 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Pixels to Planes: Minimum Ground Sample Distance for Aircraft
Nov 20, 2024This study investigates the impact of ground sample distance (GSD) on the detection performance of various sized aircraft using the proprietary AllPlanes 120 dataset. The data set comprises 120 civilian, military and museum aircraft from multiple satellite/aerial sources collected over two years. Resolutions ranging from 2.4 to 0.3 meters GSD were simulated. Performance metrics were derived from a YOLOv8s model trained on down-sampled versions of zoom level 19 (0.3m GSD) imagery. The results indicate that a GSD of at least 0.86m is required to accurately detect most aircraft, particularly those with wingspans shorter than 20 meters. Due to weight constraints in high-altitude platforms, this GSD specification can inform camera design to minimize weight while maintaining detection accuracy.
Soft Labels for Rapid Satellite Object Detection
Dec 01, 2022Soft labels in image classification are vector representations of an image's true classification. In this paper, we investigate soft labels in the context of satellite object detection. We propose using detections as the basis for a new dataset of soft labels. Much of the effort in creating a high-quality model is gathering and annotating the training data. If we could use a model to generate a dataset for us, we could not only rapidly create datasets, but also supplement existing open-source datasets. Using a subset of the xView dataset, we train a YOLOv5 model to detect cars, planes, and ships. We then use that model to generate soft labels for the second training set which we then train and compare to the original model. We show that soft labels can be used to train a model that is almost as accurate as a model trained on the original data.
Image Compression and Actionable Intelligence With Deep Neural Networks
Mar 30, 2022


If a unit cannot receive intelligence from a source due to external factors, we consider them disadvantaged users. We categorize this as a preoccupied unit working on a low connectivity device on the edge. This case requires that we use a different approach to deliver intelligence, particularly satellite imagery information, than normally employed. To address this, we propose a survey of information reduction techniques to deliver the information from a satellite image in a smaller package. We investigate four techniques to aid in the reduction of delivered information: traditional image compression, neural network image compression, object detection image cutout, and image to caption. Each of these mechanisms have their benefits and tradeoffs when considered for a disadvantaged user.
Enhancing Satellite Imagery using Deep Learning for the Sensor To Shooter Timeline
Mar 30, 2022
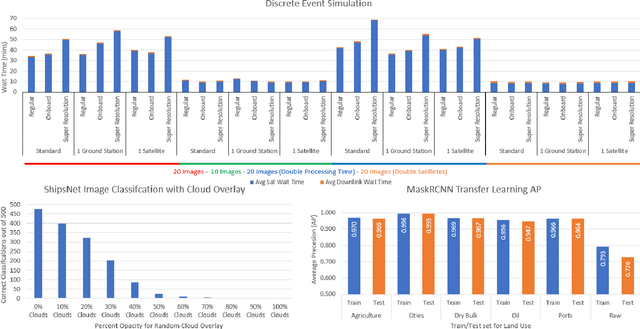

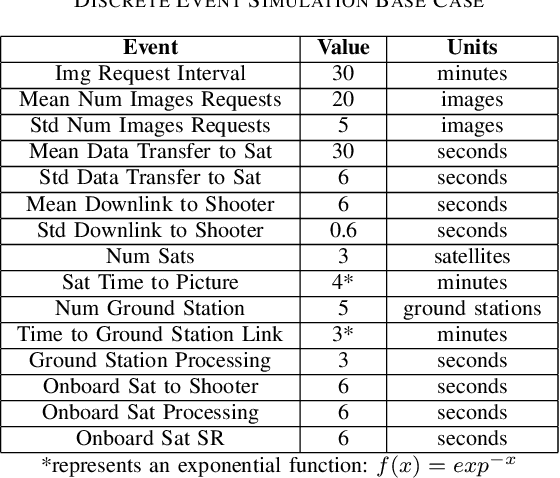
The sensor to shooter timeline is affected by two main variables: satellite positioning and asset positioning. Speeding up satellite positioning by adding more sensors or by decreasing processing time is important only if there is a prepared shooter, otherwise the main source of time is getting the shooter into position. However, the intelligence community should work towards the exploitation of sensors to the highest speed and effectiveness possible. Achieving a high effectiveness while keeping speed high is a tradeoff that must be considered in the sensor to shooter timeline. In this paper we investigate two main ideas, increasing the effectiveness of satellite imagery through image manipulation and how on-board image manipulation would affect the sensor to shooter timeline. We cover these ideas in four scenarios: Discrete Event Simulation of onboard processing versus ground station processing, quality of information with cloud cover removal, information improvement with super resolution, and data reduction with image to caption. This paper will show how image manipulation techniques such as Super Resolution, Cloud Removal, and Image to Caption will improve the quality of delivered information in addition to showing how those processes effect the sensor to shooter timeline.
Color Teams for Machine Learning Development
Oct 20, 2021
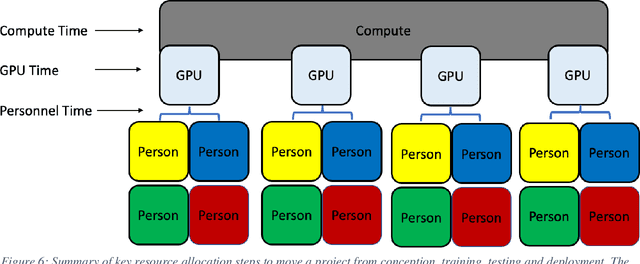
Machine learning and software development share processes and methodologies for reliably delivering products to customers. This work proposes the use of a new teaming construct for forming machine learning teams for better combatting adversarial attackers. In cybersecurity, infrastructure uses these teams to protect their systems by using system builders and programmers to also offer more robustness to their platforms. Color teams provide clear responsibility to the individuals on each team for which part of the baseline (Yellow), attack (Red), and defense (Blue) breakout of the pipeline. Combining colors leads to additional knowledge shared across the team and more robust models built during development. The responsibilities of the new teams Orange, Green, and Purple will be outlined during this paper along with an overview of the necessary resources for these teams to be successful.
Automating Defense Against Adversarial Attacks: Discovery of Vulnerabilities and Application of Multi-INT Imagery to Protect Deployed Models
Mar 29, 2021
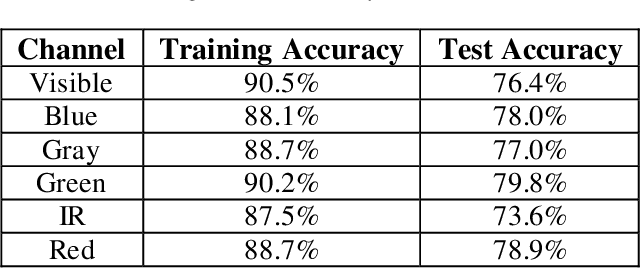


Image classification is a common step in image recognition for machine learning in overhead applications. When applying popular model architectures like MobileNetV2, known vulnerabilities expose the model to counter-attacks, either mislabeling a known class or altering box location. This work proposes an automated approach to defend these models. We evaluate the use of multi-spectral image arrays and ensemble learners to combat adversarial attacks. The original contribution demonstrates the attack, proposes a remedy, and automates some key outcomes for protecting the model's predictions against adversaries. In rough analogy to defending cyber-networks, we combine techniques from both offensive ("red team") and defensive ("blue team") approaches, thus generating a hybrid protective outcome ("green team"). For machine learning, we demonstrate these methods with 3-color channels plus infrared for vehicles. The outcome uncovers vulnerabilities and corrects them with supplemental data inputs commonly found in overhead cases particularly.
A Modified Drake Equation for Assessing Adversarial Risk to Machine Learning Models
Mar 03, 2021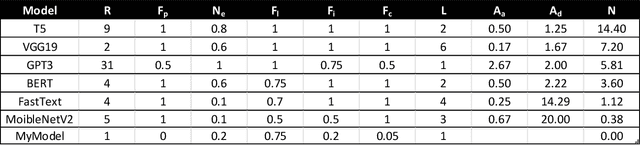
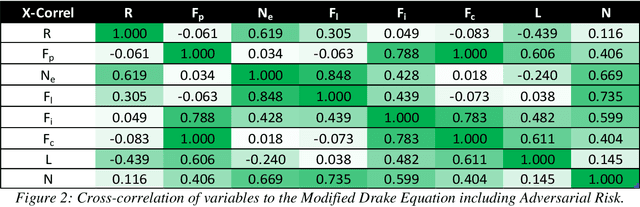
Each machine learning model deployed into production has a risk of adversarial attack. Quantifying the contributing factors and uncertainties using empirical measures could assist the industry with assessing the risk of downloading and deploying common machine learning model types. The Drake Equation is famously used for parameterizing uncertainties and estimating the number of radio-capable extra-terrestrial civilizations. This work proposes modifying the traditional Drake Equation's formalism to estimate the number of potentially successful adversarial attacks on a deployed model. While previous work has outlined methods for discovering vulnerabilities in public model architectures, the proposed equation seeks to provide a semi-quantitative benchmark for evaluating the potential risk factors of adversarial attacks.
Multilingual Augmenter: The Model Chooses
Feb 19, 2021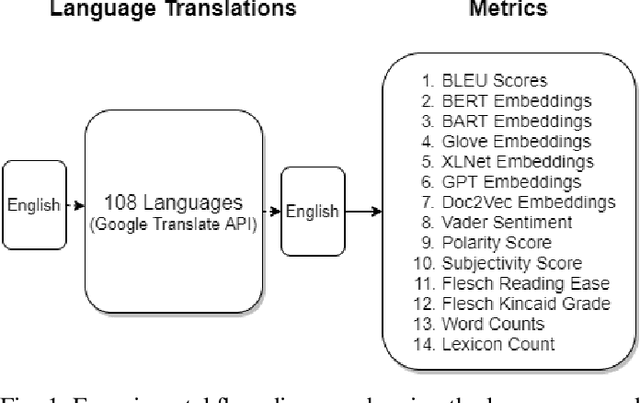



Natural Language Processing (NLP) relies heavily on training data. Transformers, as they have gotten bigger, have required massive amounts of training data. To satisfy this requirement, text augmentation should be looked at as a way to expand your current dataset and to generalize your models. One text augmentation we will look at is translation augmentation. We take an English sentence and translate it to another language before translating it back to English. In this paper, we look at the effect of 108 different language back translations on various metrics and text embeddings.
Fortify Machine Learning Production Systems: Detect and Classify Adversarial Attacks
Feb 19, 2021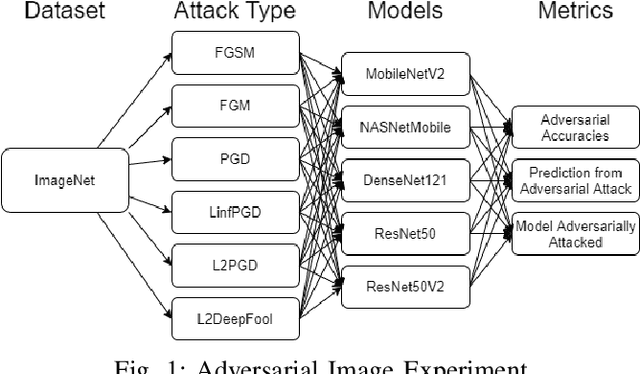
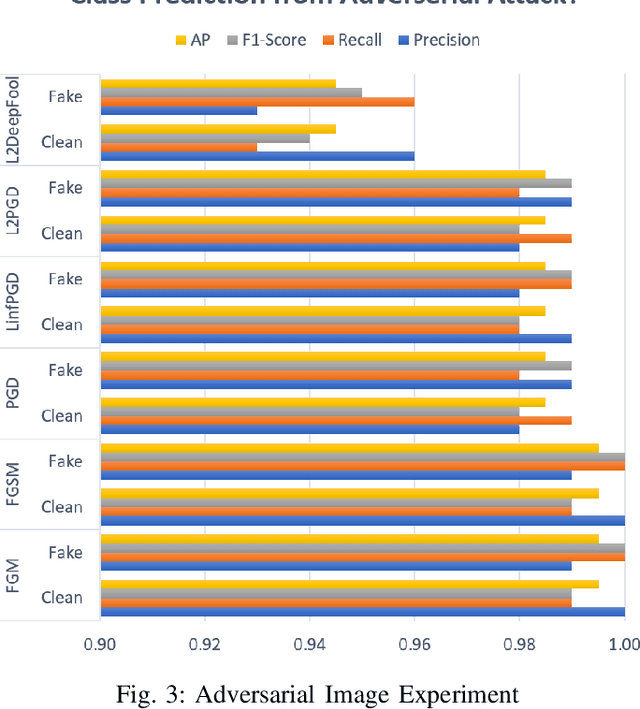
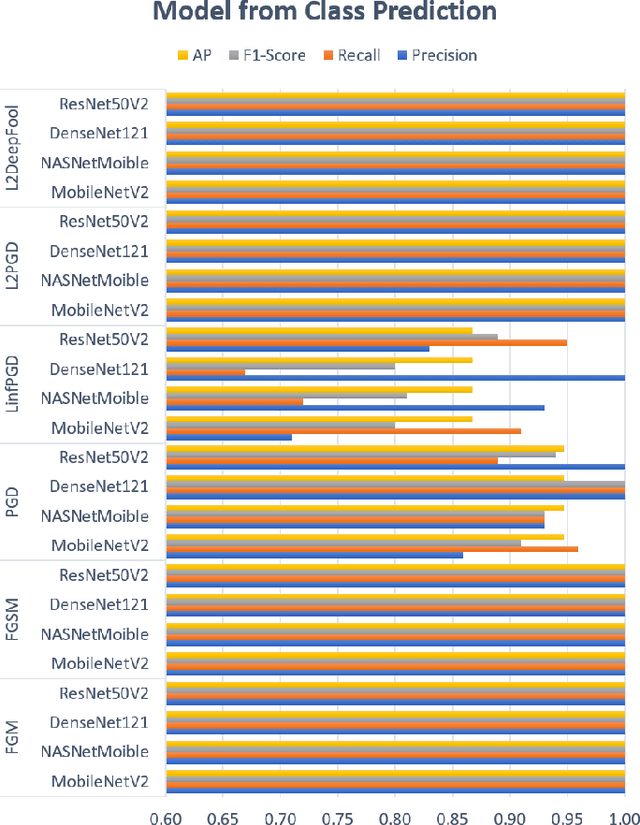
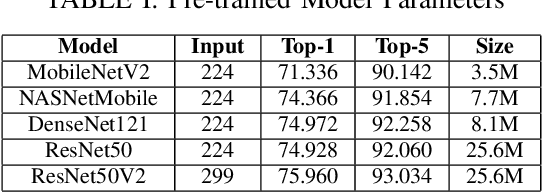
Production machine learning systems are consistently under attack by adversarial actors. Various deep learning models must be capable of accurately detecting fake or adversarial input while maintaining speed. In this work, we propose one piece of the production protection system: detecting an incoming adversarial attack and its characteristics. Detecting types of adversarial attacks has two primary effects: the underlying model can be trained in a structured manner to be robust from those attacks and the attacks can be potentially filtered out in realtime before causing any downstream damage. The adversarial image classification space is explored for models commonly used in transfer learning.
Black Box to White Box: Discover Model Characteristics Based on Strategic Probing
Sep 07, 2020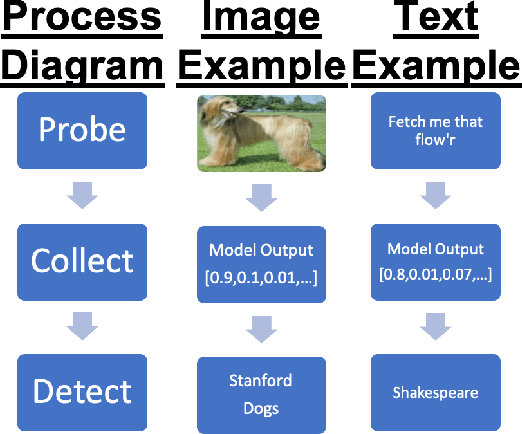
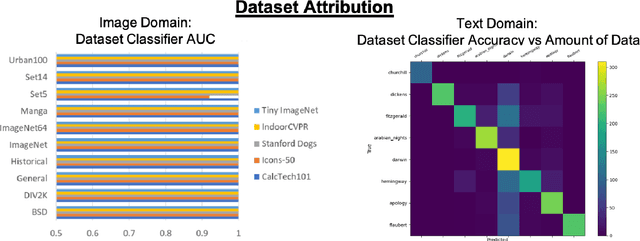
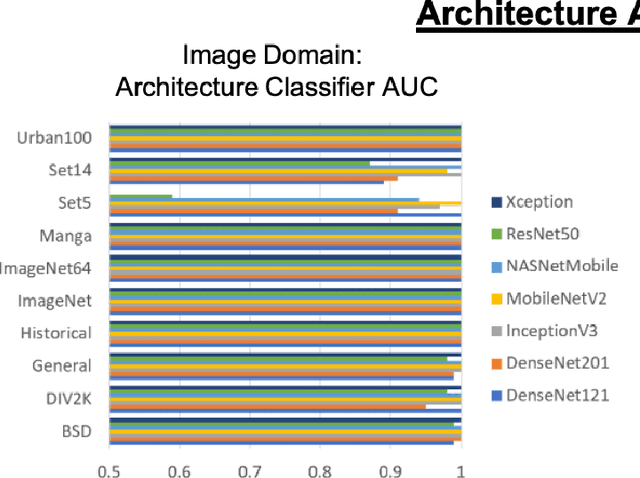
In Machine Learning, White Box Adversarial Attacks rely on knowing underlying knowledge about the model attributes. This works focuses on discovering to distrinct pieces of model information: the underlying architecture and primary training dataset. With the process in this paper, a structured set of input probes and the output of the model become the training data for a deep classifier. Two subdomains in Machine Learning are explored: image based classifiers and text transformers with GPT-2. With image classification, the focus is on exploring commonly deployed architectures and datasets available in popular public libraries. Using a single transformer architecture with multiple levels of parameters, text generation is explored by fine tuning off different datasets. Each dataset explored in image and text are distinguishable from one another. Diversity in text transformer outputs implies further research is needed to successfully classify architecture attribution in text domain.