 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Effective Authorship Attribution: Integrating Class-Incremental Learning
Aug 12, 2024AA is the process of attributing an unidentified document to its true author from a predefined group of known candidates, each possessing multiple samples. The nature of AA necessitates accommodating emerging new authors, as each individual must be considered unique. This uniqueness can be attributed to various factors, including their stylistic preferences, areas of expertise, gender, cultural background, and other personal characteristics that influence their writing. These diverse attributes contribute to the distinctiveness of each author, making it essential for AA systems to recognize and account for these variations. However, current AA benchmarks commonly overlook this uniqueness and frame the problem as a closed-world classification, assuming a fixed number of authors throughout the system's lifespan and neglecting the inclusion of emerging new authors. This oversight renders the majority of existing approaches ineffective for real-world applications of AA, where continuous learning is essential. These inefficiencies manifest as current models either resist learning new authors or experience catastrophic forgetting, where the introduction of new data causes the models to lose previously acquired knowledge. To address these inefficiencies, we propose redefining AA as CIL, where new authors are introduced incrementally after the initial training phase, allowing the system to adapt and learn continuously. To achieve this, we briefly examine subsequent CIL approaches introduced in other domains. Moreover, we have adopted several well-known CIL methods, along with an examination of their strengths and weaknesses in the context of AA. Additionally, we outline potential future directions for advancing CIL AA systems. As a result, our paper can serve as a starting point for evolving AA systems from closed-world models to continual learning through CIL paradigms.
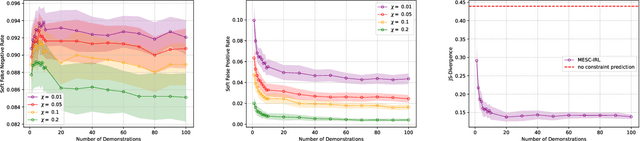
Learning Behavioral Soft Constraints from Demonstrations
Feb 21, 2022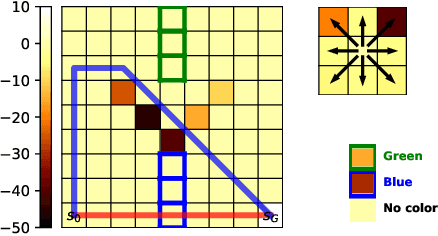
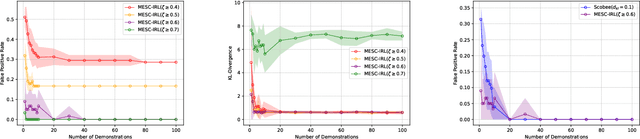
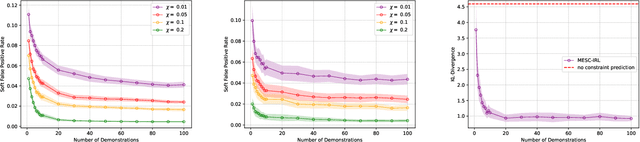

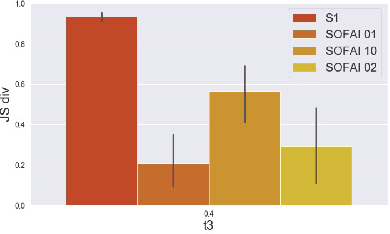
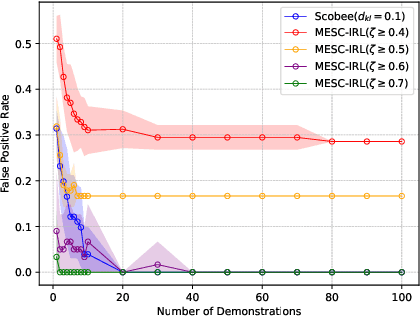
Many real-life scenarios require humans to make difficult trade-offs: do we always follow all the traffic rules or do we violate the speed limit in an emergency? These scenarios force us to evaluate the trade-off between collective rules and norms with our own personal objectives and desires. To create effective AI-human teams, we must equip AI agents with a model of how humans make these trade-offs in complex environments when there are implicit and explicit rules and constraints. Agent equipped with these models will be able to mirror human behavior and/or to draw human attention to situations where decision making could be improved. To this end, we propose a novel inverse reinforcement learning (IRL) method: Max Entropy Inverse Soft Constraint IRL (MESC-IRL), for learning implicit hard and soft constraints over states, actions, and state features from demonstrations in deterministic and non-deterministic environments modeled as Markov Decision Processes (MDPs). Our method enables agents implicitly learn human constraints and desires without the need for explicit modeling by the agent designer and to transfer these constraints between environments. Our novel method generalizes prior work which only considered deterministic hard constraints and achieves state of the art performance.
Combining Fast and Slow Thinking for Human-like and Efficient Navigation in Constrained Environments
Jan 18, 2022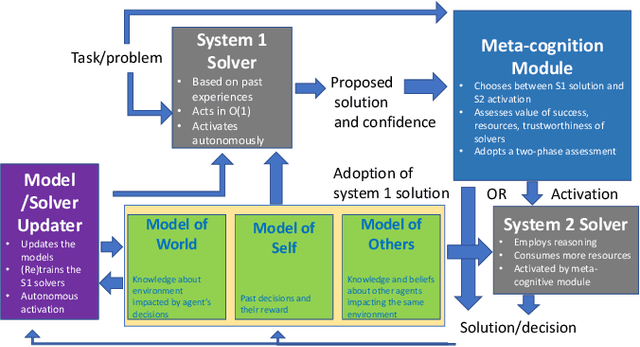

Current AI systems lack several important human capabilities, such as adaptability, generalizability, self-control, consistency, common sense, and causal reasoning. We believe that existing cognitive theories of human decision making, such as the thinking fast and slow theory, can provide insights on how to advance AI systems towards some of these capabilities. In this paper, we propose a general architecture that is based on fast/slow solvers and a metacognitive component. We then present experimental results on the behavior of an instance of this architecture, for AI systems that make decisions about navigating in a constrained environment. We show how combining the fast and slow decision modalities allows the system to evolve over time and gradually pass from slow to fast thinking with enough experience, and that this greatly helps in decision quality, resource consumption, and efficiency.
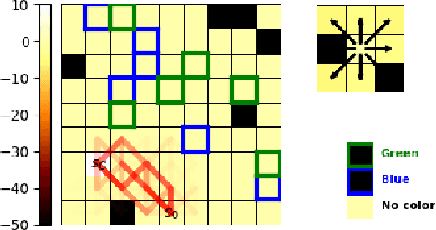
Making Human-Like Trade-offs in Constrained Environments by Learning from Demonstrations
Sep 22, 2021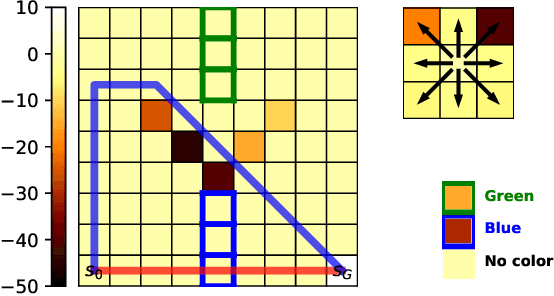

Many real-life scenarios require humans to make difficult trade-offs: do we always follow all the traffic rules or do we violate the speed limit in an emergency? These scenarios force us to evaluate the trade-off between collective norms and our own personal objectives. To create effective AI-human teams, we must equip AI agents with a model of how humans make trade-offs in complex, constrained environments. These agents will be able to mirror human behavior or to draw human attention to situations where decision making could be improved. To this end, we propose a novel inverse reinforcement learning (IRL) method for learning implicit hard and soft constraints from demonstrations, enabling agents to quickly adapt to new settings. In addition, learning soft constraints over states, actions, and state features allows agents to transfer this knowledge to new domains that share similar aspects. We then use the constraint learning method to implement a novel system architecture that leverages a cognitive model of human decision making, multi-alternative decision field theory (MDFT), to orchestrate competing objectives. We evaluate the resulting agent on trajectory length, number of violated constraints, and total reward, demonstrating that our agent architecture is both general and achieves strong performance. Thus we are able to capture and replicate human-like trade-offs from demonstrations in environments when constraints are not explicit.
UoT-UWF-PartAI at SemEval-2021 Task 5: Self Attention Based Bi-GRU with Multi-Embedding Representation for Toxicity Highlighter
Apr 27, 2021
Toxic Spans Detection(TSD) task is defined as highlighting spans that make a text toxic. Many works have been done to classify a given comment or document as toxic or non-toxic. However, none of those proposed models work at the token level. In this paper, we propose a self-attention-based bidirectional gated recurrent unit(BiGRU) with a multi-embedding representation of the tokens. Our proposed model enriches the representation by a combination of GPT-2, GloVe, and RoBERTa embeddings, which led to promising results. Experimental results show that our proposed approach is very effective in detecting span tokens.