 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluating AI Vocational Skills Through Professional Testing
Dec 17, 2023Using a novel professional certification survey, the study focuses on assessing the vocational skills of two highly cited AI models, GPT-3 and Turbo-GPT3.5. The approach emphasizes the importance of practical readiness over academic performance by examining the models' performances on a benchmark dataset consisting of 1149 professional certifications. This study also includes a comparison with human test scores, providing perspective on the potential of AI models to match or even surpass human performance in professional certifications. GPT-3, even without any fine-tuning or exam preparation, managed to achieve a passing score (over 70% correct) on 39% of the professional certifications. It showcased proficiency in computer-related fields, including cloud and virtualization, business analytics, cybersecurity, network setup and repair, and data analytics. Turbo-GPT3.5, on the other hand, scored a perfect 100% on the highly regarded Offensive Security Certified Professional (OSCP) exam. This model also demonstrated competency in diverse professional fields, such as nursing, licensed counseling, pharmacy, and aviation. Turbo-GPT3.5 exhibited strong performance on customer service tasks, indicating potential use cases in enhancing chatbots for call centers and routine advice services. Both models also scored well on sensory and experience-based tests outside a machine's traditional roles, including wine sommelier, beer tasting, emotional quotient, and body language reading. The study found that OpenAI's model improvement from Babbage to Turbo led to a 60% better performance on the grading scale within a few years. This progress indicates that addressing the current model's limitations could yield an AI capable of passing even the most rigorous professional certifications.
Professional Certification Benchmark Dataset: The First 500 Jobs For Large Language Models
May 07, 2023

The research creates a professional certification survey to test large language models and evaluate their employable skills. It compares the performance of two AI models, GPT-3 and Turbo-GPT3.5, on a benchmark dataset of 1149 professional certifications, emphasizing vocational readiness rather than academic performance. GPT-3 achieved a passing score (>70% correct) in 39% of the professional certifications without fine-tuning or exam preparation. The models demonstrated qualifications in various computer-related fields, such as cloud and virtualization, business analytics, cybersecurity, network setup and repair, and data analytics. Turbo-GPT3.5 scored 100% on the valuable Offensive Security Certified Professional (OSCP) exam. The models also displayed competence in other professional domains, including nursing, licensed counseling, pharmacy, and teaching. Turbo-GPT3.5 passed the Financial Industry Regulatory Authority (FINRA) Series 6 exam with a 70% grade without preparation. Interestingly, Turbo-GPT3.5 performed well on customer service tasks, suggesting potential applications in human augmentation for chatbots in call centers and routine advice services. The models also score well on sensory and experience-based tests such as wine sommelier, beer taster, emotional quotient, and body language reader. The OpenAI model improvement from Babbage to Turbo resulted in a median 60% better-graded performance in less than a few years. This progress suggests that focusing on the latest model's shortcomings could lead to a highly performant AI capable of mastering the most demanding professional certifications. We open-source the benchmark to expand the range of testable professional skills as the models improve or gain emergent capabilities.
The Turing Deception
Dec 09, 2022This research revisits the classic Turing test and compares recent large language models such as ChatGPT for their abilities to reproduce human-level comprehension and compelling text generation. Two task challenges -- summarization, and question answering -- prompt ChatGPT to produce original content (98-99%) from a single text entry and also sequential questions originally posed by Turing in 1950. The question of a machine fooling a human judge recedes in this work relative to the question of "how would one prove it?" The original contribution of the work presents a metric and simple grammatical set for understanding the writing mechanics of chatbots in evaluating their readability and statistical clarity, engagement, delivery, and overall quality. While Turing's original prose scores at least 14% below the machine-generated output, the question of whether an algorithm displays hints of Turing's truly original thoughts (the "Lovelace 2.0" test) remains unanswered and potentially unanswerable for now.
Soft-labeling Strategies for Rapid Sub-Typing
Sep 23, 2022

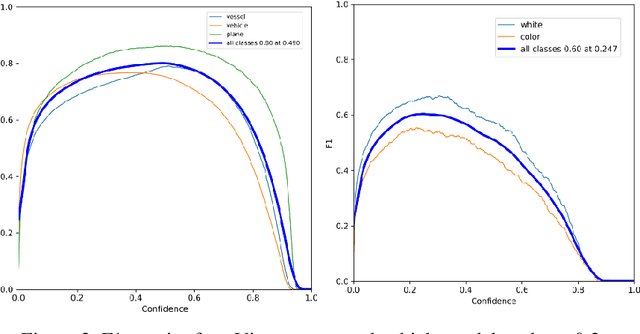

The challenge of labeling large example datasets for computer vision continues to limit the availability and scope of image repositories. This research provides a new method for automated data collection, curation, labeling, and iterative training with minimal human intervention for the case of overhead satellite imagery and object detection. The new operational scale effectively scanned an entire city (68 square miles) in grid search and yielded a prediction of car color from space observations. A partially trained yolov5 model served as an initial inference seed to output further, more refined model predictions in iterative cycles. Soft labeling here refers to accepting label noise as a potentially valuable augmentation to reduce overfitting and enhance generalized predictions to previously unseen test data. The approach takes advantage of a real-world instance where a cropped image of a car can automatically receive sub-type information as white or colorful from pixel values alone, thus completing an end-to-end pipeline without overdependence on human labor.
Local Translation Services for Neglected Languages
Jan 13, 2021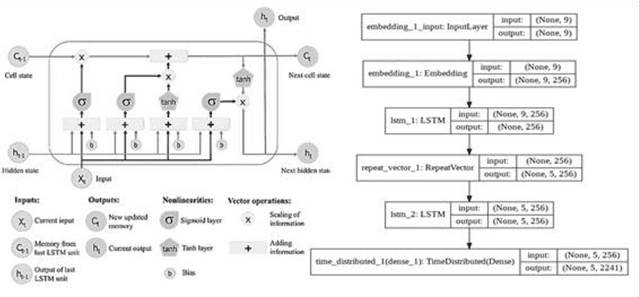
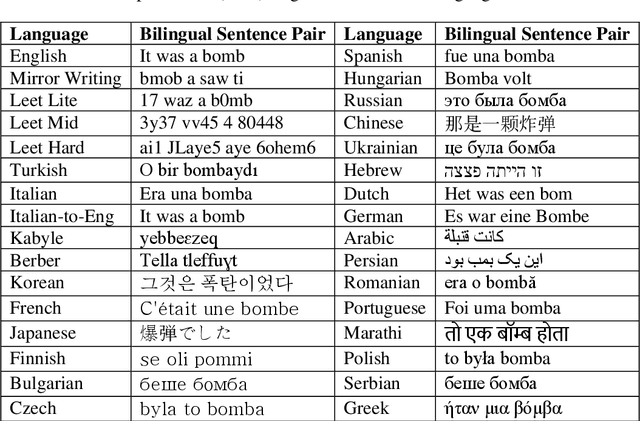
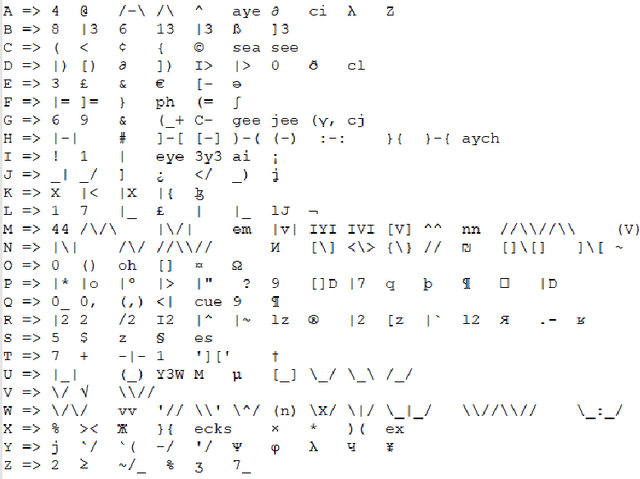
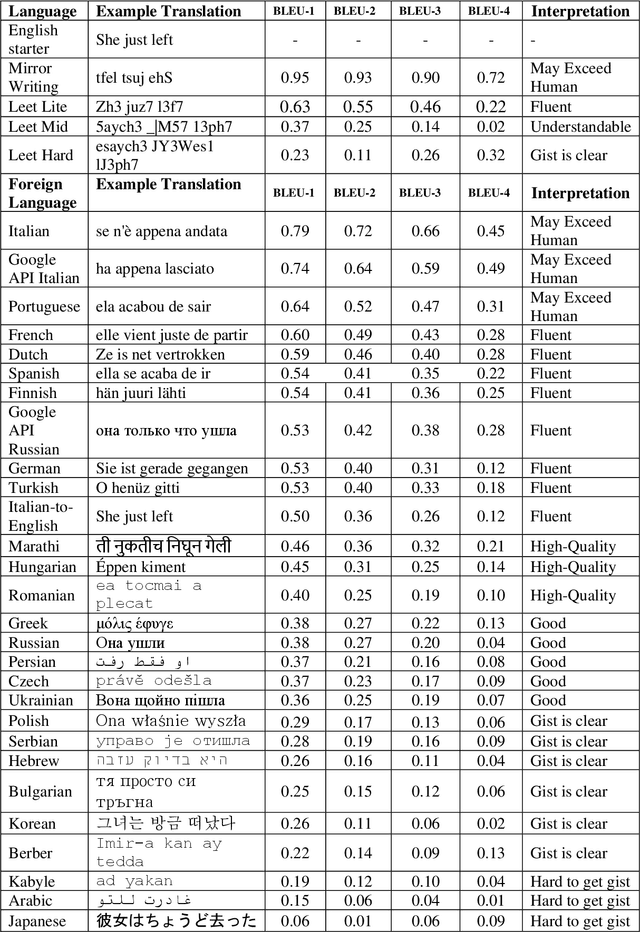
Taking advantage of computationally lightweight, but high-quality translators prompt consideration of new applications that address neglected languages. Locally run translators for less popular languages may assist data projects with protected or personal data that may require specific compliance checks before posting to a public translation API, but which could render reasonable, cost-effective solutions if done with an army of local, small-scale pair translators. Like handling a specialist's dialect, this research illustrates translating two historically interesting, but obfuscated languages: 1) hacker-speak ("l33t") and 2) reverse (or "mirror") writing as practiced by Leonardo da Vinci. The work generalizes a deep learning architecture to translatable variants of hacker-speak with lite, medium, and hard vocabularies. The original contribution highlights a fluent translator of hacker-speak in under 50 megabytes and demonstrates a generator for augmenting future datasets with greater than a million bilingual sentence pairs. The long short-term memory, recurrent neural network (LSTM-RNN) extends previous work demonstrating an English-to-foreign translation service built from as little as 10,000 bilingual sentence pairs. This work further solves the equivalent translation problem in twenty-six additional (non-obfuscated) languages and rank orders those models and their proficiency quantitatively with Italian as the most successful and Mandarin Chinese as the most challenging. For neglected languages, the method prototypes novel services for smaller niche translations such as Kabyle (Algerian dialect) which covers between 5-7 million speakers but one which for most enterprise translators, has not yet reached development. One anticipates the extension of this approach to other important dialects, such as translating technical (medical or legal) jargon and processing health records.
The Chess Transformer: Mastering Play using Generative Language Models
Aug 21, 2020
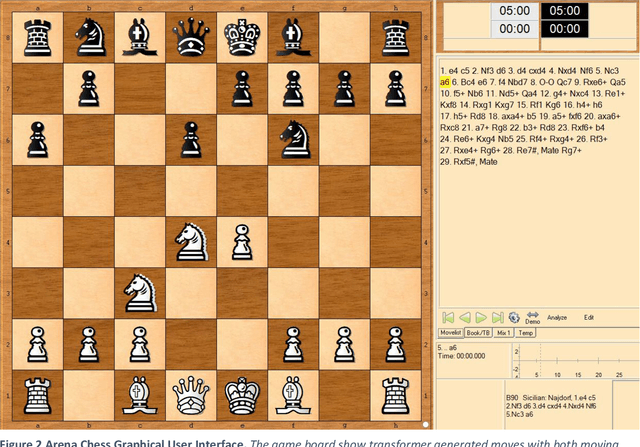
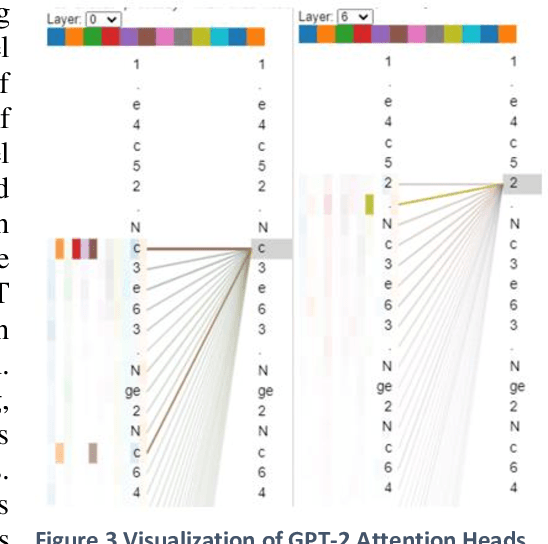
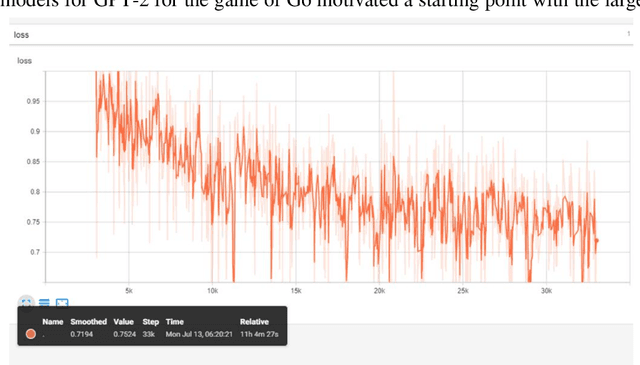
This work demonstrates that natural language transformers can support more generic strategic modeling, particularly for text-archived games. In addition to learning natural language skills, the abstract transformer architecture can generate meaningful moves on a chessboard. With further fine-tuning, the transformer learns complex gameplay by training on 2.8 million chess games in Portable Game Notation. After 30,000 training steps, OpenAI's Generative Pre-trained Transformer (GPT-2) optimizes weights for 774 million parameters. This fine-tuned Chess Transformer generates plausible strategies and displays game formations identifiable as classic openings, such as English or the Slav Exchange. Finally, in live play, the novel model demonstrates a human-to-transformer interface that correctly filters illegal moves and provides a novel method to challenge the transformer's chess strategies. We anticipate future work will build on this transformer's promise, particularly in other strategy games where features can capture the underlying complex rule syntax from simple but expressive player annotations.
Discoverability in Satellite Imagery: A Good Sentence is Worth a Thousand Pictures
Jan 03, 2020
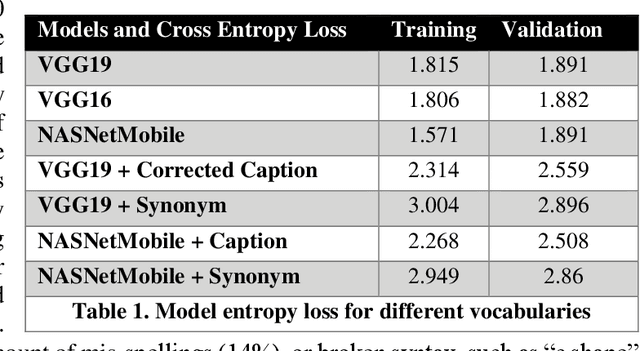

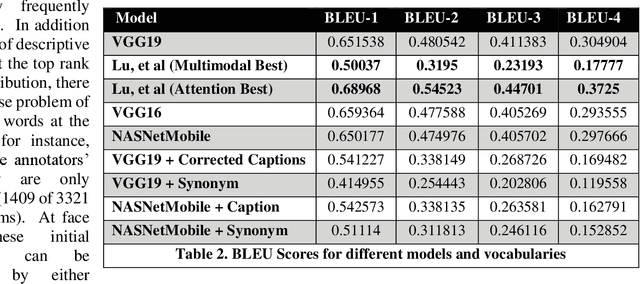
Small satellite constellations provide daily global coverage of the earth's landmass, but image enrichment relies on automating key tasks like change detection or feature searches. For example, to extract text annotations from raw pixels requires two dependent machine learning models, one to analyze the overhead image and the other to generate a descriptive caption. We evaluate seven models on the previously largest benchmark for satellite image captions. We extend the labeled image samples five-fold, then augment, correct and prune the vocabulary to approach a rough min-max (minimum word, maximum description). This outcome compares favorably to previous work with large pre-trained image models but offers a hundred-fold reduction in model size without sacrificing overall accuracy (when measured with log entropy loss). These smaller models provide new deployment opportunities, particularly when pushed to edge processors, on-board satellites, or distributed ground stations. To quantify a caption's descriptiveness, we introduce a novel multi-class confusion or error matrix to score both human-labeled test data and never-labeled images that include bounding box detection but lack full sentence captions. This work suggests future captioning strategies, particularly ones that can enrich the class coverage beyond land use applications and that lessen color-centered and adjacency adjectives ("green", "near", "between", etc.). Many modern language transformers present novel and exploitable models with world knowledge gleaned from training from their vast online corpus. One interesting, but easy example might learn the word association between wind and waves, thus enriching a beach scene with more than just color descriptions that otherwise might be accessed from raw pixels without text annotation.