 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards AI-Supported Research: a Vision of the TIB AIssistant
Dec 18, 2025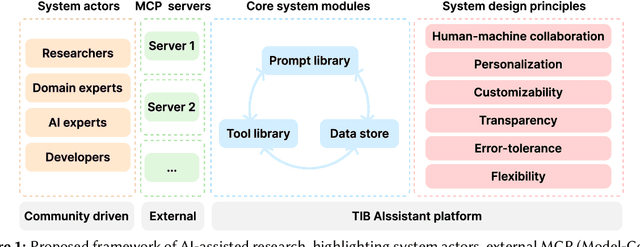
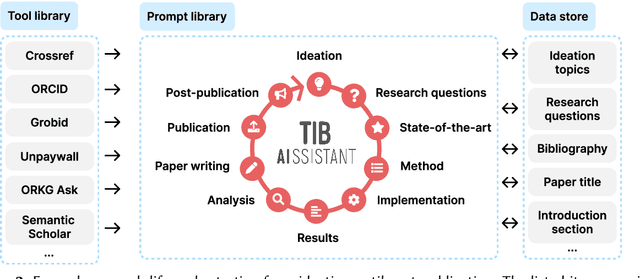
The rapid advancements in Generative AI and Large Language Models promise to transform the way research is conducted, potentially offering unprecedented opportunities to augment scholarly workflows. However, effectively integrating AI into research remains a challenge due to varying domain requirements, limited AI literacy, the complexity of coordinating tools and agents, and the unclear accuracy of Generative AI in research. We present the vision of the TIB AIssistant, a domain-agnostic human-machine collaborative platform designed to support researchers across disciplines in scientific discovery, with AI assistants supporting tasks across the research life cycle. The platform offers modular components - including prompt and tool libraries, a shared data store, and a flexible orchestration framework - that collectively facilitate ideation, literature analysis, methodology development, data analysis, and scholarly writing. We describe the conceptual framework, system architecture, and implementation of an early prototype that demonstrates the feasibility and potential impact of our approach.
SciCom Wiki: Fact-Checking and FAIR Knowledge Distribution for Scientific Videos and Podcasts
May 12, 2025Democratic societies need accessible, reliable information. Videos and Podcasts have established themselves as the medium of choice for civic dissemination, but also as carriers of misinformation. The emerging Science Communication Knowledge Infrastructure (SciCom KI) curating non-textual media is still fragmented and not adequately equipped to scale against the content flood. Our work sets out to support the SciCom KI with a central, collaborative platform, the SciCom Wiki, to facilitate FAIR (findable, accessible, interoperable, reusable) media representation and the fact-checking of their content, particularly for videos and podcasts. Building an open-source service system centered around Wikibase, we survey requirements from 53 stakeholders, refine these in 11 interviews, and evaluate our prototype based on these requirements with another 14 participants. To address the most requested feature, fact-checking, we developed a neurosymbolic computational fact-checking approach, converting heterogenous media into knowledge graphs. This increases machine-readability and allows comparing statements against equally represented ground-truth. Our computational fact-checking tool was iteratively evaluated through 10 expert interviews, a public user survey with 43 participants verified the necessity and usability of our tool. Overall, our findings identified several needs to systematically support the SciCom KI. The SciCom Wiki, as a FAIR digital library complementing our neurosymbolic computational fact-checking framework, was found suitable to address the raised requirements. Further, we identified that the SciCom KI is severely underdeveloped regarding FAIR knowledge and related systems facilitating its collaborative creation and curation. Our system can provide a central knowledge node, yet a collaborative effort is required to scale against the imminent (mis-)information flood.
OntoAligner: A Comprehensive Modular and Robust Python Toolkit for Ontology Alignment
Mar 27, 2025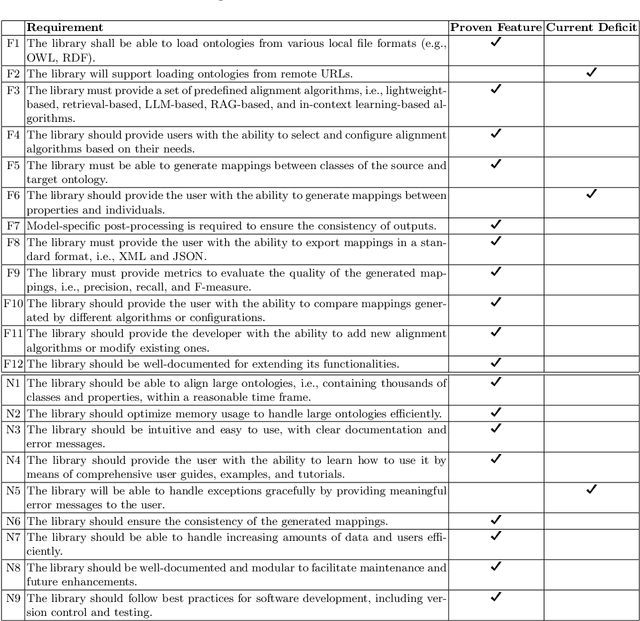
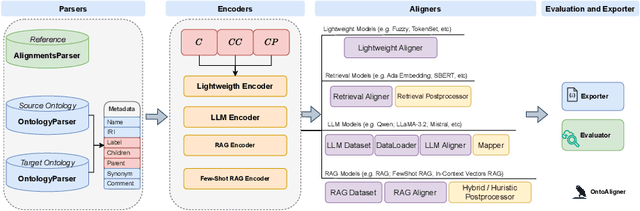
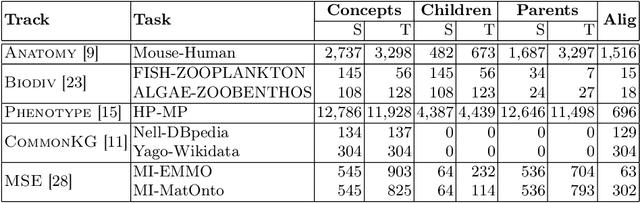

Ontology Alignment (OA) is fundamental for achieving semantic interoperability across diverse knowledge systems. We present OntoAligner, a comprehensive, modular, and robust Python toolkit for ontology alignment, designed to address current limitations with existing tools faced by practitioners. Existing tools are limited in scalability, modularity, and ease of integration with recent AI advances. OntoAligner provides a flexible architecture integrating existing lightweight OA techniques such as fuzzy matching but goes beyond by supporting contemporary methods with retrieval-augmented generation and large language models for OA. The framework prioritizes extensibility, enabling researchers to integrate custom alignment algorithms and datasets. This paper details the design principles, architecture, and implementation of the OntoAligner, demonstrating its utility through benchmarks on standard OA tasks. Our evaluation highlights OntoAligner's ability to handle large-scale ontologies efficiently with few lines of code while delivering high alignment quality. By making OntoAligner open-source, we aim to provide a resource that fosters innovation and collaboration within the OA community, empowering researchers and practitioners with a toolkit for reproducible OA research and real-world applications.
The Potential of Using Vision Videos for CrowdRE: Video Comments as a Source of Feedback
Aug 04, 2021
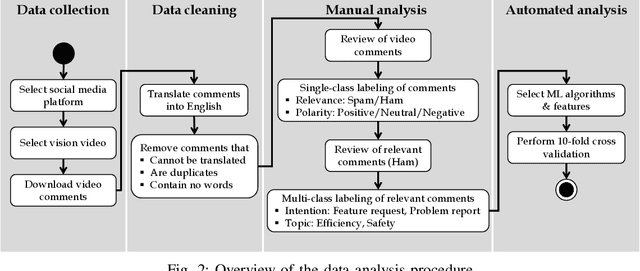
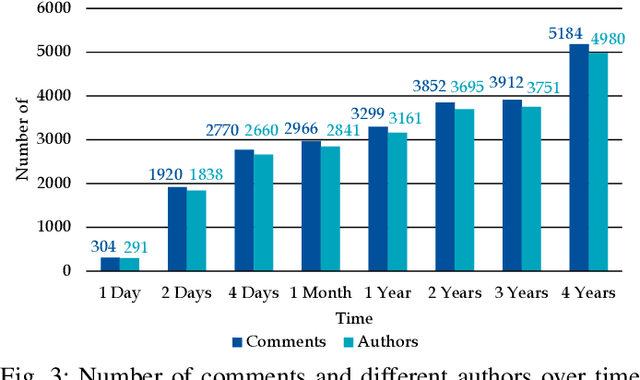
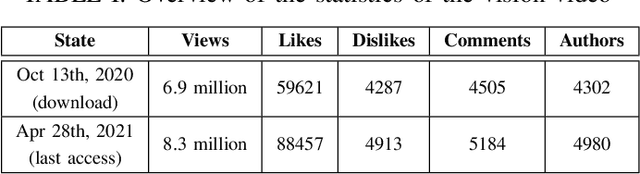
Vision videos are established for soliciting feedback and stimulating discussions in requirements engineering (RE) practices, such as focus groups. Different researchers motivated the transfer of these benefits into crowd-based RE (CrowdRE) by using vision videos on social media platforms. So far, however, little research explored the potential of using vision videos for CrowdRE in detail. In this paper, we analyze and assess this potential, in particular, focusing on video comments as a source of feedback. In a case study, we analyzed 4505 comments on a vision video from YouTube. We found that the video solicited 2770 comments from 2660 viewers in four days. This is more than 50% of all comments the video received in four years. Even though only a certain fraction of these comments are relevant to RE, the relevant comments address typical intentions and topics of user feedback, such as feature request or problem report. Besides the typical user feedback categories, we found more than 300 comments that address the topic safety, which has not appeared in previous analyses of user feedback. In an automated analysis, we compared the performance of three machine learning algorithms on classifying the video comments. Despite certain differences, the algorithms classified the video comments well. Based on these findings, we conclude that the use of vision videos for CrowdRE has a large potential. Despite the preliminary nature of the case study, we are optimistic that vision videos can motivate stakeholders to actively participate in a crowd and solicit numerous of video comments as a valuable source of feedback.