 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscoverability in Satellite Imagery: A Good Sentence is Worth a Thousand Pictures
Jan 03, 2020
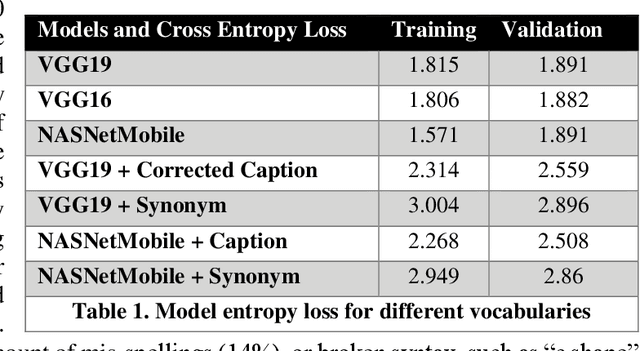

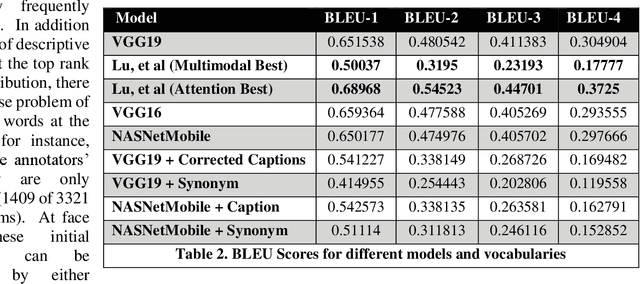
Small satellite constellations provide daily global coverage of the earth's landmass, but image enrichment relies on automating key tasks like change detection or feature searches. For example, to extract text annotations from raw pixels requires two dependent machine learning models, one to analyze the overhead image and the other to generate a descriptive caption. We evaluate seven models on the previously largest benchmark for satellite image captions. We extend the labeled image samples five-fold, then augment, correct and prune the vocabulary to approach a rough min-max (minimum word, maximum description). This outcome compares favorably to previous work with large pre-trained image models but offers a hundred-fold reduction in model size without sacrificing overall accuracy (when measured with log entropy loss). These smaller models provide new deployment opportunities, particularly when pushed to edge processors, on-board satellites, or distributed ground stations. To quantify a caption's descriptiveness, we introduce a novel multi-class confusion or error matrix to score both human-labeled test data and never-labeled images that include bounding box detection but lack full sentence captions. This work suggests future captioning strategies, particularly ones that can enrich the class coverage beyond land use applications and that lessen color-centered and adjacency adjectives ("green", "near", "between", etc.). Many modern language transformers present novel and exploitable models with world knowledge gleaned from training from their vast online corpus. One interesting, but easy example might learn the word association between wind and waves, thus enriching a beach scene with more than just color descriptions that otherwise might be accessed from raw pixels without text annotation.