 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeColor Teams for Machine Learning Development
Oct 20, 2021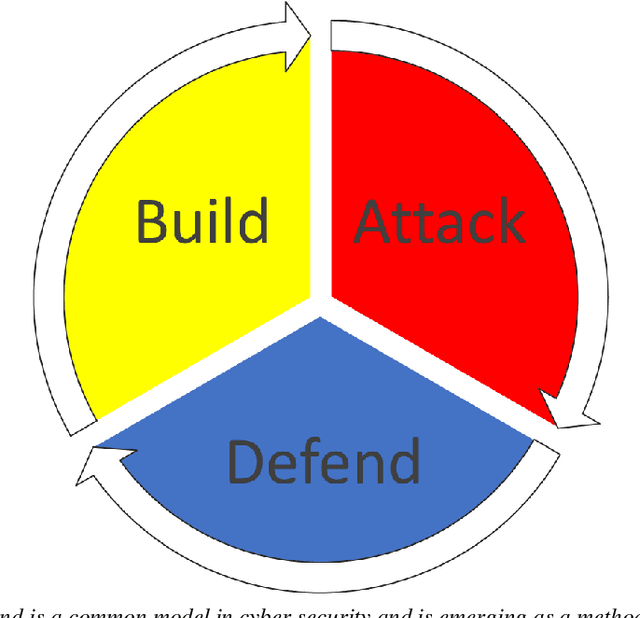
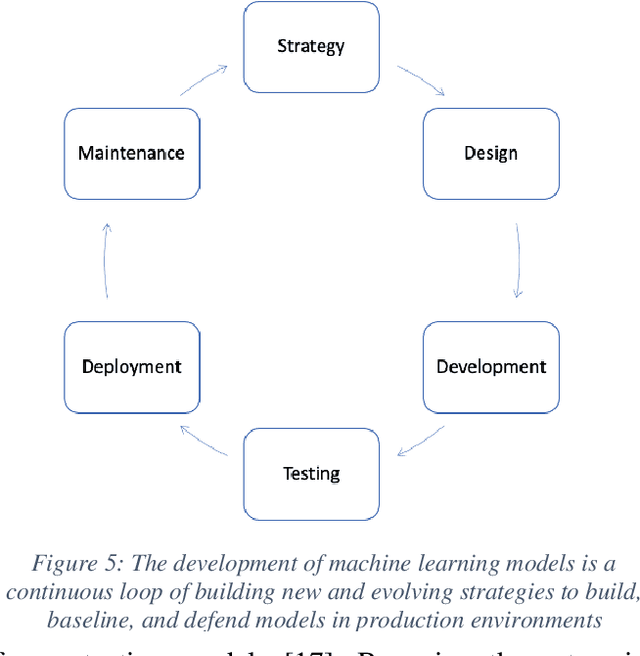
Machine learning and software development share processes and methodologies for reliably delivering products to customers. This work proposes the use of a new teaming construct for forming machine learning teams for better combatting adversarial attackers. In cybersecurity, infrastructure uses these teams to protect their systems by using system builders and programmers to also offer more robustness to their platforms. Color teams provide clear responsibility to the individuals on each team for which part of the baseline (Yellow), attack (Red), and defense (Blue) breakout of the pipeline. Combining colors leads to additional knowledge shared across the team and more robust models built during development. The responsibilities of the new teams Orange, Green, and Purple will be outlined during this paper along with an overview of the necessary resources for these teams to be successful.
Automating Defense Against Adversarial Attacks: Discovery of Vulnerabilities and Application of Multi-INT Imagery to Protect Deployed Models
Mar 29, 2021
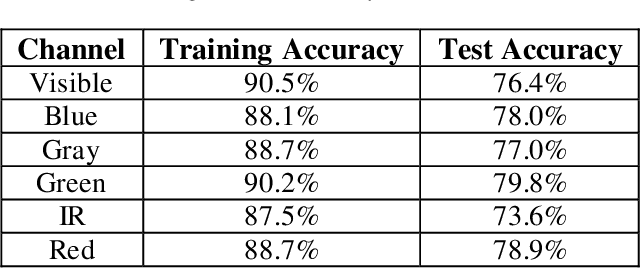


Image classification is a common step in image recognition for machine learning in overhead applications. When applying popular model architectures like MobileNetV2, known vulnerabilities expose the model to counter-attacks, either mislabeling a known class or altering box location. This work proposes an automated approach to defend these models. We evaluate the use of multi-spectral image arrays and ensemble learners to combat adversarial attacks. The original contribution demonstrates the attack, proposes a remedy, and automates some key outcomes for protecting the model's predictions against adversaries. In rough analogy to defending cyber-networks, we combine techniques from both offensive ("red team") and defensive ("blue team") approaches, thus generating a hybrid protective outcome ("green team"). For machine learning, we demonstrate these methods with 3-color channels plus infrared for vehicles. The outcome uncovers vulnerabilities and corrects them with supplemental data inputs commonly found in overhead cases particularly.
A Modified Drake Equation for Assessing Adversarial Risk to Machine Learning Models
Mar 03, 2021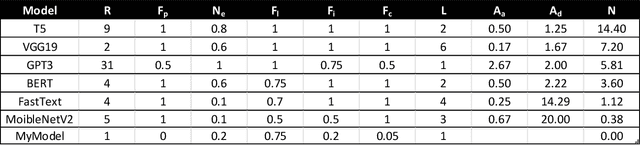
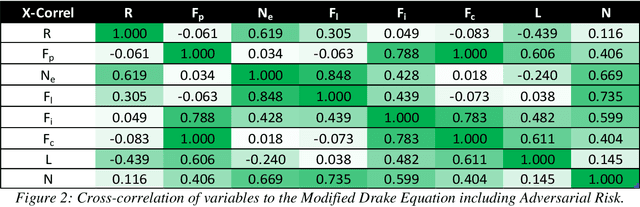
Each machine learning model deployed into production has a risk of adversarial attack. Quantifying the contributing factors and uncertainties using empirical measures could assist the industry with assessing the risk of downloading and deploying common machine learning model types. The Drake Equation is famously used for parameterizing uncertainties and estimating the number of radio-capable extra-terrestrial civilizations. This work proposes modifying the traditional Drake Equation's formalism to estimate the number of potentially successful adversarial attacks on a deployed model. While previous work has outlined methods for discovering vulnerabilities in public model architectures, the proposed equation seeks to provide a semi-quantitative benchmark for evaluating the potential risk factors of adversarial attacks.
Multilingual Augmenter: The Model Chooses
Feb 19, 2021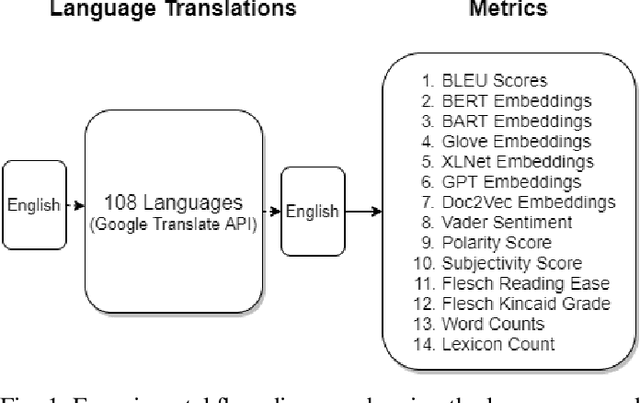



Natural Language Processing (NLP) relies heavily on training data. Transformers, as they have gotten bigger, have required massive amounts of training data. To satisfy this requirement, text augmentation should be looked at as a way to expand your current dataset and to generalize your models. One text augmentation we will look at is translation augmentation. We take an English sentence and translate it to another language before translating it back to English. In this paper, we look at the effect of 108 different language back translations on various metrics and text embeddings.
Fortify Machine Learning Production Systems: Detect and Classify Adversarial Attacks
Feb 19, 2021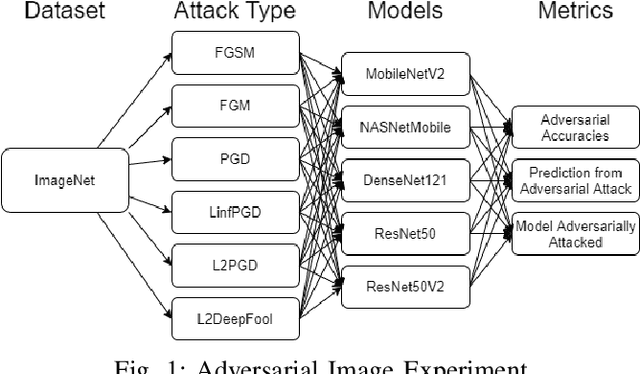
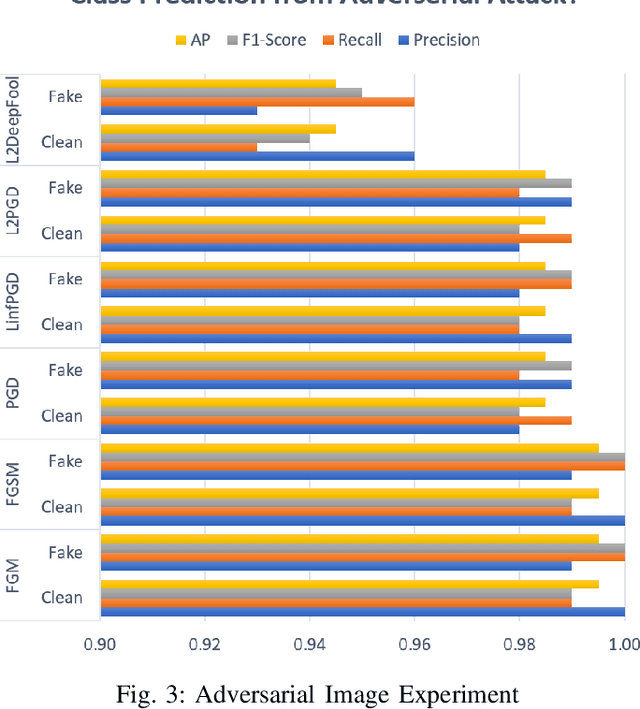
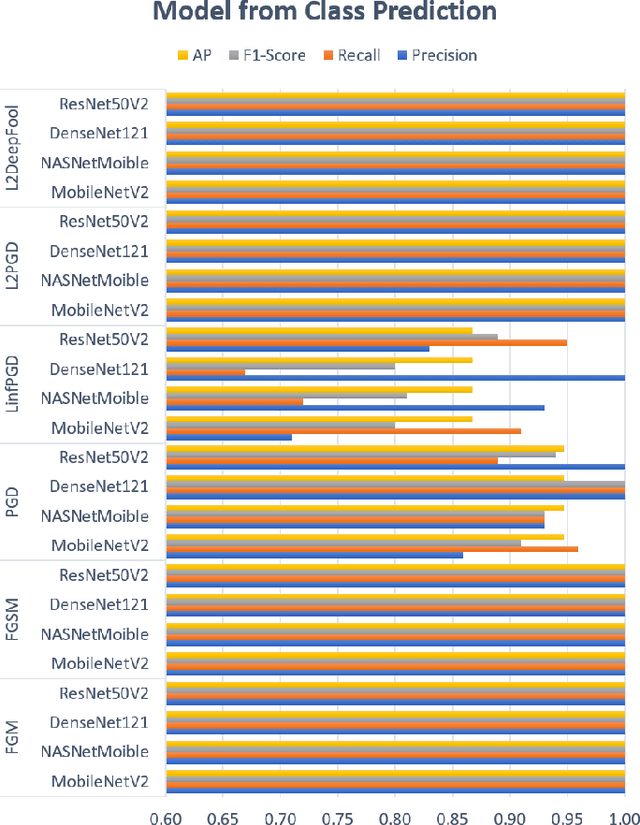
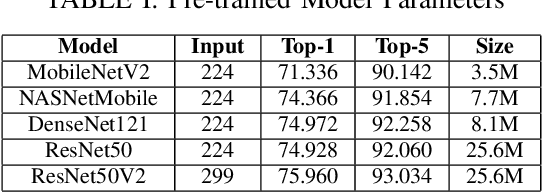
Production machine learning systems are consistently under attack by adversarial actors. Various deep learning models must be capable of accurately detecting fake or adversarial input while maintaining speed. In this work, we propose one piece of the production protection system: detecting an incoming adversarial attack and its characteristics. Detecting types of adversarial attacks has two primary effects: the underlying model can be trained in a structured manner to be robust from those attacks and the attacks can be potentially filtered out in realtime before causing any downstream damage. The adversarial image classification space is explored for models commonly used in transfer learning.
Local Translation Services for Neglected Languages
Jan 13, 2021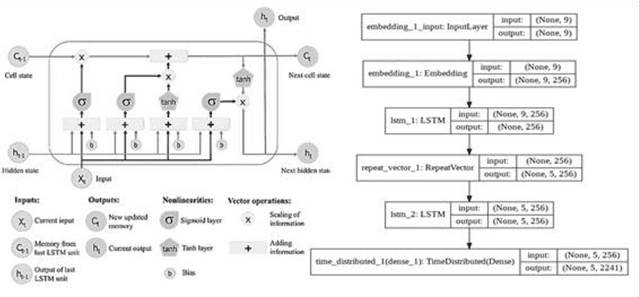
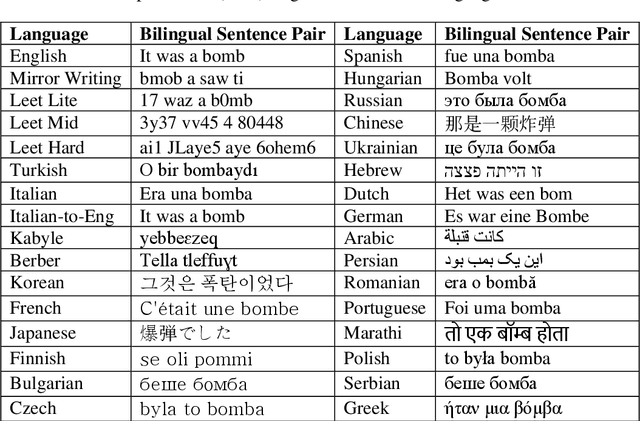
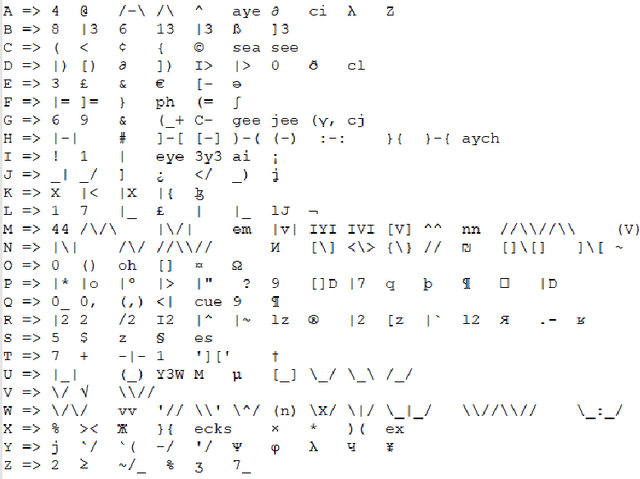
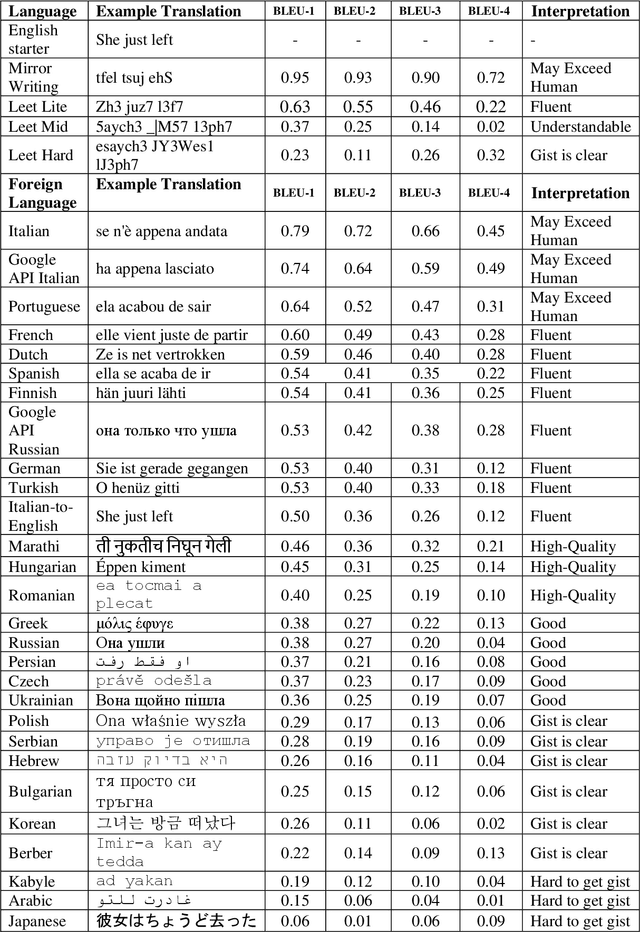
Taking advantage of computationally lightweight, but high-quality translators prompt consideration of new applications that address neglected languages. Locally run translators for less popular languages may assist data projects with protected or personal data that may require specific compliance checks before posting to a public translation API, but which could render reasonable, cost-effective solutions if done with an army of local, small-scale pair translators. Like handling a specialist's dialect, this research illustrates translating two historically interesting, but obfuscated languages: 1) hacker-speak ("l33t") and 2) reverse (or "mirror") writing as practiced by Leonardo da Vinci. The work generalizes a deep learning architecture to translatable variants of hacker-speak with lite, medium, and hard vocabularies. The original contribution highlights a fluent translator of hacker-speak in under 50 megabytes and demonstrates a generator for augmenting future datasets with greater than a million bilingual sentence pairs. The long short-term memory, recurrent neural network (LSTM-RNN) extends previous work demonstrating an English-to-foreign translation service built from as little as 10,000 bilingual sentence pairs. This work further solves the equivalent translation problem in twenty-six additional (non-obfuscated) languages and rank orders those models and their proficiency quantitatively with Italian as the most successful and Mandarin Chinese as the most challenging. For neglected languages, the method prototypes novel services for smaller niche translations such as Kabyle (Algerian dialect) which covers between 5-7 million speakers but one which for most enterprise translators, has not yet reached development. One anticipates the extension of this approach to other important dialects, such as translating technical (medical or legal) jargon and processing health records.
Black Box to White Box: Discover Model Characteristics Based on Strategic Probing
Sep 07, 2020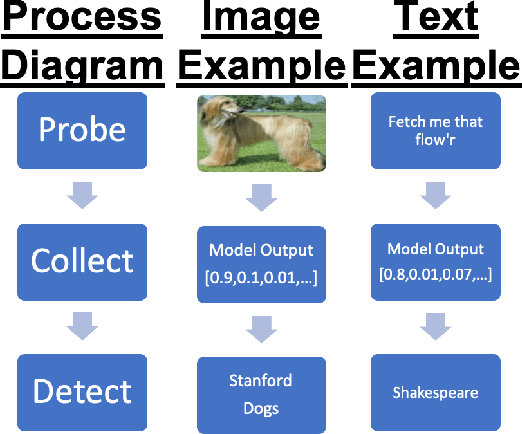
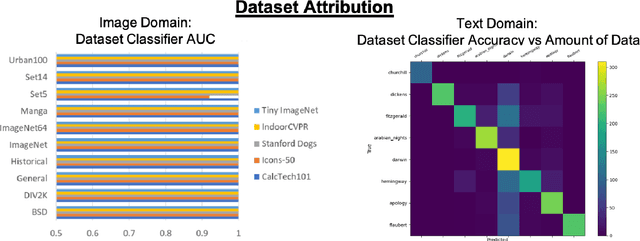
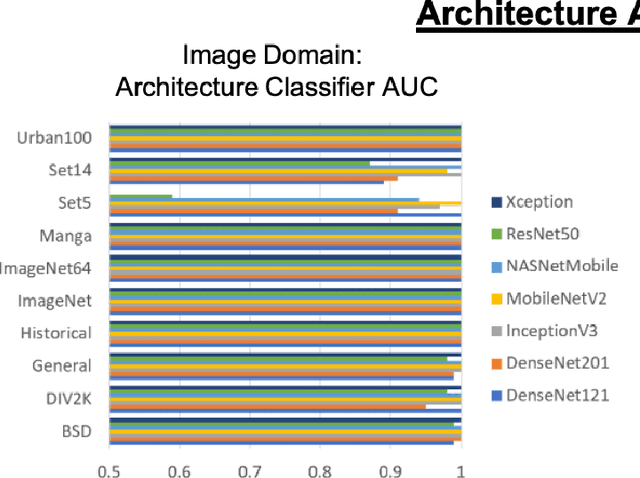
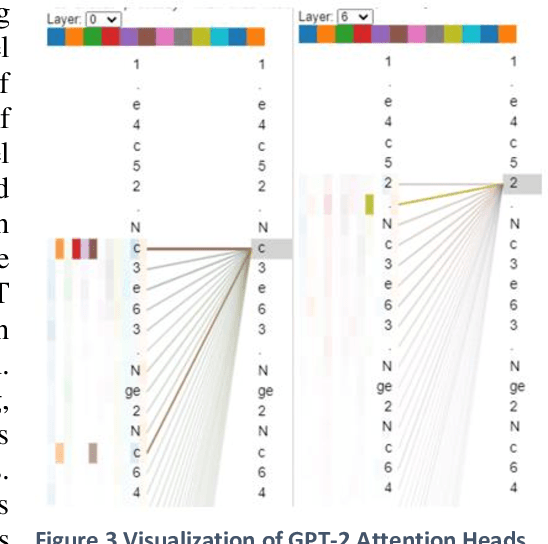
In Machine Learning, White Box Adversarial Attacks rely on knowing underlying knowledge about the model attributes. This works focuses on discovering to distrinct pieces of model information: the underlying architecture and primary training dataset. With the process in this paper, a structured set of input probes and the output of the model become the training data for a deep classifier. Two subdomains in Machine Learning are explored: image based classifiers and text transformers with GPT-2. With image classification, the focus is on exploring commonly deployed architectures and datasets available in popular public libraries. Using a single transformer architecture with multiple levels of parameters, text generation is explored by fine tuning off different datasets. Each dataset explored in image and text are distinguishable from one another. Diversity in text transformer outputs implies further research is needed to successfully classify architecture attribution in text domain.
The Chess Transformer: Mastering Play using Generative Language Models
Aug 21, 2020
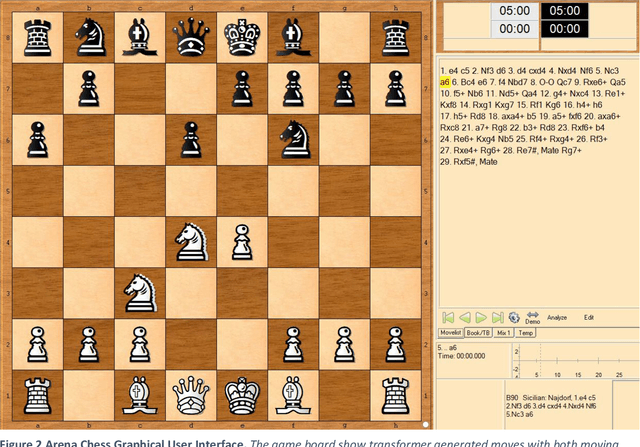
This work demonstrates that natural language transformers can support more generic strategic modeling, particularly for text-archived games. In addition to learning natural language skills, the abstract transformer architecture can generate meaningful moves on a chessboard. With further fine-tuning, the transformer learns complex gameplay by training on 2.8 million chess games in Portable Game Notation. After 30,000 training steps, OpenAI's Generative Pre-trained Transformer (GPT-2) optimizes weights for 774 million parameters. This fine-tuned Chess Transformer generates plausible strategies and displays game formations identifiable as classic openings, such as English or the Slav Exchange. Finally, in live play, the novel model demonstrates a human-to-transformer interface that correctly filters illegal moves and provides a novel method to challenge the transformer's chess strategies. We anticipate future work will build on this transformer's promise, particularly in other strategy games where features can capture the underlying complex rule syntax from simple but expressive player annotations.
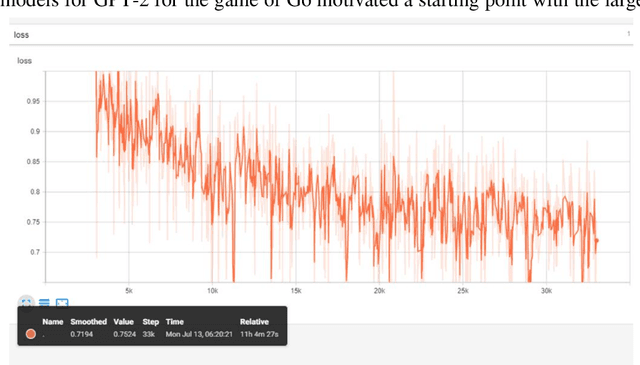
The Go Transformer: Natural Language Modeling for Game Play
Jul 07, 2020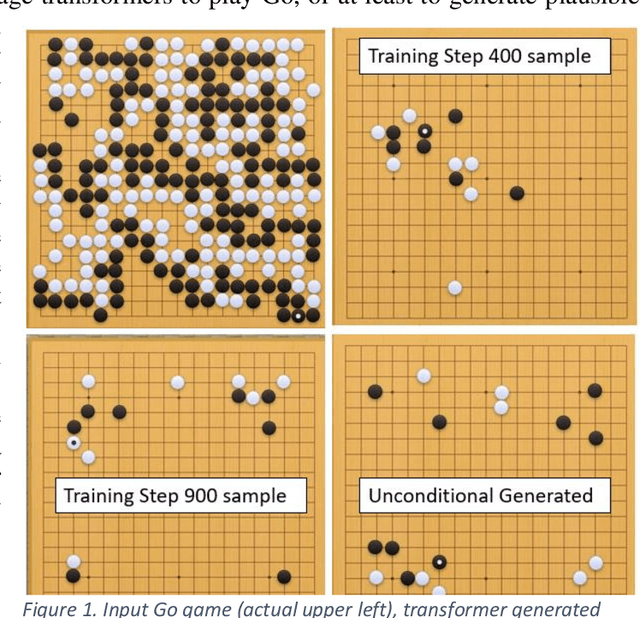

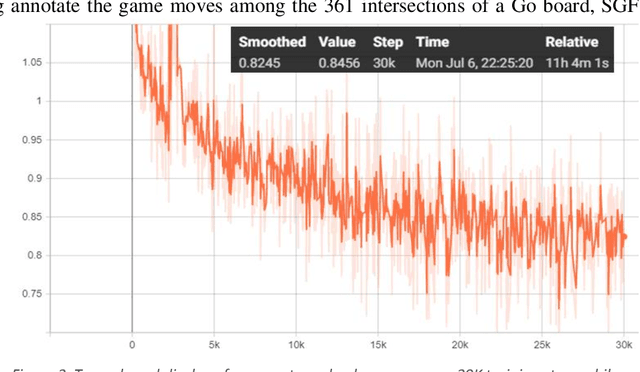
This work applies natural language modeling to generate plausible strategic moves in the ancient game of Go. We train the Generative Pretrained Transformer (GPT-2) to mimic the style of Go champions as archived in Smart Game Format (SGF), which offers a text description of move sequences. The trained model further generates valid but previously unseen strategies for Go. Because GPT-2 preserves punctuation and spacing, the raw output of the text generator provides inputs to game visualization and creative patterns, such as the Sabaki project's (2020) game engine using auto-replays. Results demonstrate that language modeling can capture both the sequencing format of championship Go games and their strategic formations. Compared to random game boards, the GPT-2 fine-tuning shows efficient opening move sequences favoring corner play over less advantageous center and side play. Game generation as a language modeling task offers novel approaches to more than 40 other board games where historical text annotation provides training data (e.g., Amazons & Connect 4/6).
Systematic Attack Surface Reduction For Deployed Sentiment Analysis Models
Jun 19, 2020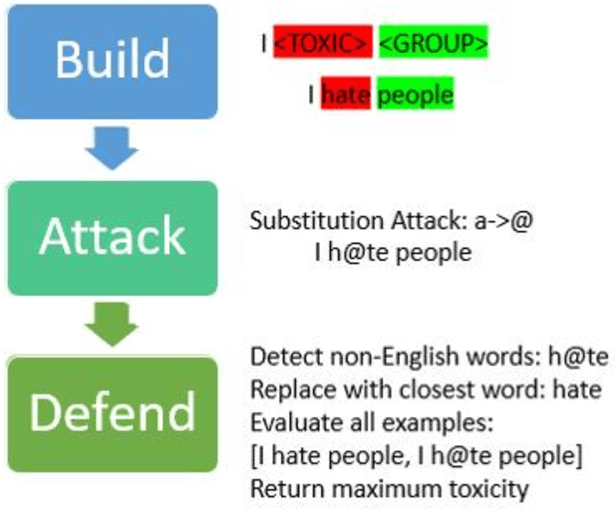
This work proposes a structured approach to baselining a model, identifying attack vectors, and securing the machine learning models after deployment. This method for securing each model post deployment is called the BAD (Build, Attack, and Defend) Architecture. Two implementations of the BAD architecture are evaluated to quantify the adversarial life cycle for a black box Sentiment Analysis system. As a challenging diagnostic, the Jigsaw Toxic Bias dataset is selected as the baseline in our performance tool. Each implementation of the architecture will build a baseline performance report, attack a common weakness, and defend the incoming attack. As an important note: each attack surface demonstrated in this work is detectable and preventable. The goal is to demonstrate a viable methodology for securing a machine learning model in a production setting.