 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNFDI4DS Shared Tasks for Scholarly Document Processing
Sep 26, 2025Shared tasks are powerful tools for advancing research through community-based standardised evaluation. As such, they play a key role in promoting findable, accessible, interoperable, and reusable (FAIR), as well as transparent and reproducible research practices. This paper presents an updated overview of twelve shared tasks developed and hosted under the German National Research Data Infrastructure for Data Science and Artificial Intelligence (NFDI4DS) consortium, covering a diverse set of challenges in scholarly document processing. Hosted at leading venues, the tasks foster methodological innovations and contribute open-access datasets, models, and tools for the broader research community, which are integrated into the consortium's research data infrastructure.
Ranking Facts for Explaining Answers to Elementary Science Questions
Oct 18, 2021
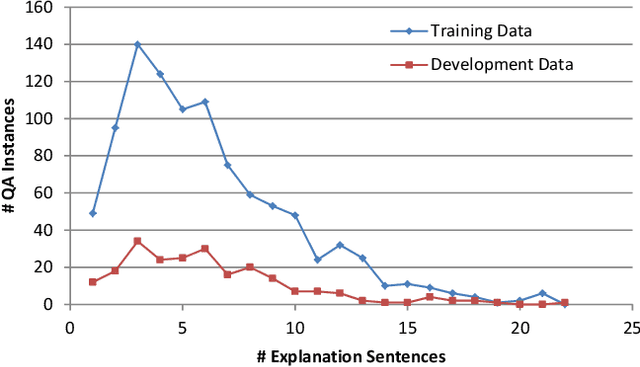

In multiple-choice exams, students select one answer from among typically four choices and can explain why they made that particular choice. Students are good at understanding natural language questions and based on their domain knowledge can easily infer the question's answer by 'connecting the dots' across various pertinent facts. Considering automated reasoning for elementary science question answering, we address the novel task of generating explanations for answers from human-authored facts. For this, we examine the practically scalable framework of feature-rich support vector machines leveraging domain-targeted, hand-crafted features. Explanations are created from a human-annotated set of nearly 5,000 candidate facts in the WorldTree corpus. Our aim is to obtain better matches for valid facts of an explanation for the correct answer of a question over the available fact candidates. To this end, our features offer a comprehensive linguistic and semantic unification paradigm. The machine learning problem is the preference ordering of facts, for which we test pointwise regression versus pairwise learning-to-rank. Our contributions are: (1) a case study in which two preference ordering approaches are systematically compared; (2) it is a practically competent approach that can outperform some variants of BERT-based reranking models; and (3) the human-engineered features make it an interpretable machine learning model for the task.
Pattern-based Acquisition of Scientific Entities from Scholarly Article Titles
Sep 01, 2021
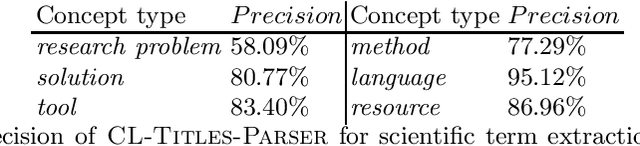

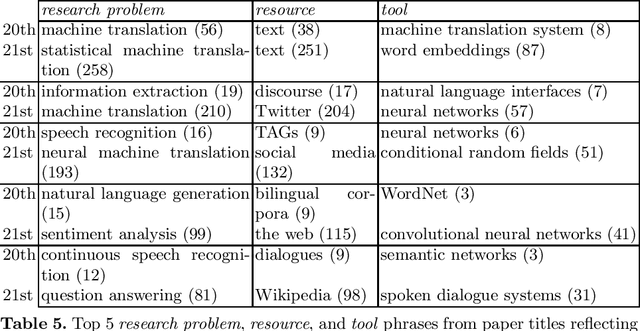
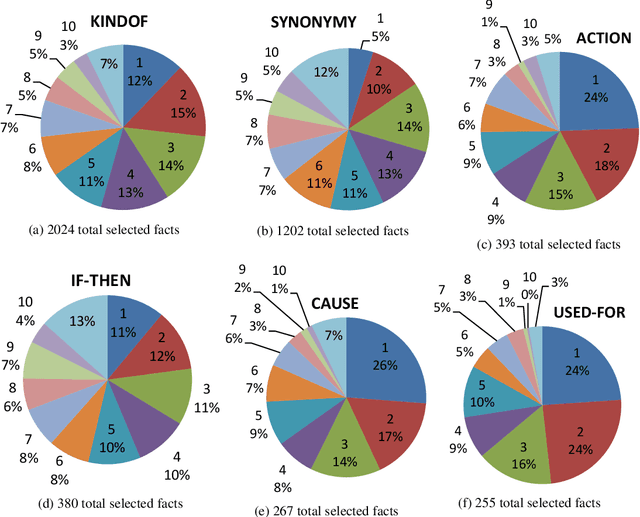
We describe a rule-based approach for the automatic acquisition of scientific entities from scholarly article titles. Two observations motivated the approach: (i) noting the concentration of an article's contribution information in its title; and (ii) capturing information pattern regularities via a system of rules that alleviate the human annotation task in creating gold standards that annotate single instances at a time. We identify a set of lexico-syntactic patterns that are easily recognizable, that occur frequently, and that generally indicates the scientific entity type of interest about the scholarly contribution. A subset of the acquisition algorithm is implemented for article titles in the Computational Linguistics (CL) scholarly domain. The tool called ORKG-Title-Parser, in its first release, identifies the following six concept types of scientific terminology from the CL paper titles, viz. research problem, solution, resource, language, tool, and method. It has been empirically evaluated on a collection of 50,237 titles that cover nearly all articles in the ACL Anthology. It has extracted 19,799 research problems; 18,111 solutions; 20,033 resources; 1,059 languages; 6,878 tools; and 21,687 methods at an average extraction precision of 75%. The code and related data resources are publicly available at https://gitlab.com/TIBHannover/orkg/orkg-title-parser. Finally, in the article, we discuss extensions and applications to areas such as scholarly knowledge graph (SKG) creation.