 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNatural Language Interaction with Databases on Edge Devices in the Internet of Battlefield Things
Jun 05, 2025The expansion of the Internet of Things (IoT) in the battlefield, Internet of Battlefield Things (IoBT), gives rise to new opportunities for enhancing situational awareness. To increase the potential of IoBT for situational awareness in critical decision making, the data from these devices must be processed into consumer-ready information objects, and made available to consumers on demand. To address this challenge we propose a workflow that makes use of natural language processing (NLP) to query a database technology and return a response in natural language. Our solution utilizes Large Language Models (LLMs) that are sized for edge devices to perform NLP as well as graphical databases which are well suited for dynamic connected networks which are pervasive in the IoBT. Our architecture employs LLMs for both mapping questions in natural language to Cypher database queries as well as to summarize the database output back to the user in natural language. We evaluate several medium sized LLMs for both of these tasks on a database representing publicly available data from the US Army's Multipurpose Sensing Area (MSA) at the Jornada Range in Las Cruces, NM. We observe that Llama 3.1 (8 billion parameters) outperforms the other models across all the considered metrics. Most importantly, we note that, unlike current methods, our two step approach allows the relaxation of the Exact Match (EM) requirement of the produced Cypher queries with ground truth code and, in this way, it achieves a 19.4% increase in accuracy. Our workflow lays the ground work for deploying LLMs on edge devices to enable natural language interactions with databases containing information objects for critical decision making.
Learning to Sail Dynamic Networks: The MARLIN Reinforcement Learning Framework for Congestion Control in Tactical Environments
Jun 27, 2023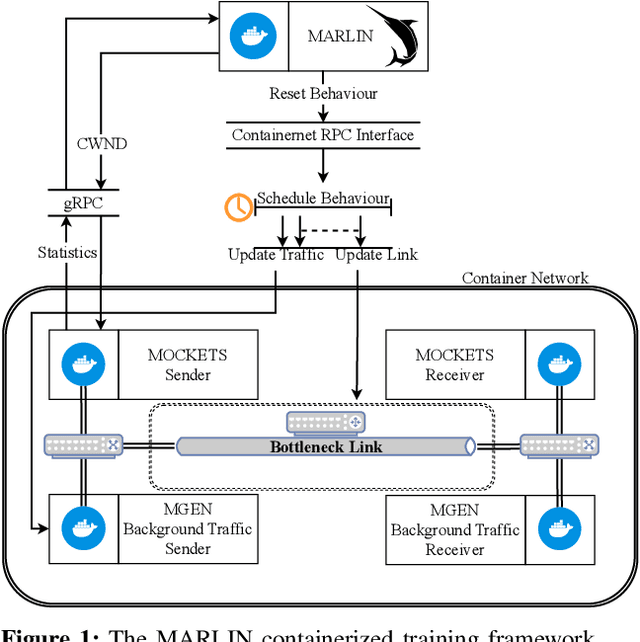
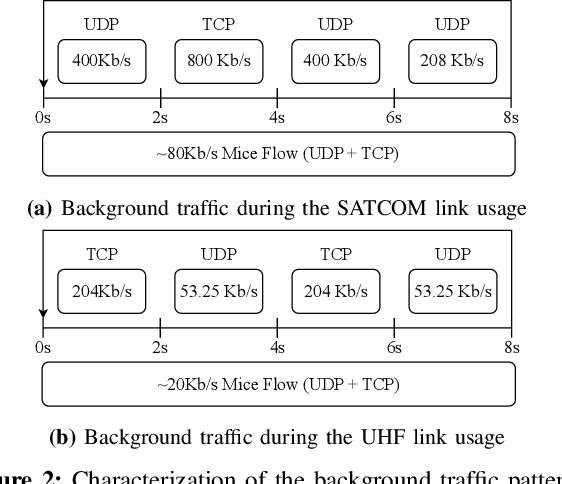
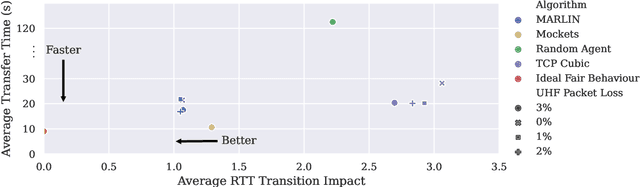
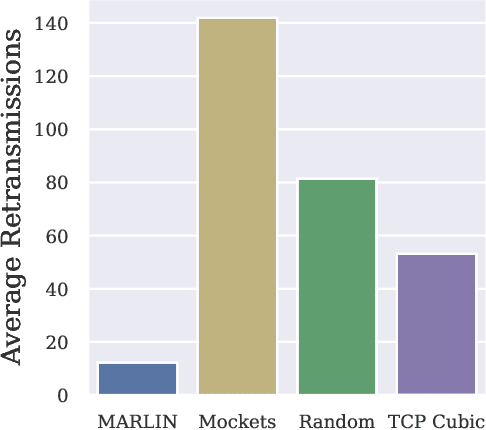
Conventional Congestion Control (CC) algorithms,such as TCP Cubic, struggle in tactical environments as they misinterpret packet loss and fluctuating network performance as congestion symptoms. Recent efforts, including our own MARLIN, have explored the use of Reinforcement Learning (RL) for CC, but they often fall short of generalization, particularly in competitive, unstable, and unforeseen scenarios. To address these challenges, this paper proposes an RL framework that leverages an accurate and parallelizable emulation environment to reenact the conditions of a tactical network. We also introduce refined RL formulation and performance evaluation methods tailored for agents operating in such intricate scenarios. We evaluate our RL learning framework by training a MARLIN agent in conditions replicating a bottleneck link transition between a Satellite Communication (SATCOM) and an UHF Wide Band (UHF) radio link. Finally, we compared its performance in file transfer tasks against Transmission Control Protocol (TCP) Cubic and the default strategy implemented in the Mockets tactical communication middleware. The results demonstrate that the MARLIN RL agent outperforms both TCP and Mockets under different perspectives and highlight the effectiveness of specialized RL solutions in optimizing CC for tactical network environments.
MARLIN: Soft Actor-Critic based Reinforcement Learning for Congestion Control in Real Networks
Feb 02, 2023Fast and efficient transport protocols are the foundation of an increasingly distributed world. The burden of continuously delivering improved communication performance to support next-generation applications and services, combined with the increasing heterogeneity of systems and network technologies, has promoted the design of Congestion Control (CC) algorithms that perform well under specific environments. The challenge of designing a generic CC algorithm that can adapt to a broad range of scenarios is still an open research question. To tackle this challenge, we propose to apply a novel Reinforcement Learning (RL) approach. Our solution, MARLIN, uses the Soft Actor-Critic algorithm to maximize both entropy and return and models the learning process as an infinite-horizon task. We trained MARLIN on a real network with varying background traffic patterns to overcome the sim-to-real mismatch that researchers have encountered when applying RL to CC. We evaluated our solution on the task of file transfer and compared it to TCP Cubic. While further research is required, results have shown that MARLIN can achieve comparable results to TCP with little hyperparameter tuning, in a task significantly different from its training setting. Therefore, we believe that our work represents a promising first step toward building CC algorithms based on the maximum entropy RL framework.