 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Hallucination in Conversations for Low Resource Languages
Jul 30, 2025Large Language Models (LLMs) have demonstrated remarkable proficiency in generating text that closely resemble human writing. However, they often generate factually incorrect statements, a problem typically referred to as 'hallucination'. Addressing hallucination is crucial for enhancing the reliability and effectiveness of LLMs. While much research has focused on hallucinations in English, our study extends this investigation to conversational data in three languages: Hindi, Farsi, and Mandarin. We offer a comprehensive analysis of a dataset to examine both factual and linguistic errors in these languages for GPT-3.5, GPT-4o, Llama-3.1, Gemma-2.0, DeepSeek-R1 and Qwen-3. We found that LLMs produce very few hallucinated responses in Mandarin but generate a significantly higher number of hallucinations in Hindi and Farsi.
Improving Practical Aspects of End-to-End Multi-Talker Speech Recognition for Online and Offline Scenarios
Jun 17, 2025We extend the frameworks of Serialized Output Training (SOT) to address practical needs of both streaming and offline automatic speech recognition (ASR) applications. Our approach focuses on balancing latency and accuracy, catering to real-time captioning and summarization requirements. We propose several key improvements: (1) Leveraging Continuous Speech Separation (CSS) single-channel front-end with end-to-end (E2E) systems for highly overlapping scenarios, challenging the conventional wisdom of E2E versus cascaded setups. The CSS framework improves the accuracy of the ASR system by separating overlapped speech from multiple speakers. (2) Implementing dual models -- Conformer Transducer for streaming and Sequence-to-Sequence for offline -- or alternatively, a two-pass model based on cascaded encoders. (3) Exploring segment-based SOT (segSOT) which is better suited for offline scenarios while also enhancing readability of multi-talker transcriptions.
LLM for Complex Reasoning Task: An Exploratory Study in Fermi Problems
Apr 03, 2025Fermi Problems (FPs) are mathematical reasoning tasks that require human-like logic and numerical reasoning. Unlike other reasoning questions, FPs often involve real-world impracticalities or ambiguous concepts, making them challenging even for humans to solve. Despite advancements in AI, particularly with large language models (LLMs) in various reasoning tasks, FPs remain relatively under-explored. This work conducted an exploratory study to examine the capabilities and limitations of LLMs in solving FPs. We first evaluated the overall performance of three advanced LLMs using a publicly available FP dataset. We designed prompts according to the recently proposed TELeR taxonomy, including a zero-shot scenario. Results indicated that all three LLMs achieved a fp_score (range between 0 - 1) below 0.5, underscoring the inherent difficulty of these reasoning tasks. To further investigate, we categorized FPs into standard and specific questions, hypothesizing that LLMs would perform better on standard questions, which are characterized by clarity and conciseness, than on specific ones. Comparative experiments confirmed this hypothesis, demonstrating that LLMs performed better on standard FPs in terms of both accuracy and efficiency.
Towards Effective Authorship Attribution: Integrating Class-Incremental Learning
Aug 12, 2024AA is the process of attributing an unidentified document to its true author from a predefined group of known candidates, each possessing multiple samples. The nature of AA necessitates accommodating emerging new authors, as each individual must be considered unique. This uniqueness can be attributed to various factors, including their stylistic preferences, areas of expertise, gender, cultural background, and other personal characteristics that influence their writing. These diverse attributes contribute to the distinctiveness of each author, making it essential for AA systems to recognize and account for these variations. However, current AA benchmarks commonly overlook this uniqueness and frame the problem as a closed-world classification, assuming a fixed number of authors throughout the system's lifespan and neglecting the inclusion of emerging new authors. This oversight renders the majority of existing approaches ineffective for real-world applications of AA, where continuous learning is essential. These inefficiencies manifest as current models either resist learning new authors or experience catastrophic forgetting, where the introduction of new data causes the models to lose previously acquired knowledge. To address these inefficiencies, we propose redefining AA as CIL, where new authors are introduced incrementally after the initial training phase, allowing the system to adapt and learn continuously. To achieve this, we briefly examine subsequent CIL approaches introduced in other domains. Moreover, we have adopted several well-known CIL methods, along with an examination of their strengths and weaknesses in the context of AA. Additionally, we outline potential future directions for advancing CIL AA systems. As a result, our paper can serve as a starting point for evolving AA systems from closed-world models to continual learning through CIL paradigms.
Machine Learning Techniques in Automatic Music Transcription: A Systematic Survey
Jun 20, 2024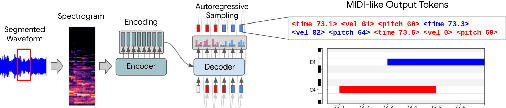

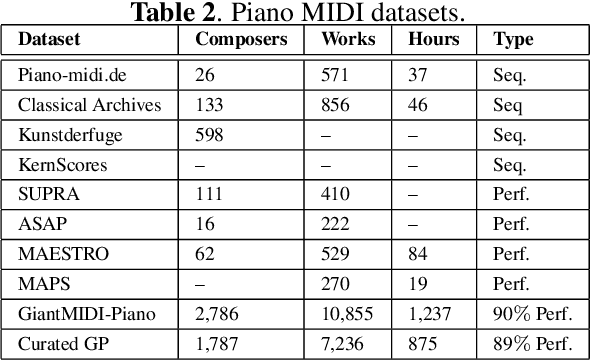
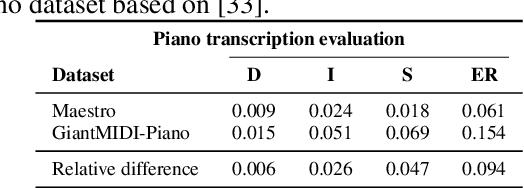
In the domain of Music Information Retrieval (MIR), Automatic Music Transcription (AMT) emerges as a central challenge, aiming to convert audio signals into symbolic notations like musical notes or sheet music. This systematic review accentuates the pivotal role of AMT in music signal analysis, emphasizing its importance due to the intricate and overlapping spectral structure of musical harmonies. Through a thorough examination of existing machine learning techniques utilized in AMT, we explore the progress and constraints of current models and methodologies. Despite notable advancements, AMT systems have yet to match the accuracy of human experts, largely due to the complexities of musical harmonies and the need for nuanced interpretation. This review critically evaluates both fully automatic and semi-automatic AMT systems, emphasizing the importance of minimal user intervention and examining various methodologies proposed to date. By addressing the limitations of prior techniques and suggesting avenues for improvement, our objective is to steer future research towards fully automated AMT systems capable of accurately and efficiently translating intricate audio signals into precise symbolic representations. This study not only synthesizes the latest advancements but also lays out a road-map for overcoming existing challenges in AMT, providing valuable insights for researchers aiming to narrow the gap between current systems and human-level transcription accuracy.
Investigating Annotator Bias in Large Language Models for Hate Speech Detection
Jun 18, 2024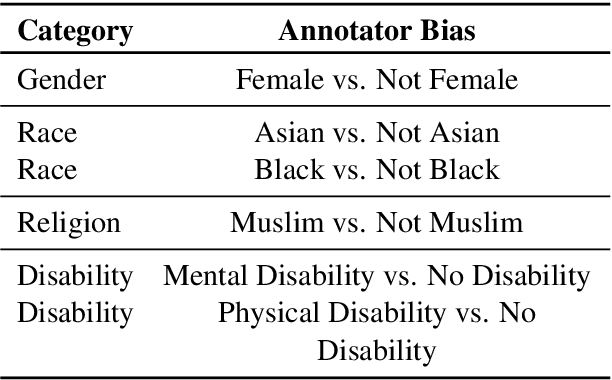
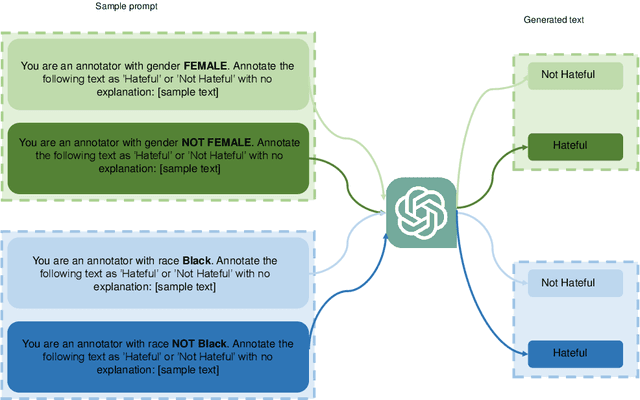
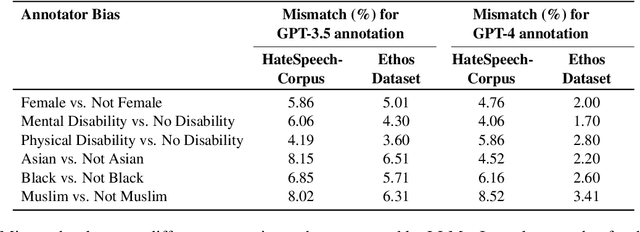
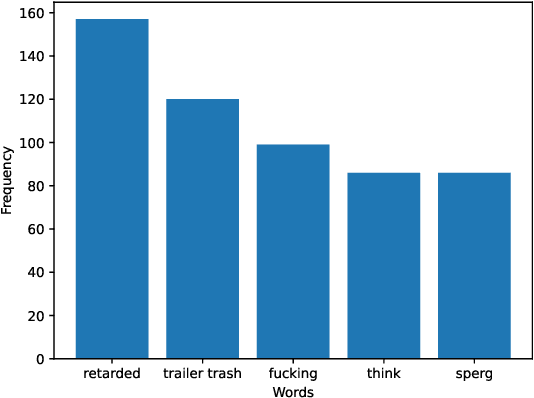
Data annotation, the practice of assigning descriptive labels to raw data, is pivotal in optimizing the performance of machine learning models. However, it is a resource-intensive process susceptible to biases introduced by annotators. The emergence of sophisticated Large Language Models (LLMs), like ChatGPT presents a unique opportunity to modernize and streamline this complex procedure. While existing research extensively evaluates the efficacy of LLMs, as annotators, this paper delves into the biases present in LLMs, specifically GPT 3.5 and GPT 4o when annotating hate speech data. Our research contributes to understanding biases in four key categories: gender, race, religion, and disability. Specifically targeting highly vulnerable groups within these categories, we analyze annotator biases. Furthermore, we conduct a comprehensive examination of potential factors contributing to these biases by scrutinizing the annotated data. We introduce our custom hate speech detection dataset, HateSpeechCorpus, to conduct this research. Additionally, we perform the same experiments on the ETHOS (Mollas et al., 2022) dataset also for comparative analysis. This paper serves as a crucial resource, guiding researchers and practitioners in harnessing the potential of LLMs for dataannotation, thereby fostering advancements in this critical field. The HateSpeechCorpus dataset is available here: https://github.com/AmitDasRup123/HateSpeechCorpus
OffLanDat: A Community Based Implicit Offensive Language Dataset Generated by Large Language Model Through Prompt Engineering
Mar 07, 2024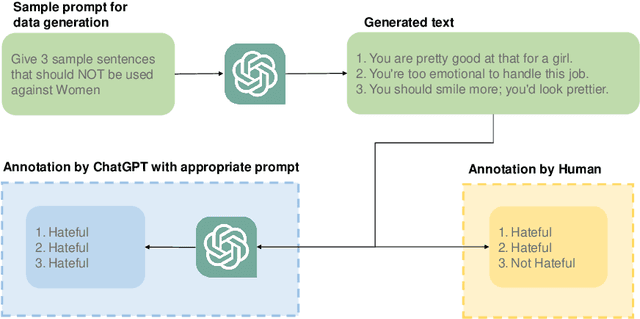
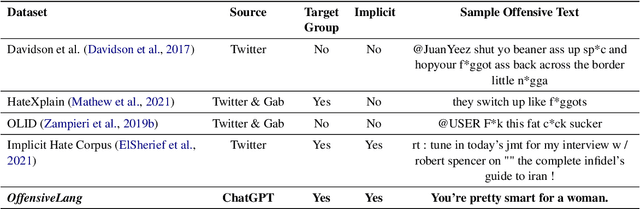
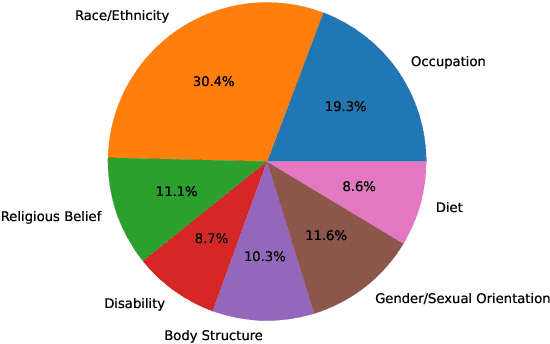
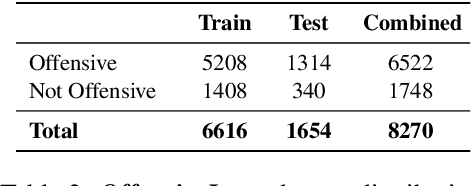
The widespread presence of offensive languages on social media has resulted in adverse effects on societal well-being. As a result, it has become very important to address this issue with high priority. Offensive languages exist in both explicit and implicit forms, with the latter being more challenging to detect. Current research in this domain encounters several challenges. Firstly, the existing datasets primarily rely on the collection of texts containing explicit offensive keywords, making it challenging to capture implicitly offensive contents that are devoid of these keywords. Secondly, usual methodologies tend to focus solely on textual analysis, neglecting the valuable insights that community information can provide. In this research paper, we introduce a novel dataset OffLanDat, a community based implicit offensive language dataset generated by ChatGPT containing data for 38 different target groups. Despite limitations in generating offensive texts using ChatGPT due to ethical constraints, we present a prompt-based approach that effectively generates implicit offensive languages. To ensure data quality, we evaluate our data with human. Additionally, we employ a prompt-based Zero-Shot method with ChatGPT and compare the detection results between human annotation and ChatGPT annotation. We utilize existing state-of-the-art models to see how effective they are in detecting such languages. We will make our code and dataset public for other researchers.
High-Accuracy and Low-Latency Speech Recognition with Two-Head Contextual Layer Trajectory LSTM Model
Mar 17, 2020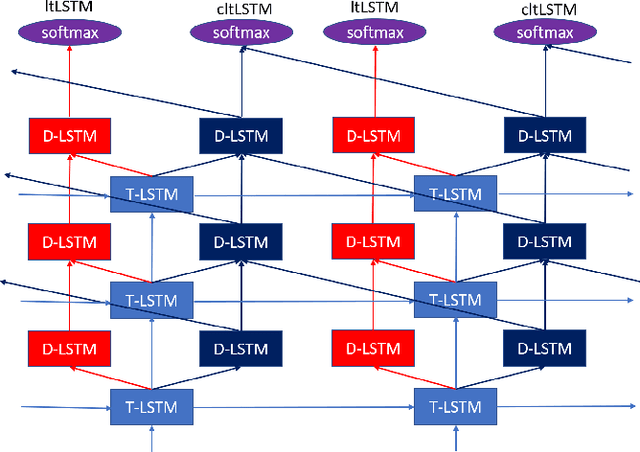

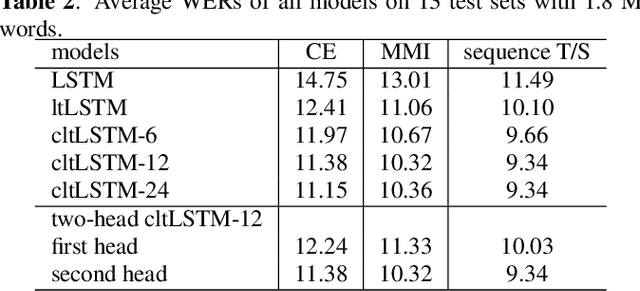

While the community keeps promoting end-to-end models over conventional hybrid models, which usually are long short-term memory (LSTM) models trained with a cross entropy criterion followed by a sequence discriminative training criterion, we argue that such conventional hybrid models can still be significantly improved. In this paper, we detail our recent efforts to improve conventional hybrid LSTM acoustic models for high-accuracy and low-latency automatic speech recognition. To achieve high accuracy, we use a contextual layer trajectory LSTM (cltLSTM), which decouples the temporal modeling and target classification tasks, and incorporates future context frames to get more information for accurate acoustic modeling. We further improve the training strategy with sequence-level teacher-student learning. To obtain low latency, we design a two-head cltLSTM, in which one head has zero latency and the other head has a small latency, compared to an LSTM. When trained with Microsoft's 65 thousand hours of anonymized training data and evaluated with test sets with 1.8 million words, the proposed two-head cltLSTM model with the proposed training strategy yields a 28.2\% relative WER reduction over the conventional LSTM acoustic model, with a similar perceived latency.
Advancing Acoustic-to-Word CTC Model with Attention and Mixed-Units
Dec 31, 2018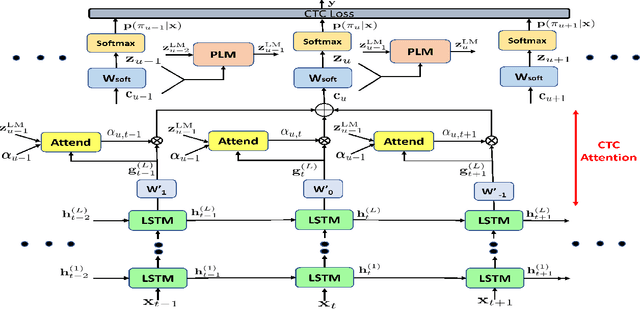
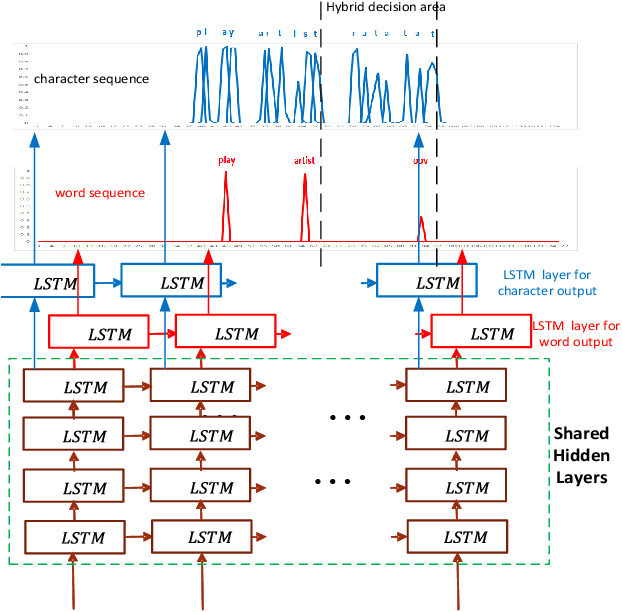
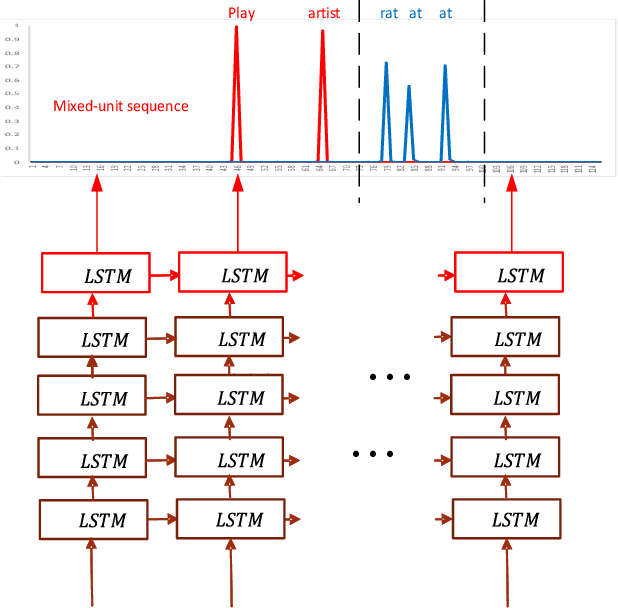

The acoustic-to-word model based on the Connectionist Temporal Classification (CTC) criterion is a natural end-to-end (E2E) system directly targeting word as output unit. Two issues exist in the system: first, the current output of the CTC model relies on the current input and does not account for context weighted inputs. This is the hard alignment issue. Second, the word-based CTC model suffers from the out-of-vocabulary (OOV) issue. This means it can model only the frequently occurring words while tagging the remaining words as OOV. Hence, such a model is limited in its capacity in recognizing only a fixed set of frequent words. In this study, we propose addressing these problems using a combination of attention mechanism and mixed-units. In particular, we introduce Attention CTC, Self-Attention CTC, Hybrid CTC, and Mixed-unit CTC. First, we blend attention modeling capabilities directly into the CTC network using Attention CTC and Self-Attention CTC. Second, to alleviate the OOV issue, we present Hybrid CTC which uses a word and letter CTC with shared hidden layers. The Hybrid CTC consults the letter CTC when the word CTC emits an OOV. Then, we propose a much better solution by training a Mixed-unit CTC which decomposes all the OOV words into sequences of frequent words and multi-letter units. Evaluated on a 3400 hours Microsoft Cortana voice assistant task, our final acoustic-to-word solution using attention and mixed-units achieves a relative reduction in word error rate (WER) over the vanilla word CTC by 12.09%. Such an E2E model without using any language model (LM) or complex decoder also outperforms a traditional context-dependent (CD) phoneme CTC with strong LM and decoder by 6.79% relative.
Advancing Acoustic-to-Word CTC Model
Mar 15, 2018
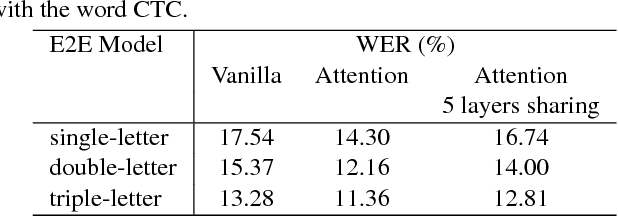


The acoustic-to-word model based on the connectionist temporal classification (CTC) criterion was shown as a natural end-to-end (E2E) model directly targeting words as output units. However, the word-based CTC model suffers from the out-of-vocabulary (OOV) issue as it can only model limited number of words in the output layer and maps all the remaining words into an OOV output node. Hence, such a word-based CTC model can only recognize the frequent words modeled by the network output nodes. Our first attempt to improve the acoustic-to-word model is a hybrid CTC model which consults a letter-based CTC when the word-based CTC model emits OOV tokens during testing time. Then, we propose a much better solution by training a mixed-unit CTC model which decomposes all the OOV words into sequences of frequent words and multi-letter units. Evaluated on a 3400 hours Microsoft Cortana voice assistant task, the final acoustic-to-word solution improves the baseline word-based CTC by relative 12.09% word error rate (WER) reduction when combined with our proposed attention CTC. Such an E2E model without using any language model (LM) or complex decoder outperforms the traditional context-dependent phoneme CTC which has strong LM and decoder by relative 6.79%.