 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack Box to White Box: Discover Model Characteristics Based on Strategic Probing
Paper and Code
Sep 07, 2020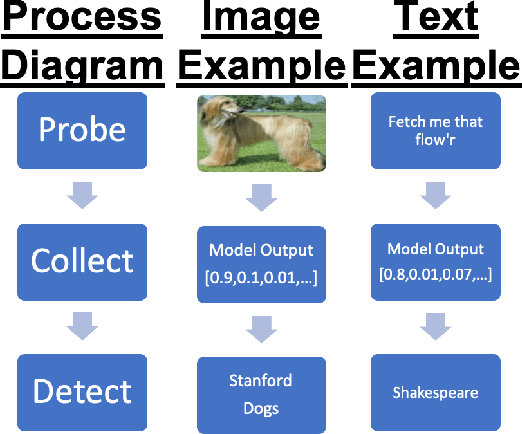
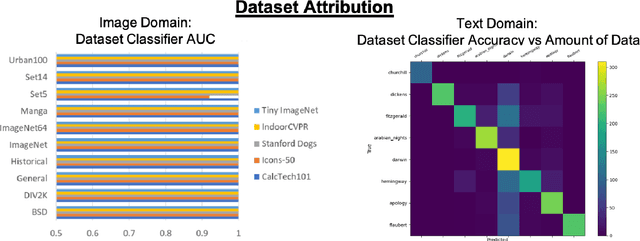
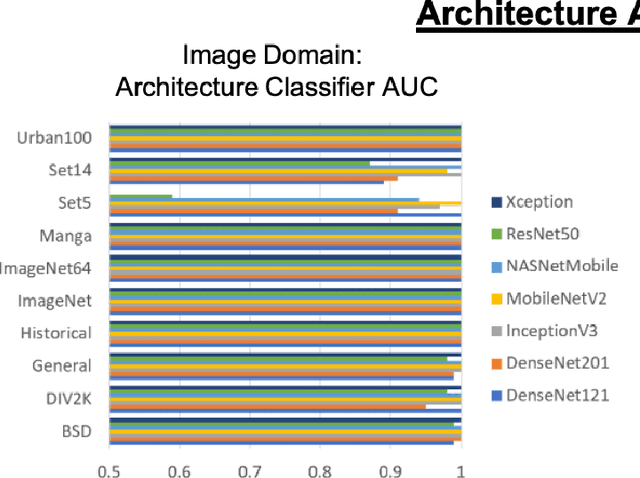
In Machine Learning, White Box Adversarial Attacks rely on knowing underlying knowledge about the model attributes. This works focuses on discovering to distrinct pieces of model information: the underlying architecture and primary training dataset. With the process in this paper, a structured set of input probes and the output of the model become the training data for a deep classifier. Two subdomains in Machine Learning are explored: image based classifiers and text transformers with GPT-2. With image classification, the focus is on exploring commonly deployed architectures and datasets available in popular public libraries. Using a single transformer architecture with multiple levels of parameters, text generation is explored by fine tuning off different datasets. Each dataset explored in image and text are distinguishable from one another. Diversity in text transformer outputs implies further research is needed to successfully classify architecture attribution in text domain.