 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCan LLM Agents Be CFOs? A Benchmark for Resource Allocation in Dynamic Enterprise Environments
Mar 24, 2026Large language models (LLMs) have enabled agentic systems that can reason, plan, and act across complex tasks, but it remains unclear whether they can allocate resources effectively under uncertainty. Unlike short-horizon reactive decisions, allocation requires committing scarce resources over time while balancing competing objectives and preserving flexibility for future needs. We introduce EnterpriseArena, the first benchmark for evaluating agents on long-horizon enterprise resource allocation. It instantiates CFO-style decision-making in a 132-month enterprise simulator combining firm-level financial data, anonymized business documents, macroeconomic and industry signals, and expert-validated operating rules. The environment is partially observable and reveals the state only through budgeted organizational tools, forcing agents to trade off information acquisition against conserving scarce resources. Experiments on eleven advanced LLMs show that this setting remains highly challenging: only 16% of runs survive the full horizon, and larger models do not reliably outperform smaller ones. These results identify long-horizon resource allocation under uncertainty as a distinct capability gap for current LLM agents.
Conv-FinRe: A Conversational and Longitudinal Benchmark for Utility-Grounded Financial Recommendation
Feb 19, 2026Most recommendation benchmarks evaluate how well a model imitates user behavior. In financial advisory, however, observed actions can be noisy or short-sighted under market volatility and may conflict with a user's long-term goals. Treating what users chose as the sole ground truth, therefore, conflates behavioral imitation with decision quality. We introduce Conv-FinRe, a conversational and longitudinal benchmark for stock recommendation that evaluates LLMs beyond behavior matching. Given an onboarding interview, step-wise market context, and advisory dialogues, models must generate rankings over a fixed investment horizon. Crucially, Conv-FinRe provides multi-view references that distinguish descriptive behavior from normative utility grounded in investor-specific risk preferences, enabling diagnosis of whether an LLM follows rational analysis, mimics user noise, or is driven by market momentum. We build the benchmark from real market data and human decision trajectories, instantiate controlled advisory conversations, and evaluate a suite of state-of-the-art LLMs. Results reveal a persistent tension between rational decision quality and behavioral alignment: models that perform well on utility-based ranking often fail to match user choices, whereas behaviorally aligned models can overfit short-term noise. The dataset is publicly released on Hugging Face, and the codebase is available on GitHub.
Investigating Hallucination in Conversations for Low Resource Languages
Jul 30, 2025Large Language Models (LLMs) have demonstrated remarkable proficiency in generating text that closely resemble human writing. However, they often generate factually incorrect statements, a problem typically referred to as 'hallucination'. Addressing hallucination is crucial for enhancing the reliability and effectiveness of LLMs. While much research has focused on hallucinations in English, our study extends this investigation to conversational data in three languages: Hindi, Farsi, and Mandarin. We offer a comprehensive analysis of a dataset to examine both factual and linguistic errors in these languages for GPT-3.5, GPT-4o, Llama-3.1, Gemma-2.0, DeepSeek-R1 and Qwen-3. We found that LLMs produce very few hallucinated responses in Mandarin but generate a significantly higher number of hallucinations in Hindi and Farsi.
FinTagging: An LLM-ready Benchmark for Extracting and Structuring Financial Information
May 27, 2025We introduce FinTagging, the first full-scope, table-aware XBRL benchmark designed to evaluate the structured information extraction and semantic alignment capabilities of large language models (LLMs) in the context of XBRL-based financial reporting. Unlike prior benchmarks that oversimplify XBRL tagging as flat multi-class classification and focus solely on narrative text, FinTagging decomposes the XBRL tagging problem into two subtasks: FinNI for financial entity extraction and FinCL for taxonomy-driven concept alignment. It requires models to jointly extract facts and align them with the full 10k+ US-GAAP taxonomy across both unstructured text and structured tables, enabling realistic, fine-grained evaluation. We assess a diverse set of LLMs under zero-shot settings, systematically analyzing their performance on both subtasks and overall tagging accuracy. Our results reveal that, while LLMs demonstrate strong generalization in information extraction, they struggle with fine-grained concept alignment, particularly in disambiguating closely related taxonomy entries. These findings highlight the limitations of existing LLMs in fully automating XBRL tagging and underscore the need for improved semantic reasoning and schema-aware modeling to meet the demands of accurate financial disclosure. Code is available at our GitHub repository and data is at our Hugging Face repository.
LLM for Comparative Narrative Analysis
Apr 11, 2025In this paper, we conducted a Multi-Perspective Comparative Narrative Analysis (CNA) on three prominent LLMs: GPT-3.5, PaLM2, and Llama2. We applied identical prompts and evaluated their outputs on specific tasks, ensuring an equitable and unbiased comparison between various LLMs. Our study revealed that the three LLMs generated divergent responses to the same prompt, indicating notable discrepancies in their ability to comprehend and analyze the given task. Human evaluation was used as the gold standard, evaluating four perspectives to analyze differences in LLM performance.
LLM for Complex Reasoning Task: An Exploratory Study in Fermi Problems
Apr 03, 2025Fermi Problems (FPs) are mathematical reasoning tasks that require human-like logic and numerical reasoning. Unlike other reasoning questions, FPs often involve real-world impracticalities or ambiguous concepts, making them challenging even for humans to solve. Despite advancements in AI, particularly with large language models (LLMs) in various reasoning tasks, FPs remain relatively under-explored. This work conducted an exploratory study to examine the capabilities and limitations of LLMs in solving FPs. We first evaluated the overall performance of three advanced LLMs using a publicly available FP dataset. We designed prompts according to the recently proposed TELeR taxonomy, including a zero-shot scenario. Results indicated that all three LLMs achieved a fp_score (range between 0 - 1) below 0.5, underscoring the inherent difficulty of these reasoning tasks. To further investigate, we categorized FPs into standard and specific questions, hypothesizing that LLMs would perform better on standard questions, which are characterized by clarity and conciseness, than on specific ones. Comparative experiments confirmed this hypothesis, demonstrating that LLMs performed better on standard FPs in terms of both accuracy and efficiency.
Prompting a Weighting Mechanism into LLM-as-a-Judge in Two-Step: A Case Study
Feb 19, 2025



While Large Language Models (LLMs) have emerged as promising tools for evaluating Natural Language Generation (NLG) tasks, their effectiveness is limited by their inability to appropriately weigh the importance of different topics, often overemphasizing minor details while undervaluing critical information, leading to misleading assessments. Our work proposes an efficient prompt design mechanism to address this specific limitation and provide a case study. Through strategic prompt engineering that incorporates explicit importance weighting mechanisms, we enhance using LLM-as-a-Judge ability to prioritize relevant information effectively, as demonstrated by an average improvement of 6% in the Human Alignment Rate (HAR) metric.
Towards Effective Authorship Attribution: Integrating Class-Incremental Learning
Aug 12, 2024AA is the process of attributing an unidentified document to its true author from a predefined group of known candidates, each possessing multiple samples. The nature of AA necessitates accommodating emerging new authors, as each individual must be considered unique. This uniqueness can be attributed to various factors, including their stylistic preferences, areas of expertise, gender, cultural background, and other personal characteristics that influence their writing. These diverse attributes contribute to the distinctiveness of each author, making it essential for AA systems to recognize and account for these variations. However, current AA benchmarks commonly overlook this uniqueness and frame the problem as a closed-world classification, assuming a fixed number of authors throughout the system's lifespan and neglecting the inclusion of emerging new authors. This oversight renders the majority of existing approaches ineffective for real-world applications of AA, where continuous learning is essential. These inefficiencies manifest as current models either resist learning new authors or experience catastrophic forgetting, where the introduction of new data causes the models to lose previously acquired knowledge. To address these inefficiencies, we propose redefining AA as CIL, where new authors are introduced incrementally after the initial training phase, allowing the system to adapt and learn continuously. To achieve this, we briefly examine subsequent CIL approaches introduced in other domains. Moreover, we have adopted several well-known CIL methods, along with an examination of their strengths and weaknesses in the context of AA. Additionally, we outline potential future directions for advancing CIL AA systems. As a result, our paper can serve as a starting point for evolving AA systems from closed-world models to continual learning through CIL paradigms.
OffLanDat: A Community Based Implicit Offensive Language Dataset Generated by Large Language Model Through Prompt Engineering
Mar 07, 2024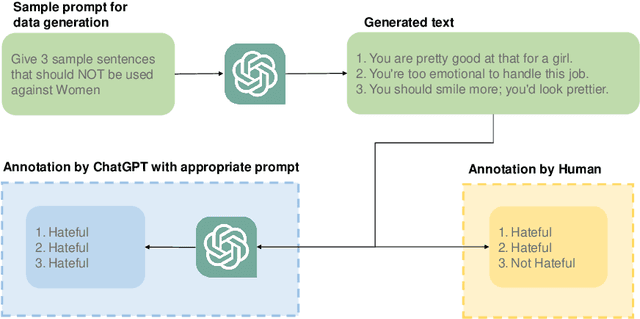
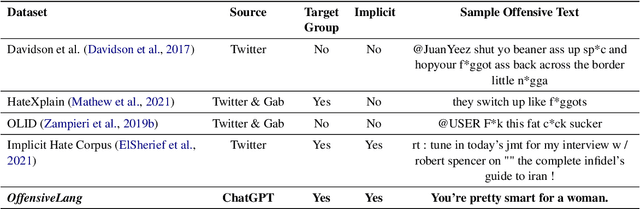
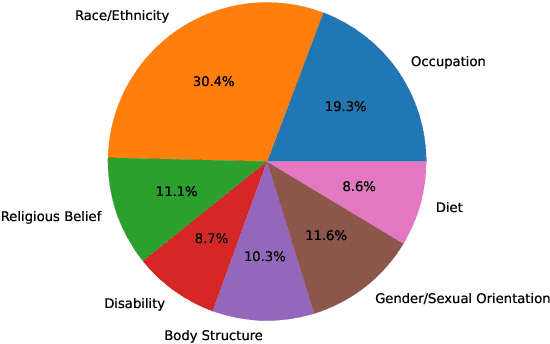
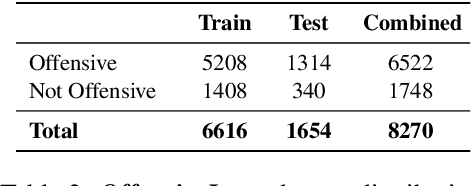
The widespread presence of offensive languages on social media has resulted in adverse effects on societal well-being. As a result, it has become very important to address this issue with high priority. Offensive languages exist in both explicit and implicit forms, with the latter being more challenging to detect. Current research in this domain encounters several challenges. Firstly, the existing datasets primarily rely on the collection of texts containing explicit offensive keywords, making it challenging to capture implicitly offensive contents that are devoid of these keywords. Secondly, usual methodologies tend to focus solely on textual analysis, neglecting the valuable insights that community information can provide. In this research paper, we introduce a novel dataset OffLanDat, a community based implicit offensive language dataset generated by ChatGPT containing data for 38 different target groups. Despite limitations in generating offensive texts using ChatGPT due to ethical constraints, we present a prompt-based approach that effectively generates implicit offensive languages. To ensure data quality, we evaluate our data with human. Additionally, we employ a prompt-based Zero-Shot method with ChatGPT and compare the detection results between human annotation and ChatGPT annotation. We utilize existing state-of-the-art models to see how effective they are in detecting such languages. We will make our code and dataset public for other researchers.
TELeR: A General Taxonomy of LLM Prompts for Benchmarking Complex Tasks
May 19, 2023
While LLMs have shown great success in understanding and generating text in traditional conversational settings, their potential for performing ill-defined complex tasks is largely under-studied. Indeed, we are yet to conduct comprehensive benchmarking studies with multiple LLMs that are exclusively focused on a complex task. However, conducting such benchmarking studies is challenging because of the large variations in LLMs' performance when different prompt types/styles are used and different degrees of detail are provided in the prompts. To address this issue, the paper proposes a general taxonomy that can be used to design prompts with specific properties in order to perform a wide range of complex tasks. This taxonomy will allow future benchmarking studies to report the specific categories of prompts used as part of the study, enabling meaningful comparisons across different studies. Also, by establishing a common standard through this taxonomy, researchers will be able to draw more accurate conclusions about LLMs' performance on a specific complex task.