 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Translation Services for Neglected Languages
Paper and Code
Jan 13, 2021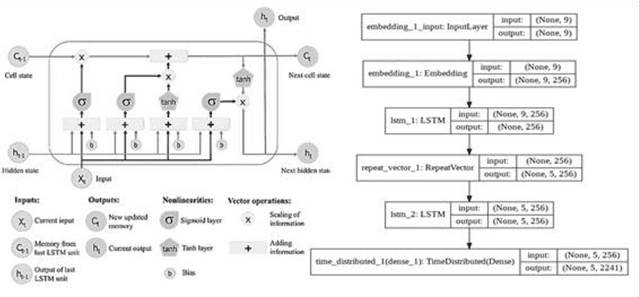
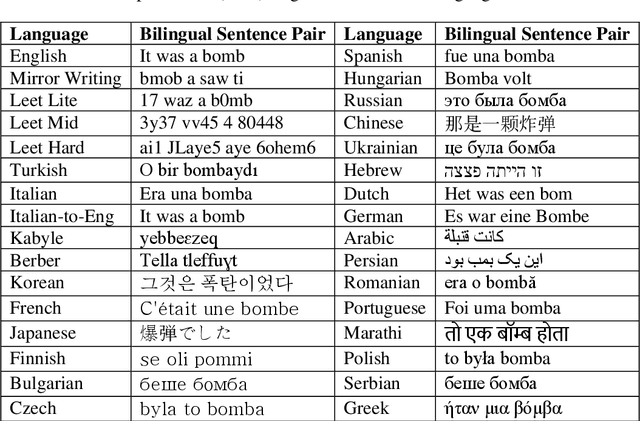
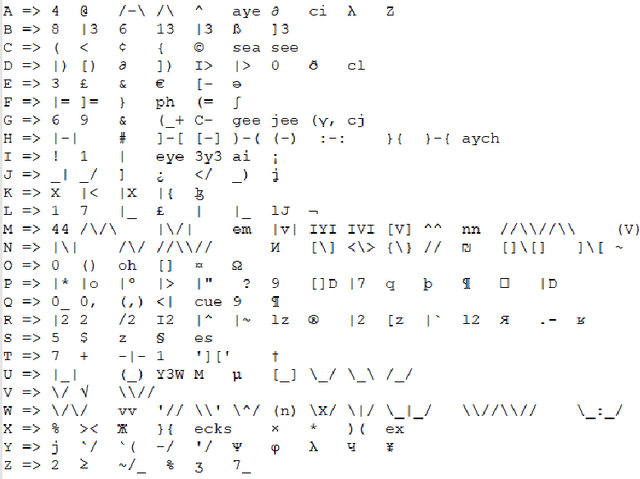
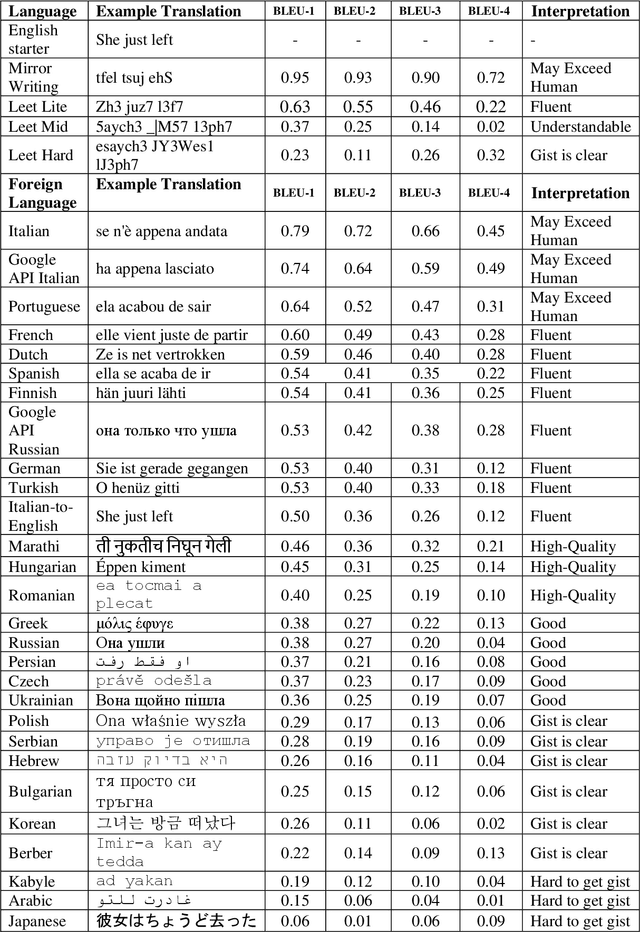
Taking advantage of computationally lightweight, but high-quality translators prompt consideration of new applications that address neglected languages. Locally run translators for less popular languages may assist data projects with protected or personal data that may require specific compliance checks before posting to a public translation API, but which could render reasonable, cost-effective solutions if done with an army of local, small-scale pair translators. Like handling a specialist's dialect, this research illustrates translating two historically interesting, but obfuscated languages: 1) hacker-speak ("l33t") and 2) reverse (or "mirror") writing as practiced by Leonardo da Vinci. The work generalizes a deep learning architecture to translatable variants of hacker-speak with lite, medium, and hard vocabularies. The original contribution highlights a fluent translator of hacker-speak in under 50 megabytes and demonstrates a generator for augmenting future datasets with greater than a million bilingual sentence pairs. The long short-term memory, recurrent neural network (LSTM-RNN) extends previous work demonstrating an English-to-foreign translation service built from as little as 10,000 bilingual sentence pairs. This work further solves the equivalent translation problem in twenty-six additional (non-obfuscated) languages and rank orders those models and their proficiency quantitatively with Italian as the most successful and Mandarin Chinese as the most challenging. For neglected languages, the method prototypes novel services for smaller niche translations such as Kabyle (Algerian dialect) which covers between 5-7 million speakers but one which for most enterprise translators, has not yet reached development. One anticipates the extension of this approach to other important dialects, such as translating technical (medical or legal) jargon and processing health records.