 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNFDI4DS Shared Tasks for Scholarly Document Processing
Sep 26, 2025Shared tasks are powerful tools for advancing research through community-based standardised evaluation. As such, they play a key role in promoting findable, accessible, interoperable, and reusable (FAIR), as well as transparent and reproducible research practices. This paper presents an updated overview of twelve shared tasks developed and hosted under the German National Research Data Infrastructure for Data Science and Artificial Intelligence (NFDI4DS) consortium, covering a diverse set of challenges in scholarly document processing. Hosted at leading venues, the tasks foster methodological innovations and contribute open-access datasets, models, and tools for the broader research community, which are integrated into the consortium's research data infrastructure.
YESciEval: Robust LLM-as-a-Judge for Scientific Question Answering
May 20, 2025Large Language Models (LLMs) drive scientific question-answering on modern search engines, yet their evaluation robustness remains underexplored. We introduce YESciEval, an open-source framework that combines fine-grained rubric-based assessment with reinforcement learning to mitigate optimism bias in LLM evaluators. We release multidisciplinary scienceQ&A datasets, including adversarial variants, with evaluation scores from multiple LLMs. Independent of proprietary models and human feedback, our approach enables scalable, cost-free evaluation. By advancing reliable LLM-as-a-judge models, this work supports AI alignment and fosters robust, transparent evaluation essential for scientific inquiry and artificial general intelligence.
Homa at SemEval-2025 Task 5: Aligning Librarian Records with OntoAligner for Subject Tagging
Apr 30, 2025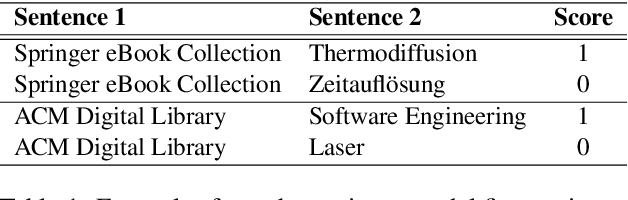
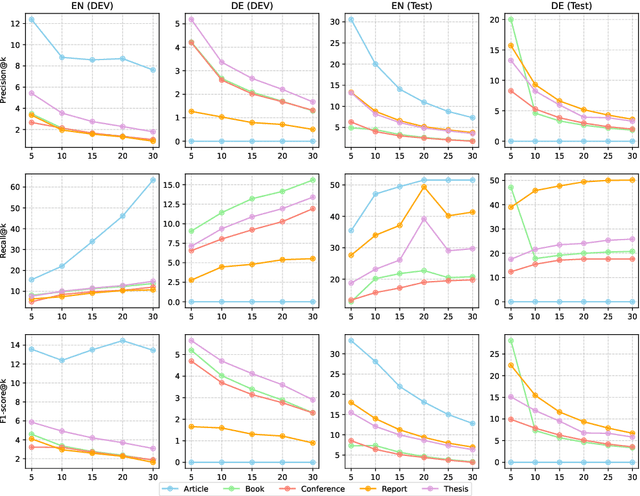
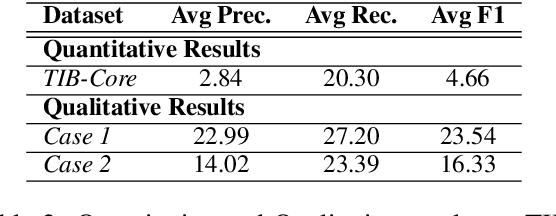
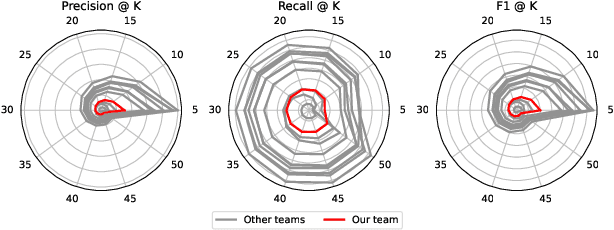
This paper presents our system, Homa, for SemEval-2025 Task 5: Subject Tagging, which focuses on automatically assigning subject labels to technical records from TIBKAT using the Gemeinsame Normdatei (GND) taxonomy. We leverage OntoAligner, a modular ontology alignment toolkit, to address this task by integrating retrieval-augmented generation (RAG) techniques. Our approach formulates the subject tagging problem as an alignment task, where records are matched to GND categories based on semantic similarity. We evaluate OntoAligner's adaptability for subject indexing and analyze its effectiveness in handling multilingual records. Experimental results demonstrate the strengths and limitations of this method, highlighting the potential of alignment techniques for improving subject tagging in digital libraries.
LLMs4SchemaDiscovery: A Human-in-the-Loop Workflow for Scientific Schema Mining with Large Language Models
Apr 01, 2025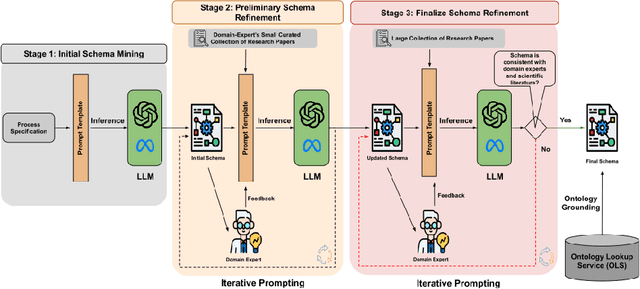
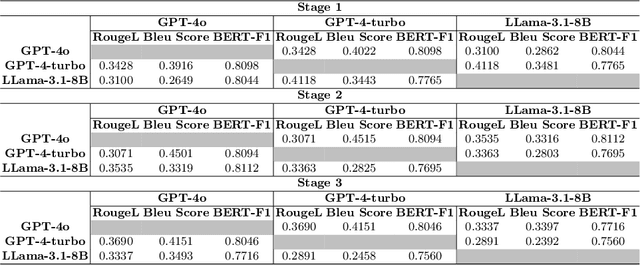
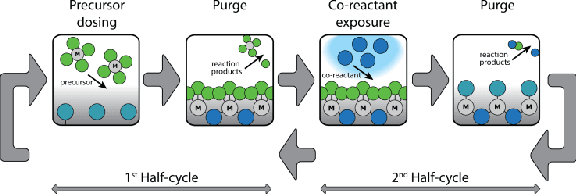
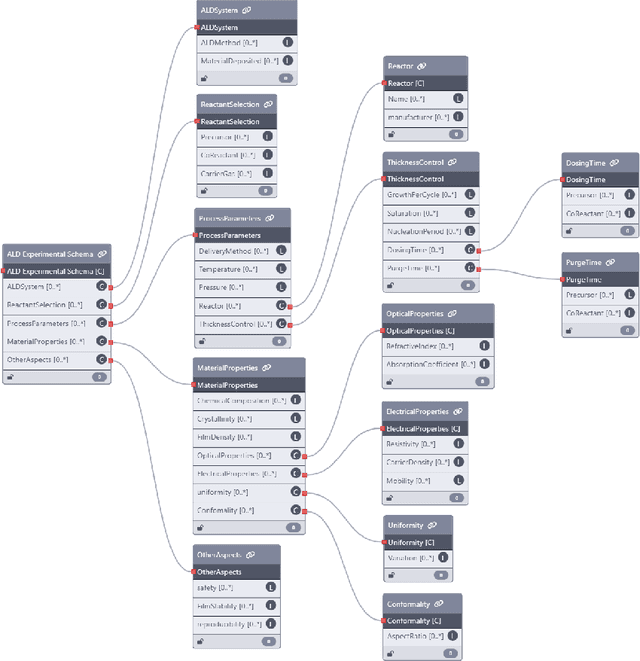
Extracting structured information from unstructured text is crucial for modeling real-world processes, but traditional schema mining relies on semi-structured data, limiting scalability. This paper introduces schema-miner, a novel tool that combines large language models with human feedback to automate and refine schema extraction. Through an iterative workflow, it organizes properties from text, incorporates expert input, and integrates domain-specific ontologies for semantic depth. Applied to materials science--specifically atomic layer deposition--schema-miner demonstrates that expert-guided LLMs generate semantically rich schemas suitable for diverse real-world applications.
OntoAligner: A Comprehensive Modular and Robust Python Toolkit for Ontology Alignment
Mar 27, 2025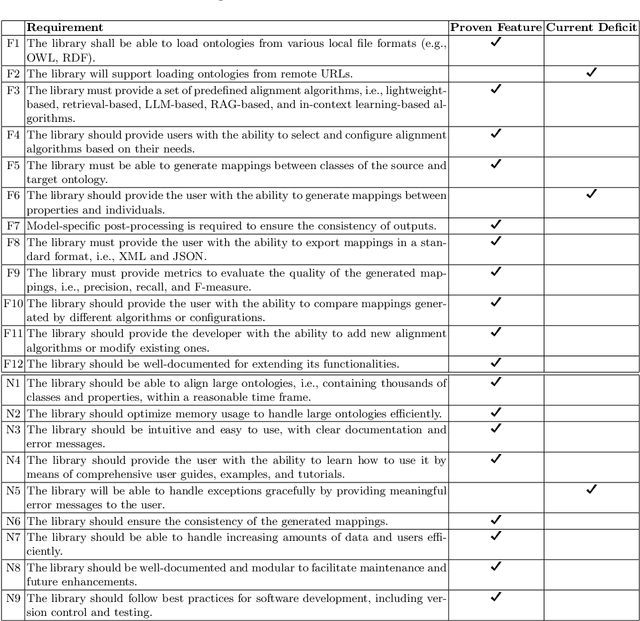
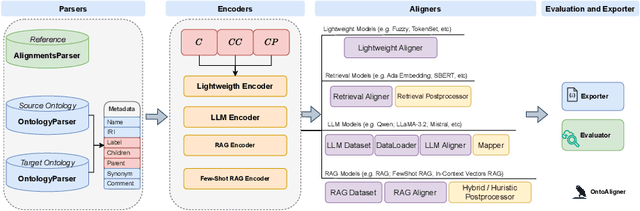

Ontology Alignment (OA) is fundamental for achieving semantic interoperability across diverse knowledge systems. We present OntoAligner, a comprehensive, modular, and robust Python toolkit for ontology alignment, designed to address current limitations with existing tools faced by practitioners. Existing tools are limited in scalability, modularity, and ease of integration with recent AI advances. OntoAligner provides a flexible architecture integrating existing lightweight OA techniques such as fuzzy matching but goes beyond by supporting contemporary methods with retrieval-augmented generation and large language models for OA. The framework prioritizes extensibility, enabling researchers to integrate custom alignment algorithms and datasets. This paper details the design principles, architecture, and implementation of the OntoAligner, demonstrating its utility through benchmarks on standard OA tasks. Our evaluation highlights OntoAligner's ability to handle large-scale ontologies efficiently with few lines of code while delivering high alignment quality. By making OntoAligner open-source, we aim to provide a resource that fosters innovation and collaboration within the OA community, empowering researchers and practitioners with a toolkit for reproducible OA research and real-world applications.
LLMs4Synthesis: Leveraging Large Language Models for Scientific Synthesis
Sep 27, 2024
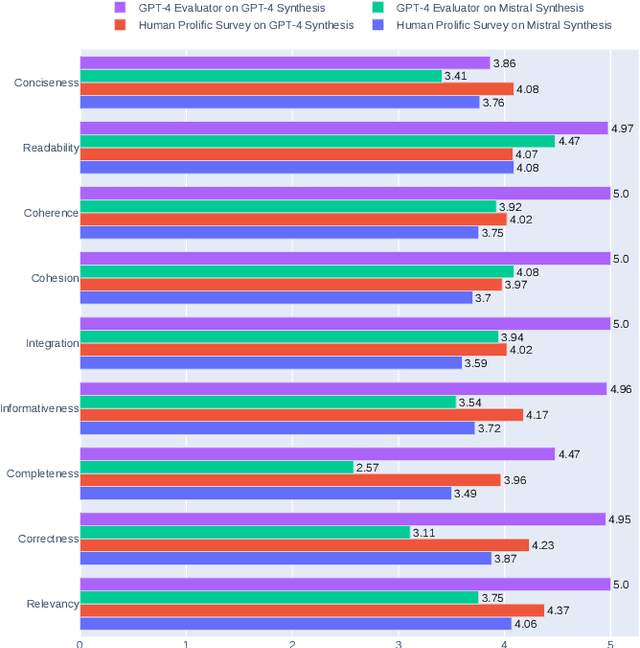

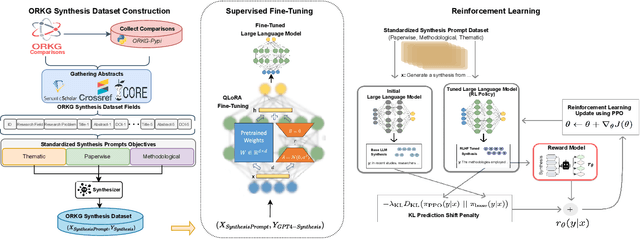
In response to the growing complexity and volume of scientific literature, this paper introduces the LLMs4Synthesis framework, designed to enhance the capabilities of Large Language Models (LLMs) in generating high-quality scientific syntheses. This framework addresses the need for rapid, coherent, and contextually rich integration of scientific insights, leveraging both open-source and proprietary LLMs. It also examines the effectiveness of LLMs in evaluating the integrity and reliability of these syntheses, alleviating inadequacies in current quantitative metrics. Our study contributes to this field by developing a novel methodology for processing scientific papers, defining new synthesis types, and establishing nine detailed quality criteria for evaluating syntheses. The integration of LLMs with reinforcement learning and AI feedback is proposed to optimize synthesis quality, ensuring alignment with established criteria. The LLMs4Synthesis framework and its components are made available, promising to enhance both the generation and evaluation processes in scientific research synthesis.
LLMs4OL 2024 Overview: The 1st Large Language Models for Ontology Learning Challenge
Sep 16, 2024This paper outlines the LLMs4OL 2024, the first edition of the Large Language Models for Ontology Learning Challenge. LLMs4OL is a community development initiative collocated with the 23rd International Semantic Web Conference (ISWC) to explore the potential of Large Language Models (LLMs) in Ontology Learning (OL), a vital process for enhancing the web with structured knowledge to improve interoperability. By leveraging LLMs, the challenge aims to advance understanding and innovation in OL, aligning with the goals of the Semantic Web to create a more intelligent and user-friendly web. In this paper, we give an overview of the 2024 edition of the LLMs4OL challenge and summarize the contributions.
Towards Effective Authorship Attribution: Integrating Class-Incremental Learning
Aug 12, 2024AA is the process of attributing an unidentified document to its true author from a predefined group of known candidates, each possessing multiple samples. The nature of AA necessitates accommodating emerging new authors, as each individual must be considered unique. This uniqueness can be attributed to various factors, including their stylistic preferences, areas of expertise, gender, cultural background, and other personal characteristics that influence their writing. These diverse attributes contribute to the distinctiveness of each author, making it essential for AA systems to recognize and account for these variations. However, current AA benchmarks commonly overlook this uniqueness and frame the problem as a closed-world classification, assuming a fixed number of authors throughout the system's lifespan and neglecting the inclusion of emerging new authors. This oversight renders the majority of existing approaches ineffective for real-world applications of AA, where continuous learning is essential. These inefficiencies manifest as current models either resist learning new authors or experience catastrophic forgetting, where the introduction of new data causes the models to lose previously acquired knowledge. To address these inefficiencies, we propose redefining AA as CIL, where new authors are introduced incrementally after the initial training phase, allowing the system to adapt and learn continuously. To achieve this, we briefly examine subsequent CIL approaches introduced in other domains. Moreover, we have adopted several well-known CIL methods, along with an examination of their strengths and weaknesses in the context of AA. Additionally, we outline potential future directions for advancing CIL AA systems. As a result, our paper can serve as a starting point for evolving AA systems from closed-world models to continual learning through CIL paradigms.
Scholarly Question Answering using Large Language Models in the NFDI4DataScience Gateway
Jun 11, 2024



This paper introduces a scholarly Question Answering (QA) system on top of the NFDI4DataScience Gateway, employing a Retrieval Augmented Generation-based (RAG) approach. The NFDI4DS Gateway, as a foundational framework, offers a unified and intuitive interface for querying various scientific databases using federated search. The RAG-based scholarly QA, powered by a Large Language Model (LLM), facilitates dynamic interaction with search results, enhancing filtering capabilities and fostering a conversational engagement with the Gateway search. The effectiveness of both the Gateway and the scholarly QA system is demonstrated through experimental analysis.
LLMs4OM: Matching Ontologies with Large Language Models
Apr 16, 2024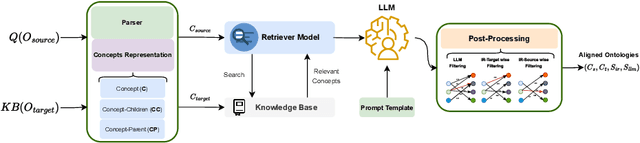
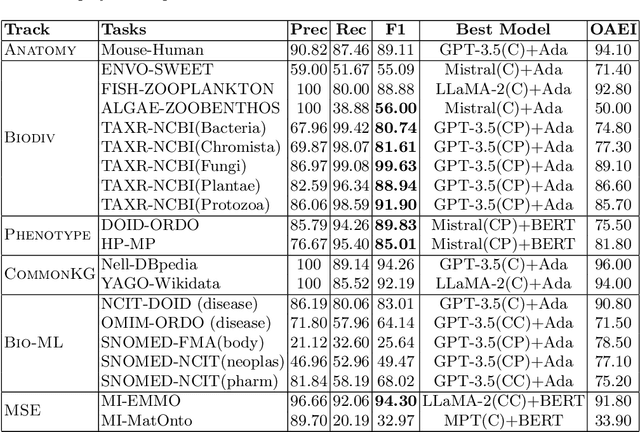
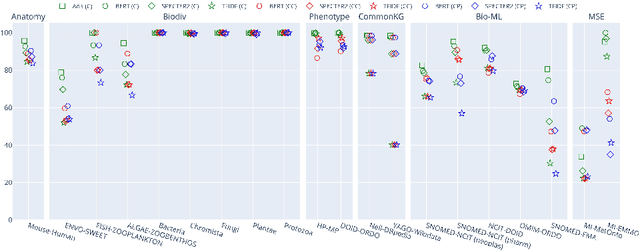
Ontology Matching (OM), is a critical task in knowledge integration, where aligning heterogeneous ontologies facilitates data interoperability and knowledge sharing. Traditional OM systems often rely on expert knowledge or predictive models, with limited exploration of the potential of Large Language Models (LLMs). We present the LLMs4OM framework, a novel approach to evaluate the effectiveness of LLMs in OM tasks. This framework utilizes two modules for retrieval and matching, respectively, enhanced by zero-shot prompting across three ontology representations: concept, concept-parent, and concept-children. Through comprehensive evaluations using 20 OM datasets from various domains, we demonstrate that LLMs, under the LLMs4OM framework, can match and even surpass the performance of traditional OM systems, particularly in complex matching scenarios. Our results highlight the potential of LLMs to significantly contribute to the field of OM.