order to improve distance based embedding, we propose multi-distance embeddings (MDE). Our solution is based on the idea that by learning independent embedding vectors for each entity and relation one can aggregate contrasting distance functions. Benefiting from MDE, we also develop supplementary distances resolving the above-mentioned limitations of TransE. We further propose an extended loss function for distance based embeddings and show that MDE and TransE are fully expressive using this loss function. Furthermore, we obtain a bound on the size of their embeddings for full expressivity. Our empirical results show that MDE significantly improves the translating embeddings and outperforms several state-of-the-art embedding models on benchmark datasets.