 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective Authorship Attribution: Integrating Class-Incremental Learning
Aug 12, 2024AA is the process of attributing an unidentified document to its true author from a predefined group of known candidates, each possessing multiple samples. The nature of AA necessitates accommodating emerging new authors, as each individual must be considered unique. This uniqueness can be attributed to various factors, including their stylistic preferences, areas of expertise, gender, cultural background, and other personal characteristics that influence their writing. These diverse attributes contribute to the distinctiveness of each author, making it essential for AA systems to recognize and account for these variations. However, current AA benchmarks commonly overlook this uniqueness and frame the problem as a closed-world classification, assuming a fixed number of authors throughout the system's lifespan and neglecting the inclusion of emerging new authors. This oversight renders the majority of existing approaches ineffective for real-world applications of AA, where continuous learning is essential. These inefficiencies manifest as current models either resist learning new authors or experience catastrophic forgetting, where the introduction of new data causes the models to lose previously acquired knowledge. To address these inefficiencies, we propose redefining AA as CIL, where new authors are introduced incrementally after the initial training phase, allowing the system to adapt and learn continuously. To achieve this, we briefly examine subsequent CIL approaches introduced in other domains. Moreover, we have adopted several well-known CIL methods, along with an examination of their strengths and weaknesses in the context of AA. Additionally, we outline potential future directions for advancing CIL AA systems. As a result, our paper can serve as a starting point for evolving AA systems from closed-world models to continual learning through CIL paradigms.
Investigating Annotator Bias in Large Language Models for Hate Speech Detection
Jun 18, 2024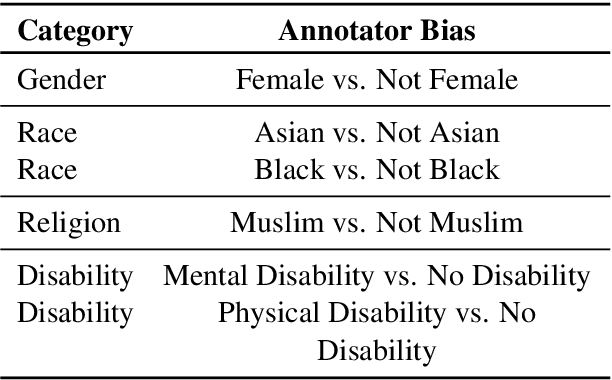
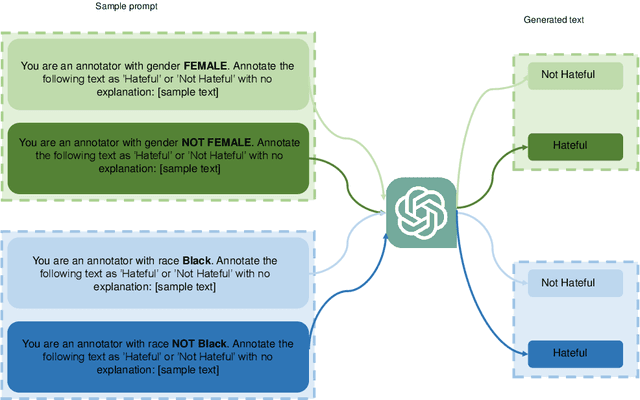
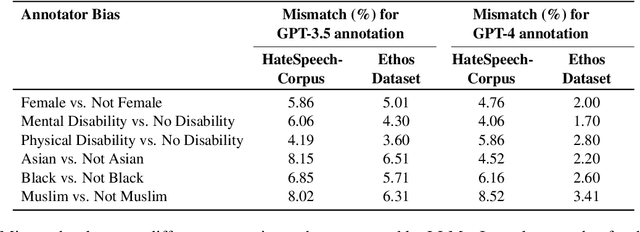
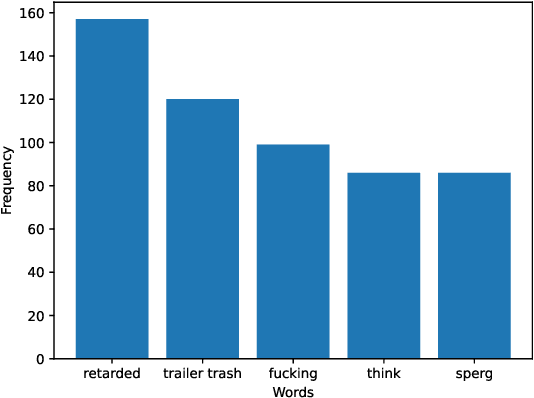
Data annotation, the practice of assigning descriptive labels to raw data, is pivotal in optimizing the performance of machine learning models. However, it is a resource-intensive process susceptible to biases introduced by annotators. The emergence of sophisticated Large Language Models (LLMs), like ChatGPT presents a unique opportunity to modernize and streamline this complex procedure. While existing research extensively evaluates the efficacy of LLMs, as annotators, this paper delves into the biases present in LLMs, specifically GPT 3.5 and GPT 4o when annotating hate speech data. Our research contributes to understanding biases in four key categories: gender, race, religion, and disability. Specifically targeting highly vulnerable groups within these categories, we analyze annotator biases. Furthermore, we conduct a comprehensive examination of potential factors contributing to these biases by scrutinizing the annotated data. We introduce our custom hate speech detection dataset, HateSpeechCorpus, to conduct this research. Additionally, we perform the same experiments on the ETHOS (Mollas et al., 2022) dataset also for comparative analysis. This paper serves as a crucial resource, guiding researchers and practitioners in harnessing the potential of LLMs for dataannotation, thereby fostering advancements in this critical field. The HateSpeechCorpus dataset is available here: https://github.com/AmitDasRup123/HateSpeechCorpus
OffLanDat: A Community Based Implicit Offensive Language Dataset Generated by Large Language Model Through Prompt Engineering
Mar 07, 2024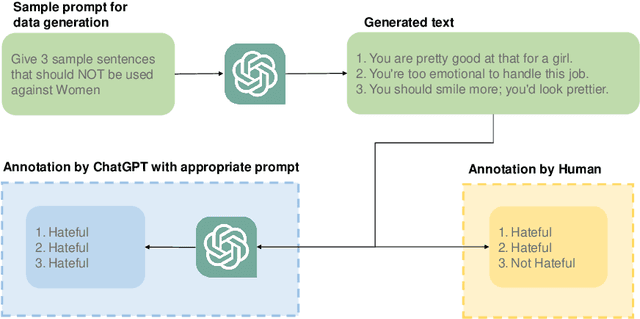
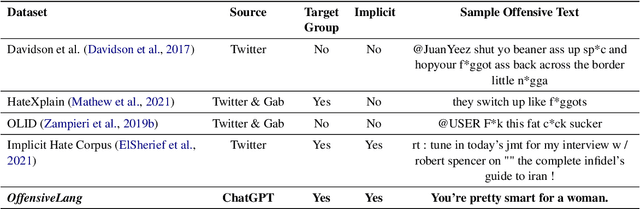
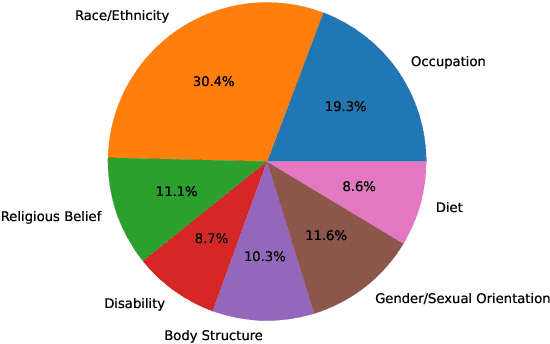
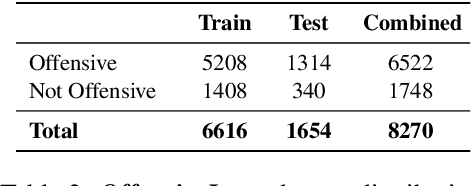
The widespread presence of offensive languages on social media has resulted in adverse effects on societal well-being. As a result, it has become very important to address this issue with high priority. Offensive languages exist in both explicit and implicit forms, with the latter being more challenging to detect. Current research in this domain encounters several challenges. Firstly, the existing datasets primarily rely on the collection of texts containing explicit offensive keywords, making it challenging to capture implicitly offensive contents that are devoid of these keywords. Secondly, usual methodologies tend to focus solely on textual analysis, neglecting the valuable insights that community information can provide. In this research paper, we introduce a novel dataset OffLanDat, a community based implicit offensive language dataset generated by ChatGPT containing data for 38 different target groups. Despite limitations in generating offensive texts using ChatGPT due to ethical constraints, we present a prompt-based approach that effectively generates implicit offensive languages. To ensure data quality, we evaluate our data with human. Additionally, we employ a prompt-based Zero-Shot method with ChatGPT and compare the detection results between human annotation and ChatGPT annotation. We utilize existing state-of-the-art models to see how effective they are in detecting such languages. We will make our code and dataset public for other researchers.
Automating Defense Against Adversarial Attacks: Discovery of Vulnerabilities and Application of Multi-INT Imagery to Protect Deployed Models
Mar 29, 2021
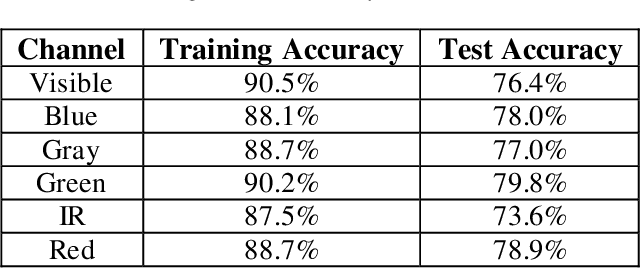


Image classification is a common step in image recognition for machine learning in overhead applications. When applying popular model architectures like MobileNetV2, known vulnerabilities expose the model to counter-attacks, either mislabeling a known class or altering box location. This work proposes an automated approach to defend these models. We evaluate the use of multi-spectral image arrays and ensemble learners to combat adversarial attacks. The original contribution demonstrates the attack, proposes a remedy, and automates some key outcomes for protecting the model's predictions against adversaries. In rough analogy to defending cyber-networks, we combine techniques from both offensive ("red team") and defensive ("blue team") approaches, thus generating a hybrid protective outcome ("green team"). For machine learning, we demonstrate these methods with 3-color channels plus infrared for vehicles. The outcome uncovers vulnerabilities and corrects them with supplemental data inputs commonly found in overhead cases particularly.
Local Translation Services for Neglected Languages
Jan 13, 2021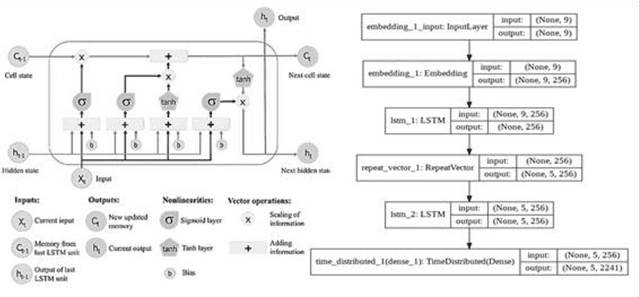
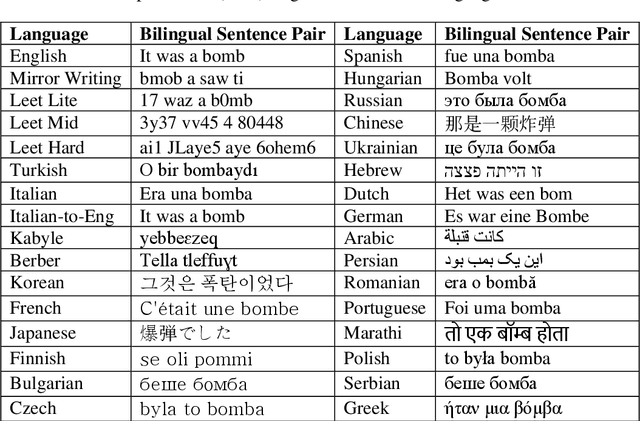
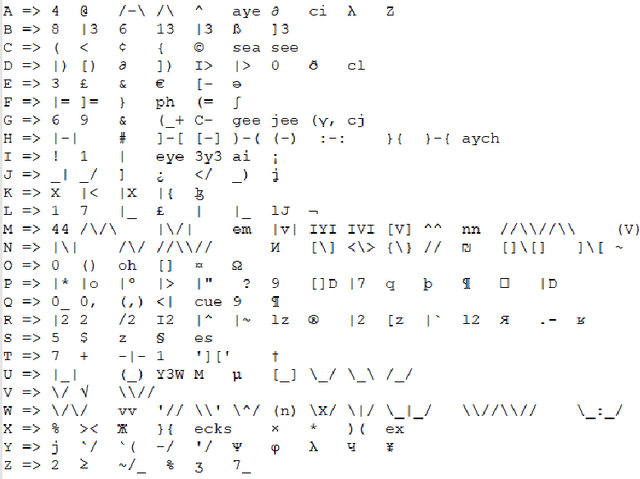
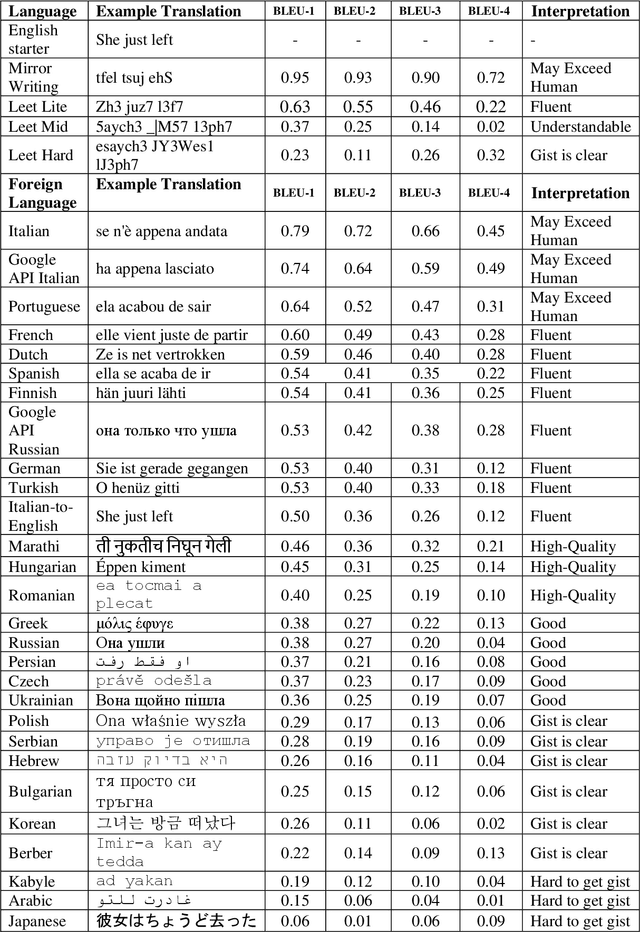
Taking advantage of computationally lightweight, but high-quality translators prompt consideration of new applications that address neglected languages. Locally run translators for less popular languages may assist data projects with protected or personal data that may require specific compliance checks before posting to a public translation API, but which could render reasonable, cost-effective solutions if done with an army of local, small-scale pair translators. Like handling a specialist's dialect, this research illustrates translating two historically interesting, but obfuscated languages: 1) hacker-speak ("l33t") and 2) reverse (or "mirror") writing as practiced by Leonardo da Vinci. The work generalizes a deep learning architecture to translatable variants of hacker-speak with lite, medium, and hard vocabularies. The original contribution highlights a fluent translator of hacker-speak in under 50 megabytes and demonstrates a generator for augmenting future datasets with greater than a million bilingual sentence pairs. The long short-term memory, recurrent neural network (LSTM-RNN) extends previous work demonstrating an English-to-foreign translation service built from as little as 10,000 bilingual sentence pairs. This work further solves the equivalent translation problem in twenty-six additional (non-obfuscated) languages and rank orders those models and their proficiency quantitatively with Italian as the most successful and Mandarin Chinese as the most challenging. For neglected languages, the method prototypes novel services for smaller niche translations such as Kabyle (Algerian dialect) which covers between 5-7 million speakers but one which for most enterprise translators, has not yet reached development. One anticipates the extension of this approach to other important dialects, such as translating technical (medical or legal) jargon and processing health records.
Black Box to White Box: Discover Model Characteristics Based on Strategic Probing
Sep 07, 2020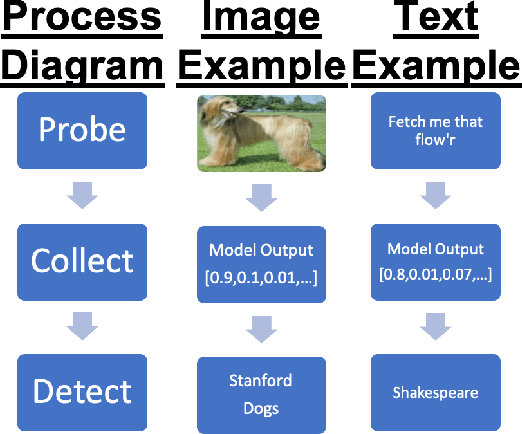
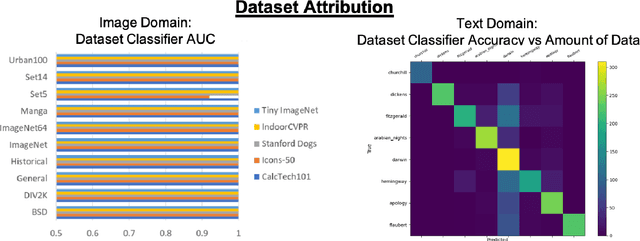
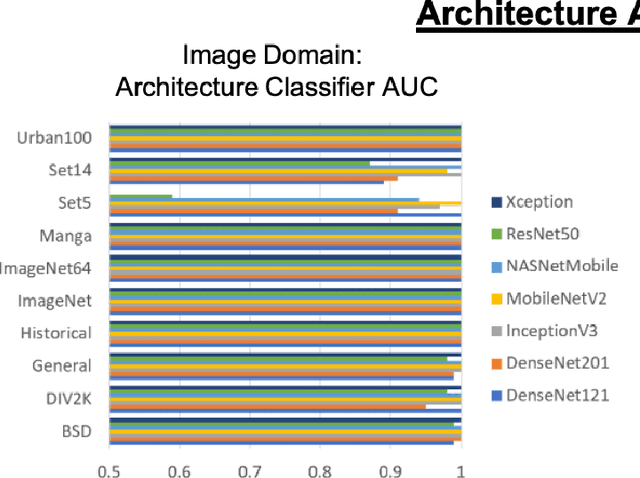
In Machine Learning, White Box Adversarial Attacks rely on knowing underlying knowledge about the model attributes. This works focuses on discovering to distrinct pieces of model information: the underlying architecture and primary training dataset. With the process in this paper, a structured set of input probes and the output of the model become the training data for a deep classifier. Two subdomains in Machine Learning are explored: image based classifiers and text transformers with GPT-2. With image classification, the focus is on exploring commonly deployed architectures and datasets available in popular public libraries. Using a single transformer architecture with multiple levels of parameters, text generation is explored by fine tuning off different datasets. Each dataset explored in image and text are distinguishable from one another. Diversity in text transformer outputs implies further research is needed to successfully classify architecture attribution in text domain.
Systematic Attack Surface Reduction For Deployed Sentiment Analysis Models
Jun 19, 2020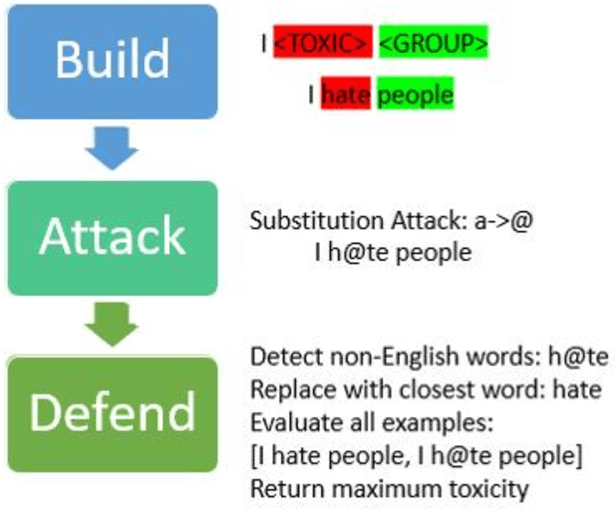
This work proposes a structured approach to baselining a model, identifying attack vectors, and securing the machine learning models after deployment. This method for securing each model post deployment is called the BAD (Build, Attack, and Defend) Architecture. Two implementations of the BAD architecture are evaluated to quantify the adversarial life cycle for a black box Sentiment Analysis system. As a challenging diagnostic, the Jigsaw Toxic Bias dataset is selected as the baseline in our performance tool. Each implementation of the architecture will build a baseline performance report, attack a common weakness, and defend the incoming attack. As an important note: each attack surface demonstrated in this work is detectable and preventable. The goal is to demonstrate a viable methodology for securing a machine learning model in a production setting.