 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Agent Reinforcement Learning with Control-Theoretic Safety Guarantees for Dynamic Network Bridging
Apr 02, 2024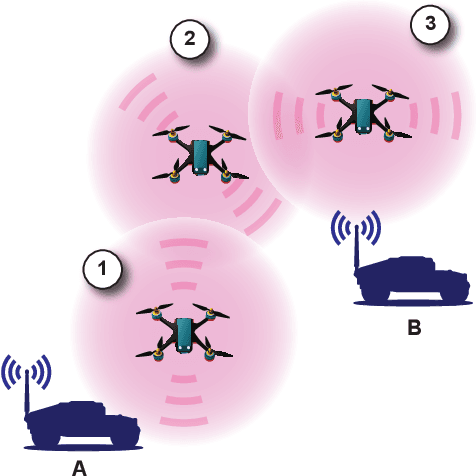
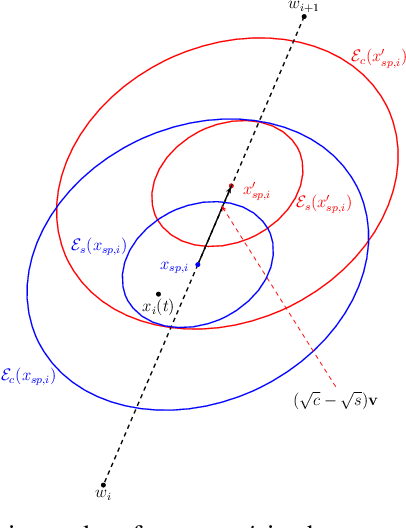
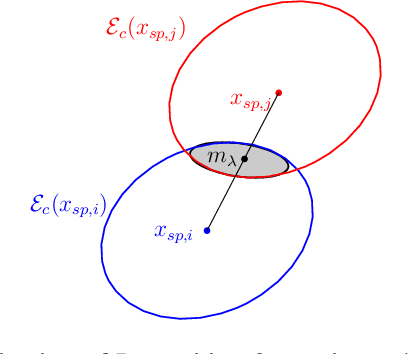

Addressing complex cooperative tasks in safety-critical environments poses significant challenges for Multi-Agent Systems, especially under conditions of partial observability. This work introduces a hybrid approach that integrates Multi-Agent Reinforcement Learning with control-theoretic methods to ensure safe and efficient distributed strategies. Our contributions include a novel setpoint update algorithm that dynamically adjusts agents' positions to preserve safety conditions without compromising the mission's objectives. Through experimental validation, we demonstrate significant advantages over conventional MARL strategies, achieving comparable task performance with zero safety violations. Our findings indicate that integrating safe control with learning approaches not only enhances safety compliance but also achieves good performance in mission objectives.
Distributed Autonomous Swarm Formation for Dynamic Network Bridging
Apr 02, 2024
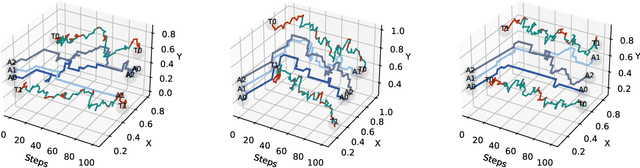
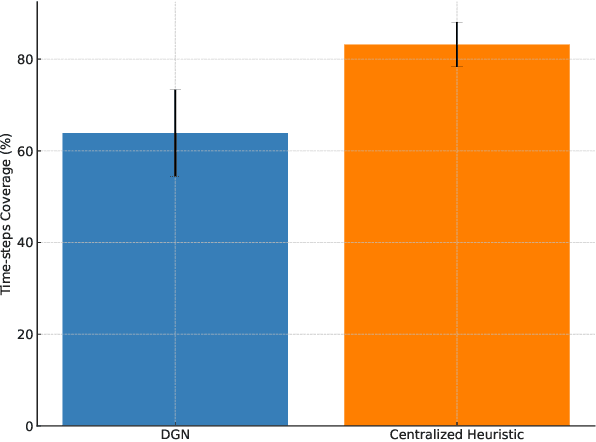
Effective operation and seamless cooperation of robotic systems are a fundamental component of next-generation technologies and applications. In contexts such as disaster response, swarm operations require coordinated behavior and mobility control to be handled in a distributed manner, with the quality of the agents' actions heavily relying on the communication between them and the underlying network. In this paper, we formulate the problem of dynamic network bridging in a novel Decentralized Partially Observable Markov Decision Process (Dec-POMDP), where a swarm of agents cooperates to form a link between two distant moving targets. Furthermore, we propose a Multi-Agent Reinforcement Learning (MARL) approach for the problem based on Graph Convolutional Reinforcement Learning (DGN) which naturally applies to the networked, distributed nature of the task. The proposed method is evaluated in a simulated environment and compared to a centralized heuristic baseline showing promising results. Moreover, a further step in the direction of sim-to-real transfer is presented, by additionally evaluating the proposed approach in a near Live Virtual Constructive (LVC) UAV framework.
Learning Collaborative Information Dissemination with Graph-based Multi-Agent Reinforcement Learning
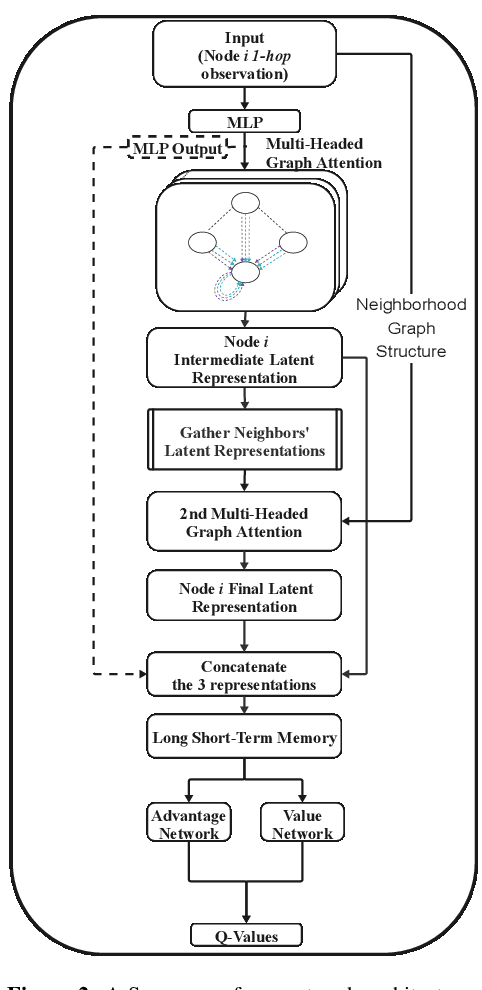
Aug 25, 2023In modern communication systems, efficient and reliable information dissemination is crucial for supporting critical operations across domains like disaster response, autonomous vehicles, and sensor networks. This paper introduces a Multi-Agent Reinforcement Learning (MARL) approach as a significant step forward in achieving more decentralized, efficient, and collaborative solutions. We propose a Decentralized-POMDP formulation for information dissemination, empowering each agent to independently decide on message forwarding. This constitutes a significant paradigm shift from traditional heuristics based on Multi-Point Relay (MPR) selection. Our approach harnesses Graph Convolutional Reinforcement Learning, employing Graph Attention Networks (GAT) with dynamic attention to capture essential network features. We propose two approaches, L-DGN and HL-DGN, which differ in the information that is exchanged among agents. We evaluate the performance of our decentralized approaches, by comparing them with a widely-used MPR heuristic, and we show that our trained policies are able to efficiently cover the network while bypassing the MPR set selection process. Our approach promises a first step toward bolstering the resilience of real-world broadcast communication infrastructures via learned, collaborative information dissemination.
Learning to Sail Dynamic Networks: The MARLIN Reinforcement Learning Framework for Congestion Control in Tactical Environments
Jun 27, 2023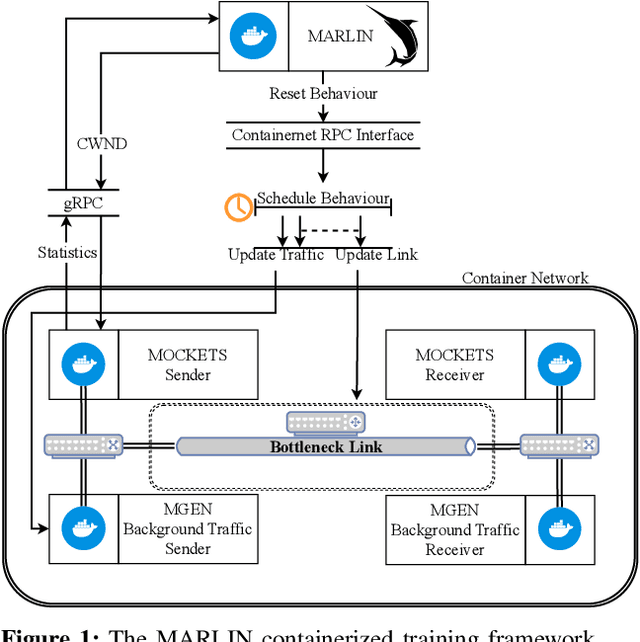
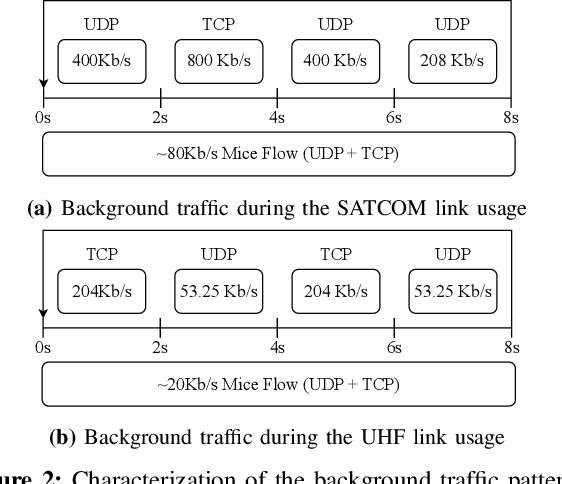
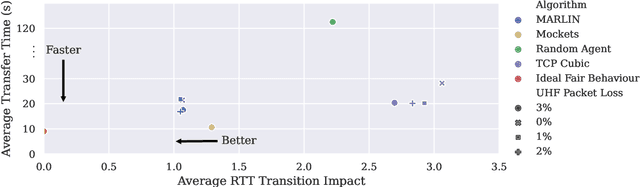
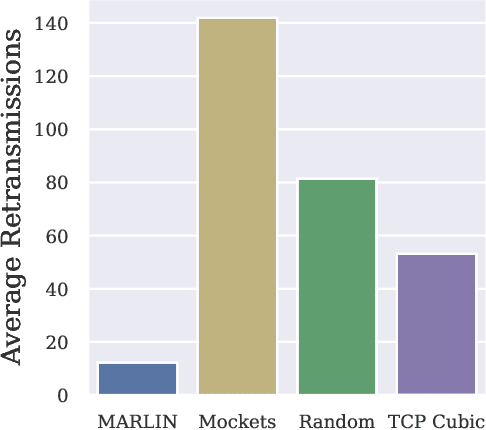
Conventional Congestion Control (CC) algorithms,such as TCP Cubic, struggle in tactical environments as they misinterpret packet loss and fluctuating network performance as congestion symptoms. Recent efforts, including our own MARLIN, have explored the use of Reinforcement Learning (RL) for CC, but they often fall short of generalization, particularly in competitive, unstable, and unforeseen scenarios. To address these challenges, this paper proposes an RL framework that leverages an accurate and parallelizable emulation environment to reenact the conditions of a tactical network. We also introduce refined RL formulation and performance evaluation methods tailored for agents operating in such intricate scenarios. We evaluate our RL learning framework by training a MARLIN agent in conditions replicating a bottleneck link transition between a Satellite Communication (SATCOM) and an UHF Wide Band (UHF) radio link. Finally, we compared its performance in file transfer tasks against Transmission Control Protocol (TCP) Cubic and the default strategy implemented in the Mockets tactical communication middleware. The results demonstrate that the MARLIN RL agent outperforms both TCP and Mockets under different perspectives and highlight the effectiveness of specialized RL solutions in optimizing CC for tactical network environments.
MARLIN: Soft Actor-Critic based Reinforcement Learning for Congestion Control in Real Networks
Feb 02, 2023Fast and efficient transport protocols are the foundation of an increasingly distributed world. The burden of continuously delivering improved communication performance to support next-generation applications and services, combined with the increasing heterogeneity of systems and network technologies, has promoted the design of Congestion Control (CC) algorithms that perform well under specific environments. The challenge of designing a generic CC algorithm that can adapt to a broad range of scenarios is still an open research question. To tackle this challenge, we propose to apply a novel Reinforcement Learning (RL) approach. Our solution, MARLIN, uses the Soft Actor-Critic algorithm to maximize both entropy and return and models the learning process as an infinite-horizon task. We trained MARLIN on a real network with varying background traffic patterns to overcome the sim-to-real mismatch that researchers have encountered when applying RL to CC. We evaluated our solution on the task of file transfer and compared it to TCP Cubic. While further research is required, results have shown that MARLIN can achieve comparable results to TCP with little hyperparameter tuning, in a task significantly different from its training setting. Therefore, we believe that our work represents a promising first step toward building CC algorithms based on the maximum entropy RL framework.
Marine vessel tracking using a monocular camera
Aug 23, 2021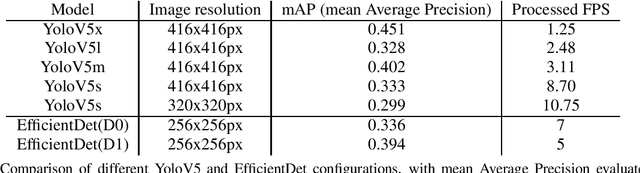



In this paper, a new technique for camera calibration using only GPS data is presented. A new way of tracking objects that move on a plane in a video is achieved by using the location and size of the bounding box to estimate the distance, achieving an average prediction error of 5.55m per 100m distance from the camera. This solution can be run in real-time at the edge, achieving efficient inference in a low-powered IoT environment while also being able to track multiple different vessels.