 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Satellite Imagery Data for Wildfire Detection through Mask-Conditioned Generative AI
Apr 02, 2026The scarcity of labeled satellite imagery remains a fundamental bottleneck for deep-learning (DL)-based wildfire monitoring systems. This paper investigates whether a diffusion-based foundation model for Earth Observation (EO), EarthSynth, can synthesize realistic post-wildfire Sentinel-2 RGB imagery conditioned on existing burn masks, without task-specific retraining. Using burn masks derived from the CalFireSeg-50 dataset (Martin et al., 2025), we design and evaluate six controlled experimental configurations that systematically vary: (i) pipeline architecture (mask-only full generation vs. inpainting with pre-fire context), (ii) prompt engineering strategy (three hand-crafted prompts and a VLM-generated prompt via Qwen2-VL), and (iii) a region-wise color-matching post-processing step. Quantitative assessment on 10 stratified test samples uses four complementary metrics: Burn IoU, burn-region color distance (ΔC_burn), Darkness Contrast, and Spectral Plausibility. Results show that inpainting-based pipelines consistently outperform full-tile generation across all metrics, with the structured inpainting prompt achieving the best spatial alignment (Burn IoU = 0.456) and burn saliency (Darkness Contrast = 20.44), while color matching produces the lowest color distance (ΔC_burn = 63.22) at the cost of reduced burn saliency. VLM-assisted inpainting is competitive with hand-crafted prompts. These findings provide a foundation for incorporating generative data augmentation into wildfire detection pipelines. Code and experiments are available at: https://www.kaggle.com/code/valeriamartinh/genai-all-runned
Natural Language Interaction with Databases on Edge Devices in the Internet of Battlefield Things
Jun 05, 2025The expansion of the Internet of Things (IoT) in the battlefield, Internet of Battlefield Things (IoBT), gives rise to new opportunities for enhancing situational awareness. To increase the potential of IoBT for situational awareness in critical decision making, the data from these devices must be processed into consumer-ready information objects, and made available to consumers on demand. To address this challenge we propose a workflow that makes use of natural language processing (NLP) to query a database technology and return a response in natural language. Our solution utilizes Large Language Models (LLMs) that are sized for edge devices to perform NLP as well as graphical databases which are well suited for dynamic connected networks which are pervasive in the IoBT. Our architecture employs LLMs for both mapping questions in natural language to Cypher database queries as well as to summarize the database output back to the user in natural language. We evaluate several medium sized LLMs for both of these tasks on a database representing publicly available data from the US Army's Multipurpose Sensing Area (MSA) at the Jornada Range in Las Cruces, NM. We observe that Llama 3.1 (8 billion parameters) outperforms the other models across all the considered metrics. Most importantly, we note that, unlike current methods, our two step approach allows the relaxation of the Exact Match (EM) requirement of the produced Cypher queries with ground truth code and, in this way, it achieves a 19.4% increase in accuracy. Our workflow lays the ground work for deploying LLMs on edge devices to enable natural language interactions with databases containing information objects for critical decision making.
Development and Application of a Sentinel-2 Satellite Imagery Dataset for Deep-Learning Driven Forest Wildfire Detection
Sep 24, 2024Forest loss due to natural events, such as wildfires, represents an increasing global challenge that demands advanced analytical methods for effective detection and mitigation. To this end, the integration of satellite imagery with deep learning (DL) methods has become essential. Nevertheless, this approach requires substantial amounts of labeled data to produce accurate results. In this study, we use bi-temporal Sentinel-2 satellite imagery sourced from Google Earth Engine (GEE) to build the California Wildfire GeoImaging Dataset (CWGID), a high-resolution labeled satellite imagery dataset with over 100,000 labeled before and after forest wildfire image pairs for wildfire detection through DL. Our methods include data acquisition from authoritative sources, data processing, and an initial dataset analysis using three pre-trained Convolutional Neural Network (CNN) architectures. Our results show that the EF EfficientNet-B0 model achieves the highest accuracy of over 92% in detecting forest wildfires. The CWGID and the methodology used to build it, prove to be a valuable resource for training and testing DL architectures for forest wildfire detection.
Making Human-Like Trade-offs in Constrained Environments by Learning from Demonstrations
Sep 22, 2021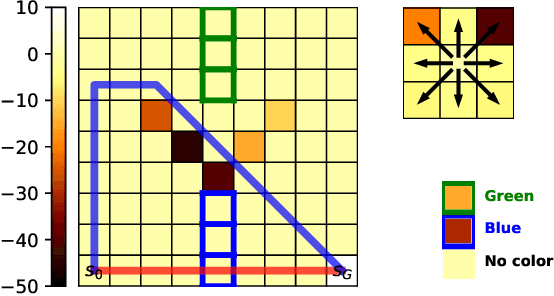
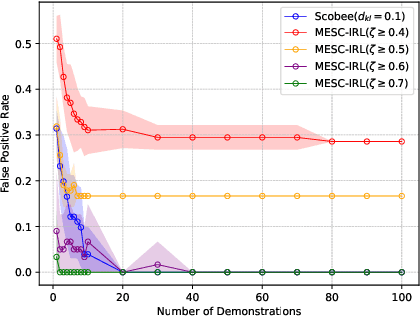
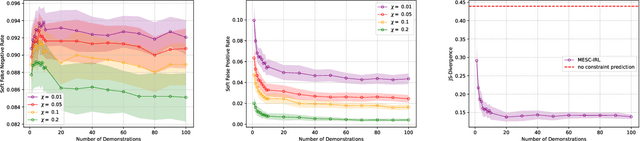

Many real-life scenarios require humans to make difficult trade-offs: do we always follow all the traffic rules or do we violate the speed limit in an emergency? These scenarios force us to evaluate the trade-off between collective norms and our own personal objectives. To create effective AI-human teams, we must equip AI agents with a model of how humans make trade-offs in complex, constrained environments. These agents will be able to mirror human behavior or to draw human attention to situations where decision making could be improved. To this end, we propose a novel inverse reinforcement learning (IRL) method for learning implicit hard and soft constraints from demonstrations, enabling agents to quickly adapt to new settings. In addition, learning soft constraints over states, actions, and state features allows agents to transfer this knowledge to new domains that share similar aspects. We then use the constraint learning method to implement a novel system architecture that leverages a cognitive model of human decision making, multi-alternative decision field theory (MDFT), to orchestrate competing objectives. We evaluate the resulting agent on trajectory length, number of violated constraints, and total reward, demonstrating that our agent architecture is both general and achieves strong performance. Thus we are able to capture and replicate human-like trade-offs from demonstrations in environments when constraints are not explicit.
Modeling Voters in Multi-Winner Approval Voting
Dec 04, 2020
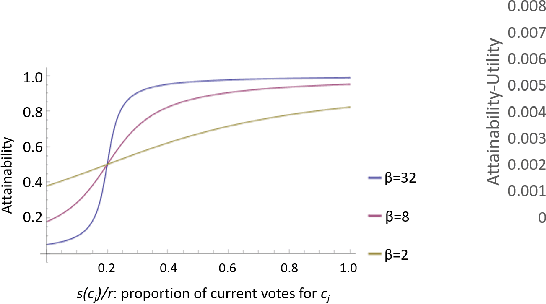
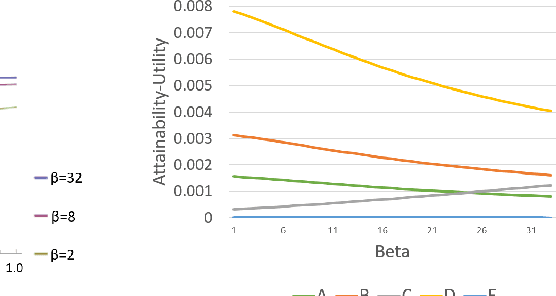

In many real world situations, collective decisions are made using voting and, in scenarios such as committee or board elections, employing voting rules that return multiple winners. In multi-winner approval voting (AV), an agent submits a ballot consisting of approvals for as many candidates as they wish, and winners are chosen by tallying up the votes and choosing the top-$k$ candidates receiving the most approvals. In many scenarios, an agent may manipulate the ballot they submit in order to achieve a better outcome by voting in a way that does not reflect their true preferences. In complex and uncertain situations, agents may use heuristics instead of incurring the additional effort required to compute the manipulation which most favors them. In this paper, we examine voting behavior in single-winner and multi-winner approval voting scenarios with varying degrees of uncertainty using behavioral data obtained from Mechanical Turk. We find that people generally manipulate their vote to obtain a better outcome, but often do not identify the optimal manipulation. There are a number of predictive models of agent behavior in the COMSOC and psychology literature that are based on cognitively plausible heuristic strategies. We show that the existing approaches do not adequately model real-world data. We propose a novel model that takes into account the size of the winning set and human cognitive constraints, and demonstrate that this model is more effective at capturing real-world behaviors in multi-winner approval voting scenarios.
Heuristic Strategies in Uncertain Approval Voting Environments
Nov 29, 2019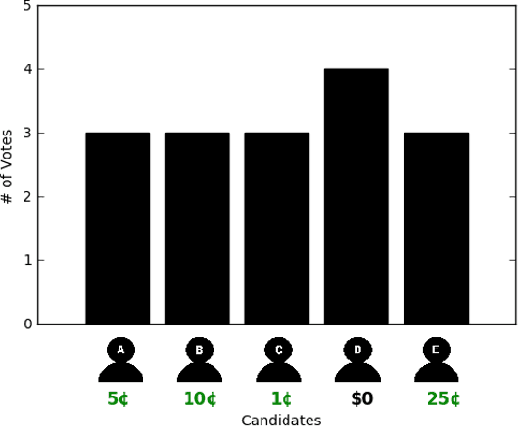
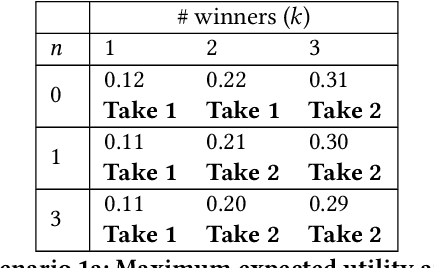
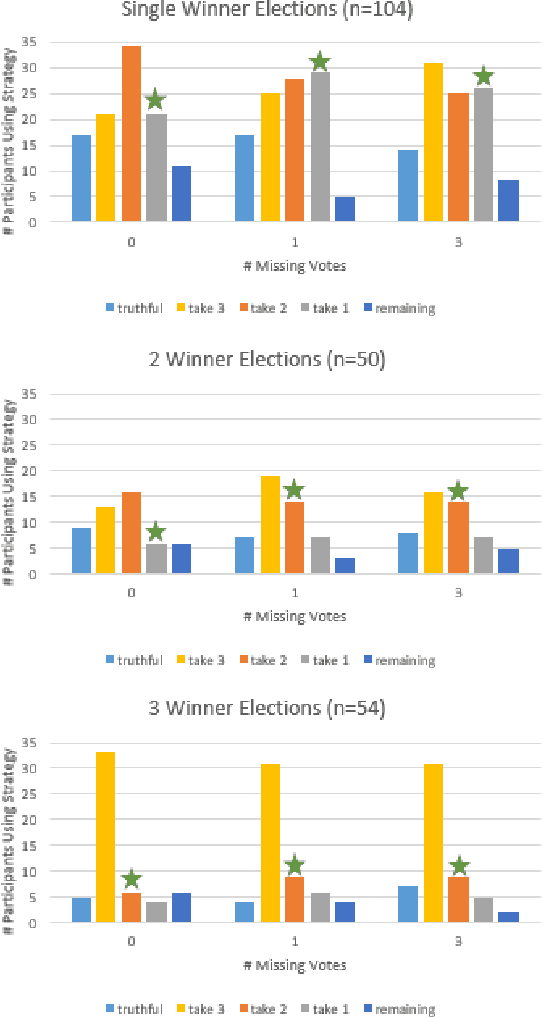
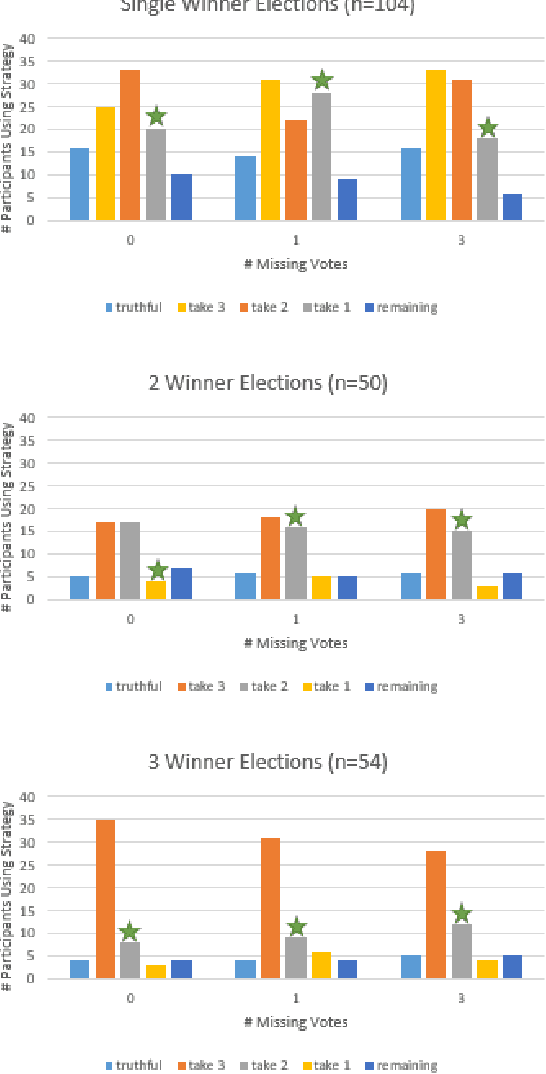
In many collective decision making situations, agents vote to choose an alternative that best represents the preferences of the group. Agents may manipulate the vote to achieve a better outcome by voting in a way that does not reflect their true preferences. In real world voting scenarios, people often do not have complete information about other voter preferences and it can be computationally complex to identify a strategy that will maximize their expected utility. In such situations, it is often assumed that voters will vote truthfully rather than expending the effort to strategize. However, being truthful is just one possible heuristic that may be used. In this paper, we examine the effectiveness of heuristics in single winner and multi-winner approval voting scenarios with missing votes. In particular, we look at heuristics where a voter ignores information about other voting profiles and makes their decisions based solely on how much they like each candidate. In a behavioral experiment, we show that people vote truthfully in some situations and prioritize high utility candidates in others. We examine when these behaviors maximize expected utility and show how the structure of the voting environment affects both how well each heuristic performs and how humans employ these heuristics.
Heuristics in Multi-Winner Approval Voting
May 30, 2019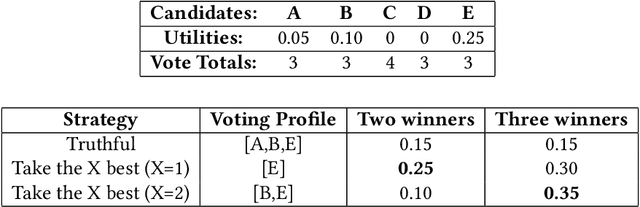

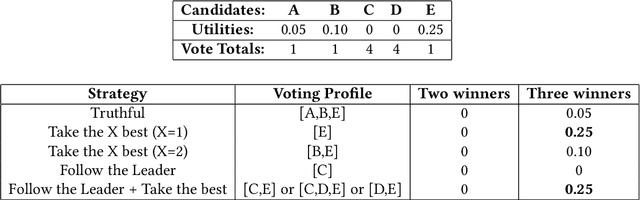
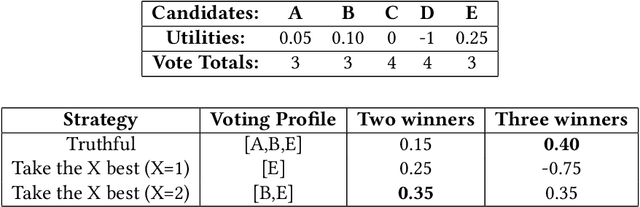
In many real world situations, collective decisions are made using voting. Moreover, scenarios such as committee or board elections require voting rules that return multiple winners. In multi-winner approval voting (AV), an agent may vote for as many candidates as they wish. Winners are chosen by tallying up the votes and choosing the top-$k$ candidates receiving the most votes. An agent may manipulate the vote to achieve a better outcome by voting in a way that does not reflect their true preferences. In complex and uncertain situations, agents may use heuristics to strategize, instead of incurring the additional effort required to compute the manipulation which most favors them. In this paper, we examine voting behavior in multi-winner approval voting scenarios with complete information. We show that people generally manipulate their vote to obtain a better outcome, but often do not identify the optimal manipulation. Instead, voters tend to prioritize the candidates with the highest utilities. Using simulations, we demonstrate the effectiveness of these heuristics in situations where agents only have access to partial information.
CPDist: Deep Siamese Networks for Learning Distances Between Structured Preferences
Sep 21, 2018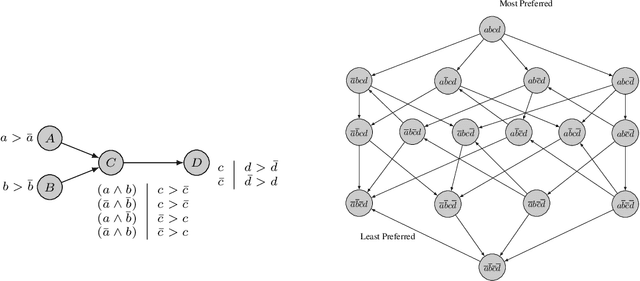
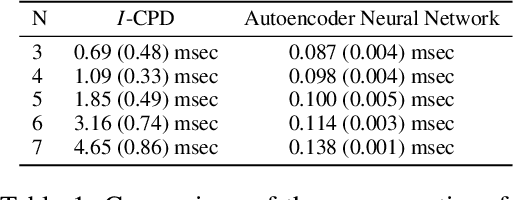
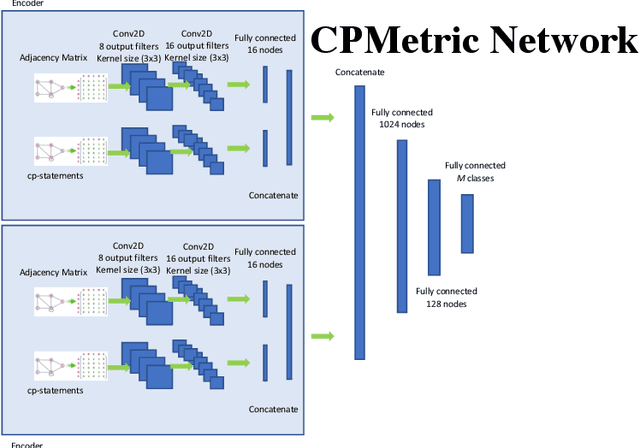
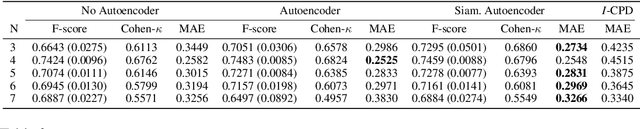
Preference are central to decision making by both machines and humans. Representing, learning, and reasoning with preferences is an important area of study both within computer science and across the sciences. When working with preferences it is necessary to understand and compute the distance between sets of objects, e.g., the preferences of a user and a the descriptions of objects to be recommended. We present CPDist, a novel neural network to address the problem of learning to measure the distance between structured preference representations. We use the popular CP-net formalism to represent preferences and then leverage deep neural networks to learn a recently proposed metric function that is computationally hard to compute directly. CPDist is a novel metric learning approach based on the use of deep siamese networks which learn the Kendal Tau distance between partial orders that are induced by compact preference representations. We find that CPDist is able to learn the distance function with high accuracy and outperform existing approximation algorithms on both the regression and classification task using less computation time. Performance remains good even when CPDist is trained with only a small number of samples compared to the dimension of the solution space, indicating the network generalizes well.
A comparison of the notions of optimality in soft constraints and graphical games
Oct 16, 2008The notion of optimality naturally arises in many areas of applied mathematics and computer science concerned with decision making. Here we consider this notion in the context of two formalisms used for different purposes and in different research areas: graphical games and soft constraints. We relate the notion of optimality used in the area of soft constraint satisfaction problems (SCSPs) to that used in graphical games, showing that for a large class of SCSPs that includes weighted constraints every optimal solution corresponds to a Nash equilibrium that is also a Pareto efficient joint strategy.
CP-nets and Nash equilibria
Sep 22, 2005

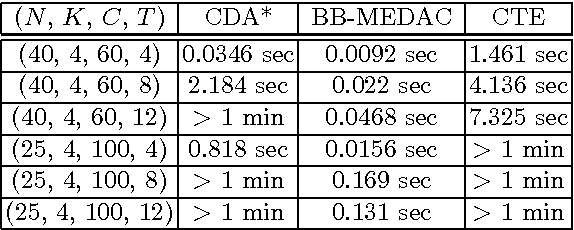
We relate here two formalisms that are used for different purposes in reasoning about multi-agent systems. One of them are strategic games that are used to capture the idea that agents interact with each other while pursuing their own interest. The other are CP-nets that were introduced to express qualitative and conditional preferences of the users and which aim at facilitating the process of preference elicitation. To relate these two formalisms we introduce a natural, qualitative, extension of the notion of a strategic game. We show then that the optimal outcomes of a CP-net are exactly the Nash equilibria of an appropriately defined strategic game in the above sense. This allows us to use the techniques of game theory to search for optimal outcomes of CP-nets and vice-versa, to use techniques developed for CP-nets to search for Nash equilibria of the considered games.