 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntroducing ORKG ASK: an AI-driven Scholarly Literature Search and Exploration System Taking a Neuro-Symbolic Approach
Dec 18, 2025As the volume of published scholarly literature continues to grow, finding relevant literature becomes increasingly difficult. With the rise of generative Artificial Intelligence (AI), and particularly Large Language Models (LLMs), new possibilities emerge to find and explore literature. We introduce ASK (Assistant for Scientific Knowledge), an AI-driven scholarly literature search and exploration system that follows a neuro-symbolic approach. ASK aims to provide active support to researchers in finding relevant scholarly literature by leveraging vector search, LLMs, and knowledge graphs. The system allows users to input research questions in natural language and retrieve relevant articles. ASK automatically extracts key information and generates answers to research questions using a Retrieval-Augmented Generation (RAG) approach. We present an evaluation of ASK, assessing the system's usability and usefulness. Findings indicate that the system is user-friendly and users are generally satisfied while using the system.
Towards AI-Supported Research: a Vision of the TIB AIssistant
Dec 18, 2025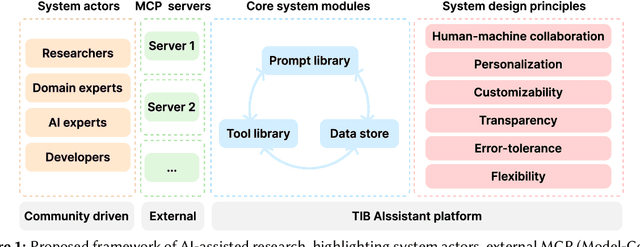
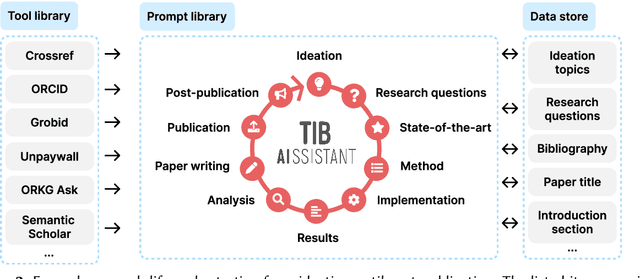
The rapid advancements in Generative AI and Large Language Models promise to transform the way research is conducted, potentially offering unprecedented opportunities to augment scholarly workflows. However, effectively integrating AI into research remains a challenge due to varying domain requirements, limited AI literacy, the complexity of coordinating tools and agents, and the unclear accuracy of Generative AI in research. We present the vision of the TIB AIssistant, a domain-agnostic human-machine collaborative platform designed to support researchers across disciplines in scientific discovery, with AI assistants supporting tasks across the research life cycle. The platform offers modular components - including prompt and tool libraries, a shared data store, and a flexible orchestration framework - that collectively facilitate ideation, literature analysis, methodology development, data analysis, and scholarly writing. We describe the conceptual framework, system architecture, and implementation of an early prototype that demonstrates the feasibility and potential impact of our approach.
TIB AIssistant: a Platform for AI-Supported Research Across Research Life Cycles
Dec 18, 2025

The rapidly growing popularity of adopting Artificial Intelligence (AI), and specifically Large Language Models (LLMs), is having a widespread impact throughout society, including the academic domain. AI-supported research has the potential to support researchers with tasks across the entire research life cycle. In this work, we demonstrate the TIB AIssistant, an AI-supported research platform providing support throughout the research life cycle. The AIssistant consists of a collection of assistants, each responsible for a specific research task. In addition, tools are provided to give access to external scholarly services. Generated data is stored in the assets and can be exported as an RO-Crate bundle to provide transparency and enhance reproducibility of the research project. We demonstrate the AIssistant's main functionalities by means of a sequential walk-through of assistants, interacting with each other to generate sections for a draft research paper. In the end, with the AIssistant, we lay the foundation for a larger agenda of providing a community-maintained platform for AI-supported research.
EmoNet-Voice: A Fine-Grained, Expert-Verified Benchmark for Speech Emotion Detection
Jun 11, 2025The advancement of text-to-speech and audio generation models necessitates robust benchmarks for evaluating the emotional understanding capabilities of AI systems. Current speech emotion recognition (SER) datasets often exhibit limitations in emotional granularity, privacy concerns, or reliance on acted portrayals. This paper introduces EmoNet-Voice, a new resource for speech emotion detection, which includes EmoNet-Voice Big, a large-scale pre-training dataset (featuring over 4,500 hours of speech across 11 voices, 40 emotions, and 4 languages), and EmoNet-Voice Bench, a novel benchmark dataset with human expert annotations. EmoNet-Voice is designed to evaluate SER models on a fine-grained spectrum of 40 emotion categories with different levels of intensities. Leveraging state-of-the-art voice generation, we curated synthetic audio snippets simulating actors portraying scenes designed to evoke specific emotions. Crucially, we conducted rigorous validation by psychology experts who assigned perceived intensity labels. This synthetic, privacy-preserving approach allows for the inclusion of sensitive emotional states often absent in existing datasets. Lastly, we introduce Empathic Insight Voice models that set a new standard in speech emotion recognition with high agreement with human experts. Our evaluations across the current model landscape exhibit valuable findings, such as high-arousal emotions like anger being much easier to detect than low-arousal states like concentration.
Research Knowledge Graphs: the Shifting Paradigm of Scholarly Information Representation
Jun 08, 2025Sharing and reusing research artifacts, such as datasets, publications, or methods is a fundamental part of scientific activity, where heterogeneity of resources and metadata and the common practice of capturing information in unstructured publications pose crucial challenges. Reproducibility of research and finding state-of-the-art methods or data have become increasingly challenging. In this context, the concept of Research Knowledge Graphs (RKGs) has emerged, aiming at providing an easy to use and machine-actionable representation of research artifacts and their relations. That is facilitated through the use of established principles for data representation, the consistent adoption of globally unique persistent identifiers and the reuse and linking of vocabularies and data. This paper provides the first conceptualisation of the RKG vision, a categorisation of in-use RKGs together with a description of RKG building blocks and principles. We also survey real-world RKG implementations differing with respect to scale, schema, data, used vocabulary, and reliability of the contained data. We also characterise different RKG construction methodologies and provide a forward-looking perspective on the diverse applications, opportunities, and challenges associated with the RKG vision.
EmoNet-Face: An Expert-Annotated Benchmark for Synthetic Emotion Recognition
May 26, 2025Effective human-AI interaction relies on AI's ability to accurately perceive and interpret human emotions. Current benchmarks for vision and vision-language models are severely limited, offering a narrow emotional spectrum that overlooks nuanced states (e.g., bitterness, intoxication) and fails to distinguish subtle differences between related feelings (e.g., shame vs. embarrassment). Existing datasets also often use uncontrolled imagery with occluded faces and lack demographic diversity, risking significant bias. To address these critical gaps, we introduce EmoNet Face, a comprehensive benchmark suite. EmoNet Face features: (1) A novel 40-category emotion taxonomy, meticulously derived from foundational research to capture finer details of human emotional experiences. (2) Three large-scale, AI-generated datasets (EmoNet HQ, Binary, and Big) with explicit, full-face expressions and controlled demographic balance across ethnicity, age, and gender. (3) Rigorous, multi-expert annotations for training and high-fidelity evaluation. (4) We build Empathic Insight Face, a model achieving human-expert-level performance on our benchmark. The publicly released EmoNet Face suite - taxonomy, datasets, and model - provides a robust foundation for developing and evaluating AI systems with a deeper understanding of human emotions.
SciCom Wiki: Fact-Checking and FAIR Knowledge Distribution for Scientific Videos and Podcasts
May 12, 2025Democratic societies need accessible, reliable information. Videos and Podcasts have established themselves as the medium of choice for civic dissemination, but also as carriers of misinformation. The emerging Science Communication Knowledge Infrastructure (SciCom KI) curating non-textual media is still fragmented and not adequately equipped to scale against the content flood. Our work sets out to support the SciCom KI with a central, collaborative platform, the SciCom Wiki, to facilitate FAIR (findable, accessible, interoperable, reusable) media representation and the fact-checking of their content, particularly for videos and podcasts. Building an open-source service system centered around Wikibase, we survey requirements from 53 stakeholders, refine these in 11 interviews, and evaluate our prototype based on these requirements with another 14 participants. To address the most requested feature, fact-checking, we developed a neurosymbolic computational fact-checking approach, converting heterogenous media into knowledge graphs. This increases machine-readability and allows comparing statements against equally represented ground-truth. Our computational fact-checking tool was iteratively evaluated through 10 expert interviews, a public user survey with 43 participants verified the necessity and usability of our tool. Overall, our findings identified several needs to systematically support the SciCom KI. The SciCom Wiki, as a FAIR digital library complementing our neurosymbolic computational fact-checking framework, was found suitable to address the raised requirements. Further, we identified that the SciCom KI is severely underdeveloped regarding FAIR knowledge and related systems facilitating its collaborative creation and curation. Our system can provide a central knowledge node, yet a collaborative effort is required to scale against the imminent (mis-)information flood.
Computational Fact-Checking of Online Discourse: Scoring scientific accuracy in climate change related news articles
May 12, 2025Democratic societies need reliable information. Misinformation in popular media such as news articles or videos threatens to impair civic discourse. Citizens are, unfortunately, not equipped to verify this content flood consumed daily at increasing rates. This work aims to semi-automatically quantify scientific accuracy of online media. By semantifying media of unknown veracity, their statements can be compared against equally processed trusted sources. We implemented a workflow using LLM-based statement extraction and knowledge graph analysis. Our neurosymbolic system was able to evidently streamline state-of-the-art veracity quantification. Evaluated via expert interviews and a user survey, the tool provides a beneficial veracity indication. This indicator, however, is unable to annotate public media at the required granularity and scale. Further work towards a FAIR (Findable, Accessible, Interoperable, Reusable) ground truth and complementary metrics are required to scientifically support civic discourse.
LLMs4SchemaDiscovery: A Human-in-the-Loop Workflow for Scientific Schema Mining with Large Language Models
Apr 01, 2025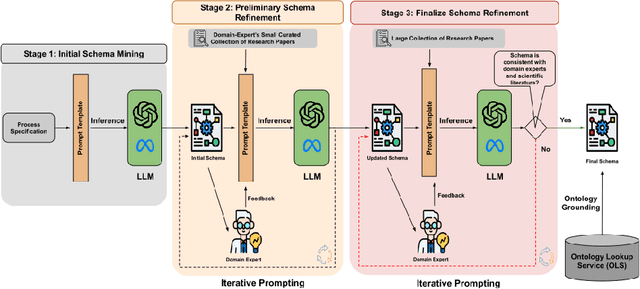
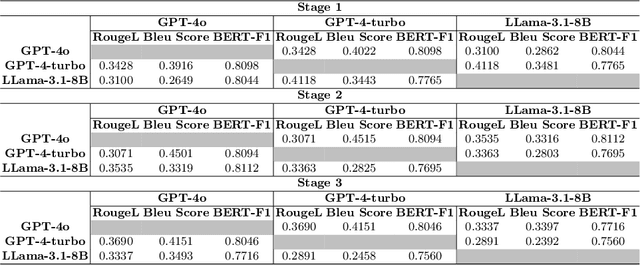
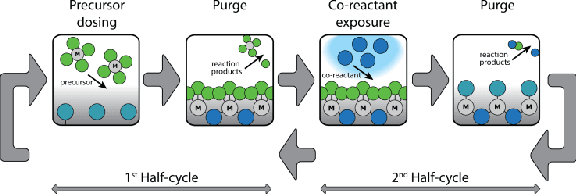
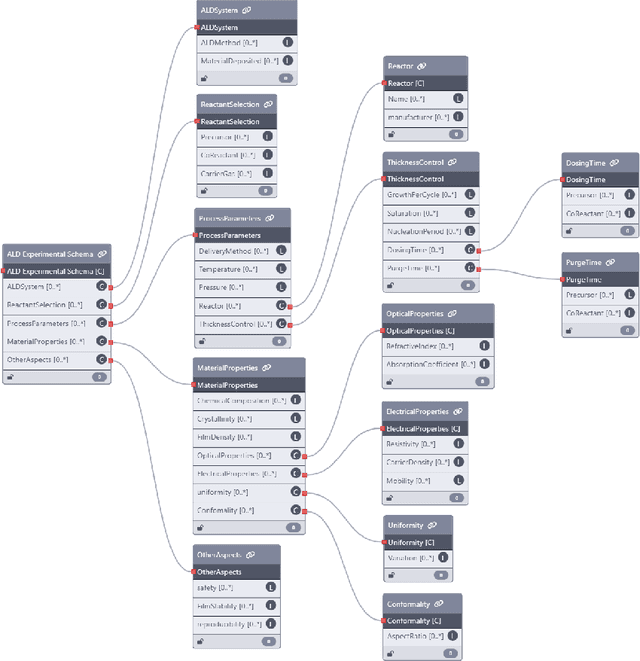
Extracting structured information from unstructured text is crucial for modeling real-world processes, but traditional schema mining relies on semi-structured data, limiting scalability. This paper introduces schema-miner, a novel tool that combines large language models with human feedback to automate and refine schema extraction. Through an iterative workflow, it organizes properties from text, incorporates expert input, and integrates domain-specific ontologies for semantic depth. Applied to materials science--specifically atomic layer deposition--schema-miner demonstrates that expert-guided LLMs generate semantically rich schemas suitable for diverse real-world applications.
OntoAligner: A Comprehensive Modular and Robust Python Toolkit for Ontology Alignment
Mar 27, 2025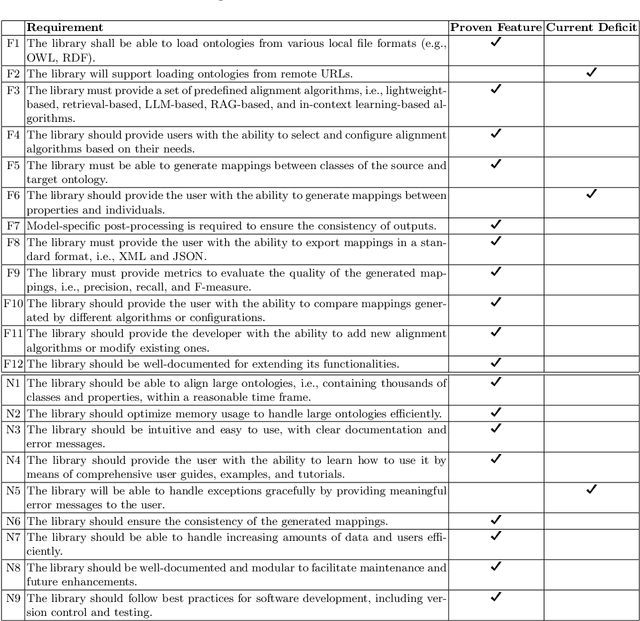
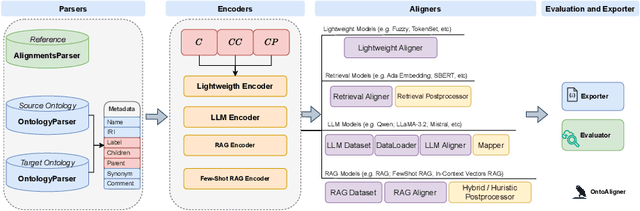
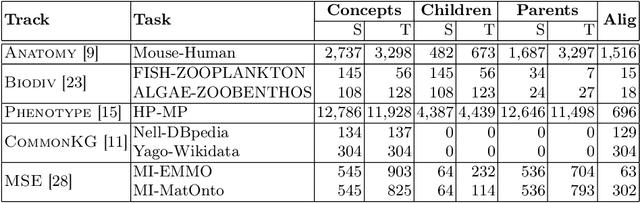

Ontology Alignment (OA) is fundamental for achieving semantic interoperability across diverse knowledge systems. We present OntoAligner, a comprehensive, modular, and robust Python toolkit for ontology alignment, designed to address current limitations with existing tools faced by practitioners. Existing tools are limited in scalability, modularity, and ease of integration with recent AI advances. OntoAligner provides a flexible architecture integrating existing lightweight OA techniques such as fuzzy matching but goes beyond by supporting contemporary methods with retrieval-augmented generation and large language models for OA. The framework prioritizes extensibility, enabling researchers to integrate custom alignment algorithms and datasets. This paper details the design principles, architecture, and implementation of the OntoAligner, demonstrating its utility through benchmarks on standard OA tasks. Our evaluation highlights OntoAligner's ability to handle large-scale ontologies efficiently with few lines of code while delivering high alignment quality. By making OntoAligner open-source, we aim to provide a resource that fosters innovation and collaboration within the OA community, empowering researchers and practitioners with a toolkit for reproducible OA research and real-world applications.