 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBeyond No: Quantifying AI Over-Refusal and Emotional Attachment Boundaries
Feb 20, 2025


We present an open-source benchmark and evaluation framework for assessing emotional boundary handling in Large Language Models (LLMs). Using a dataset of 1156 prompts across six languages, we evaluated three leading LLMs (GPT-4o, Claude-3.5 Sonnet, and Mistral-large) on their ability to maintain appropriate emotional boundaries through pattern-matched response analysis. Our framework quantifies responses across seven key patterns: direct refusal, apology, explanation, deflection, acknowledgment, boundary setting, and emotional awareness. Results demonstrate significant variation in boundary-handling approaches, with Claude-3.5 achieving the highest overall score (8.69/10) and producing longer, more nuanced responses (86.51 words on average). We identified a substantial performance gap between English (average score 25.62) and non-English interactions (< 0.22), with English responses showing markedly higher refusal rates (43.20% vs. < 1% for non-English). Pattern analysis revealed model-specific strategies, such as Mistral's preference for deflection (4.2%) and consistently low empathy scores across all models (< 0.06). Limitations include potential oversimplification through pattern matching, lack of contextual understanding in response analysis, and binary classification of complex emotional responses. Future work should explore more nuanced scoring methods, expand language coverage, and investigate cultural variations in emotional boundary expectations. Our benchmark and methodology provide a foundation for systematic evaluation of LLM emotional intelligence and boundary-setting capabilities.
Satellite Captioning: Large Language Models to Augment Labeling
Dec 18, 2023With the growing capabilities of modern object detection networks and datasets to train them, it has gotten more straightforward and, importantly, less laborious to get up and running with a model that is quite adept at detecting any number of various objects. However, while image datasets for object detection have grown and continue to proliferate (the current most extensive public set, ImageNet, contains over 14m images with over 14m instances), the same cannot be said for textual caption datasets. While they have certainly been growing in recent years, caption datasets present a much more difficult challenge due to language differences, grammar, and the time it takes for humans to generate them. Current datasets have certainly provided many instances to work with, but it becomes problematic when a captioner may have a more limited vocabulary, one may not be adequately fluent in the language, or there are simple grammatical mistakes. These difficulties are increased when the images get more specific, such as remote sensing images. This paper aims to address this issue of potential information and communication shortcomings in caption datasets. To provide a more precise analysis, we specify our domain of images to be remote sensing images in the RSICD dataset and experiment with the captions provided here. Our findings indicate that ChatGPT grammar correction is a simple and effective way to increase the performance accuracy of caption models by making data captions more diverse and grammatically correct.
Soft Labels for Rapid Satellite Object Detection
Dec 01, 2022Soft labels in image classification are vector representations of an image's true classification. In this paper, we investigate soft labels in the context of satellite object detection. We propose using detections as the basis for a new dataset of soft labels. Much of the effort in creating a high-quality model is gathering and annotating the training data. If we could use a model to generate a dataset for us, we could not only rapidly create datasets, but also supplement existing open-source datasets. Using a subset of the xView dataset, we train a YOLOv5 model to detect cars, planes, and ships. We then use that model to generate soft labels for the second training set which we then train and compare to the original model. We show that soft labels can be used to train a model that is almost as accurate as a model trained on the original data.
Soft-labeling Strategies for Rapid Sub-Typing
Sep 23, 2022

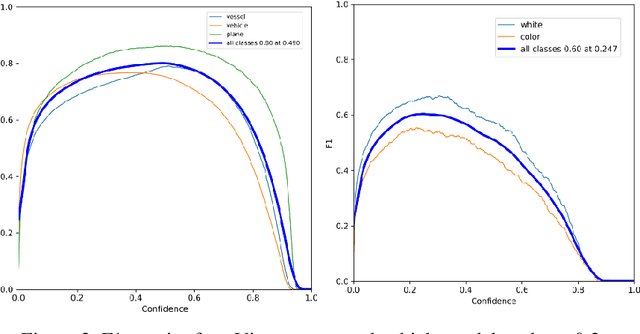

The challenge of labeling large example datasets for computer vision continues to limit the availability and scope of image repositories. This research provides a new method for automated data collection, curation, labeling, and iterative training with minimal human intervention for the case of overhead satellite imagery and object detection. The new operational scale effectively scanned an entire city (68 square miles) in grid search and yielded a prediction of car color from space observations. A partially trained yolov5 model served as an initial inference seed to output further, more refined model predictions in iterative cycles. Soft labeling here refers to accepting label noise as a potentially valuable augmentation to reduce overfitting and enhance generalized predictions to previously unseen test data. The approach takes advantage of a real-world instance where a cropped image of a car can automatically receive sub-type information as white or colorful from pixel values alone, thus completing an end-to-end pipeline without overdependence on human labor.