 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePattern-based Acquisition of Scientific Entities from Scholarly Article Titles
Paper and Code

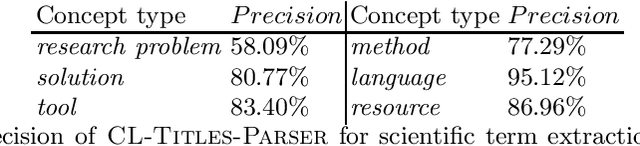

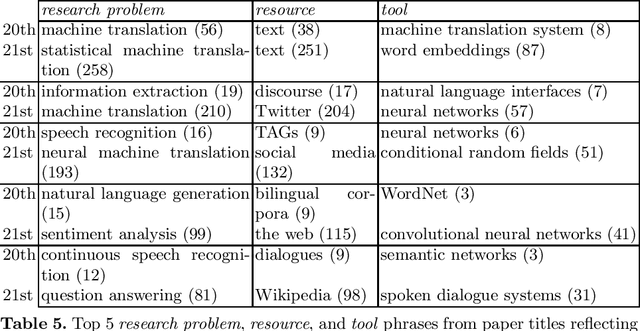
We describe a rule-based approach for the automatic acquisition of scientific entities from scholarly article titles. Two observations motivated the approach: (i) noting the concentration of an article's contribution information in its title; and (ii) capturing information pattern regularities via a system of rules that alleviate the human annotation task in creating gold standards that annotate single instances at a time. We identify a set of lexico-syntactic patterns that are easily recognizable, that occur frequently, and that generally indicates the scientific entity type of interest about the scholarly contribution. A subset of the acquisition algorithm is implemented for article titles in the Computational Linguistics (CL) scholarly domain. The tool called ORKG-Title-Parser, in its first release, identifies the following six concept types of scientific terminology from the CL paper titles, viz. research problem, solution, resource, language, tool, and method. It has been empirically evaluated on a collection of 50,237 titles that cover nearly all articles in the ACL Anthology. It has extracted 19,799 research problems; 18,111 solutions; 20,033 resources; 1,059 languages; 6,878 tools; and 21,687 methods at an average extraction precision of 75%. The code and related data resources are publicly available at https://gitlab.com/TIBHannover/orkg/orkg-title-parser. Finally, in the article, we discuss extensions and applications to areas such as scholarly knowledge graph (SKG) creation.