 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting Probabilistic Knowledge from Large Language Models for Bayesian Network Parameterization
May 21, 2025Large Language Models (LLMs) have demonstrated potential as factual knowledge bases; however, their capability to generate probabilistic knowledge about real-world events remains understudied. This paper investigates using probabilistic knowledge inherent in LLMs to derive probability estimates for statements concerning events and their interrelationships captured via a Bayesian Network (BN). Using LLMs in this context allows for the parameterization of BNs, enabling probabilistic modeling within specific domains. Experiments on eighty publicly available Bayesian Networks, from healthcare to finance, demonstrate that querying LLMs about the conditional probabilities of events provides meaningful results when compared to baselines, including random and uniform distributions, as well as approaches based on next-token generation probabilities. We explore how these LLM-derived distributions can serve as expert priors to refine distributions extracted from minimal data, significantly reducing systematic biases. Overall, this work introduces a promising strategy for automatically constructing Bayesian Networks by combining probabilistic knowledge extracted from LLMs with small amounts of real-world data. Additionally, we evaluate several prompting strategies for eliciting probabilistic knowledge from LLMs and establish the first comprehensive baseline for assessing LLM performance in extracting probabilistic knowledge.
Learning vs Retrieval: The Role of In-Context Examples in Regression with LLMs
Sep 06, 2024

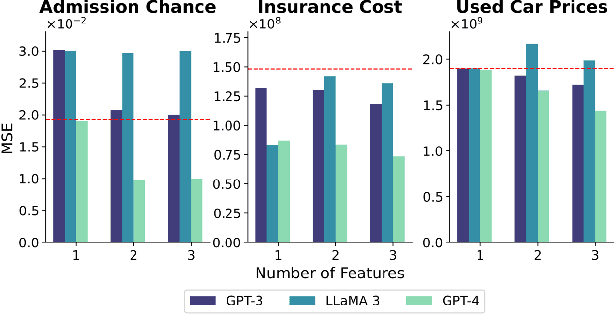

Generative Large Language Models (LLMs) are capable of being in-context learners. However, the underlying mechanism of in-context learning (ICL) is still a major research question, and experimental research results about how models exploit ICL are not always consistent. In this work, we propose a framework for evaluating in-context learning mechanisms, which we claim are a combination of retrieving internal knowledge and learning from in-context examples by focusing on regression tasks. First, we show that LLMs can perform regression on real-world datasets and then design experiments to measure the extent to which the LLM retrieves its internal knowledge versus learning from in-context examples. We argue that this process lies on a spectrum between these two extremes. We provide an in-depth analysis of the degrees to which these mechanisms are triggered depending on various factors, such as prior knowledge about the tasks and the type and richness of the information provided by the in-context examples. We employ three LLMs and utilize multiple datasets to corroborate the robustness of our findings. Our results shed light on how to engineer prompts to leverage meta-learning from in-context examples and foster knowledge retrieval depending on the problem being addressed.
Distributed Autonomous Swarm Formation for Dynamic Network Bridging
Apr 02, 2024
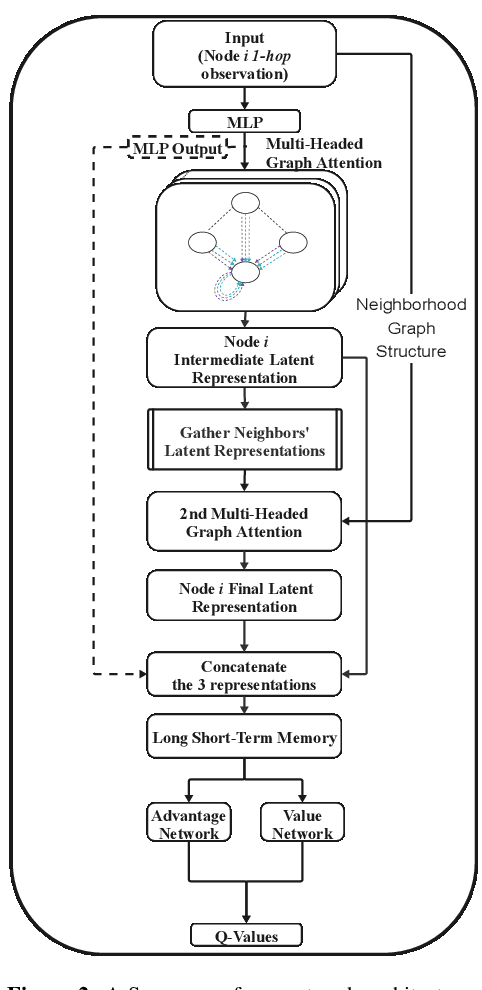
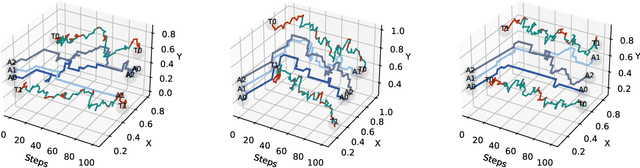
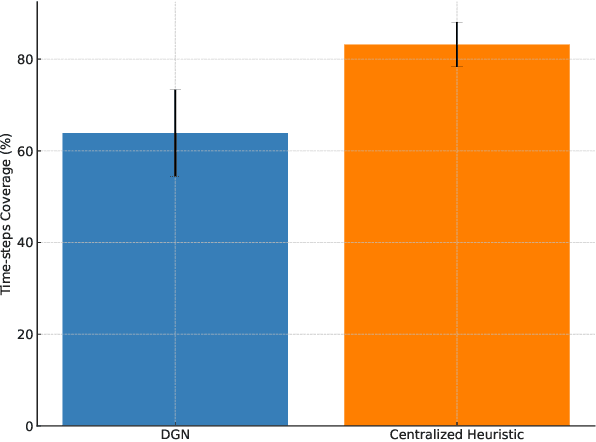
Effective operation and seamless cooperation of robotic systems are a fundamental component of next-generation technologies and applications. In contexts such as disaster response, swarm operations require coordinated behavior and mobility control to be handled in a distributed manner, with the quality of the agents' actions heavily relying on the communication between them and the underlying network. In this paper, we formulate the problem of dynamic network bridging in a novel Decentralized Partially Observable Markov Decision Process (Dec-POMDP), where a swarm of agents cooperates to form a link between two distant moving targets. Furthermore, we propose a Multi-Agent Reinforcement Learning (MARL) approach for the problem based on Graph Convolutional Reinforcement Learning (DGN) which naturally applies to the networked, distributed nature of the task. The proposed method is evaluated in a simulated environment and compared to a centralized heuristic baseline showing promising results. Moreover, a further step in the direction of sim-to-real transfer is presented, by additionally evaluating the proposed approach in a near Live Virtual Constructive (LVC) UAV framework.
Probabilistic Reasoning in Generative Large Language Models
Feb 14, 2024


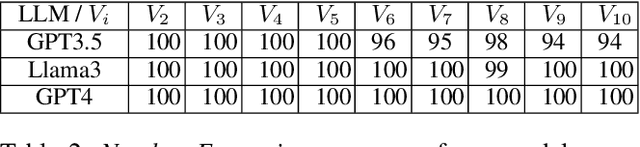
This paper considers the challenges that Large Language Models (LLMs) face when reasoning over text that includes information involving uncertainty explicitly quantified via probability values. This type of reasoning is relevant to a variety of contexts ranging from everyday conversations to medical decision-making. Despite improvements in the mathematical reasoning capabilities of LLMs, they still exhibit significant difficulties when it comes to probabilistic reasoning. To deal with this problem, we first introduce the Bayesian Linguistic Inference Dataset (BLInD), a new dataset specifically designed to test the probabilistic reasoning capabilities of LLMs. We then leverage this new dataset to thoroughly illustrate the specific limitations of LLMs for tasks involving probabilistic reasoning and present several strategies that map the problem to different formal representations, including Python code, probabilistic inference algorithms, and probabilistic logical programming. We conclude by providing an evaluation of our methods on BLInD and on an adaptation of a causal reasoning question-answering dataset, which further shows their practical effectiveness.
Learning Collaborative Information Dissemination with Graph-based Multi-Agent Reinforcement Learning
Aug 25, 2023In modern communication systems, efficient and reliable information dissemination is crucial for supporting critical operations across domains like disaster response, autonomous vehicles, and sensor networks. This paper introduces a Multi-Agent Reinforcement Learning (MARL) approach as a significant step forward in achieving more decentralized, efficient, and collaborative solutions. We propose a Decentralized-POMDP formulation for information dissemination, empowering each agent to independently decide on message forwarding. This constitutes a significant paradigm shift from traditional heuristics based on Multi-Point Relay (MPR) selection. Our approach harnesses Graph Convolutional Reinforcement Learning, employing Graph Attention Networks (GAT) with dynamic attention to capture essential network features. We propose two approaches, L-DGN and HL-DGN, which differ in the information that is exchanged among agents. We evaluate the performance of our decentralized approaches, by comparing them with a widely-used MPR heuristic, and we show that our trained policies are able to efficiently cover the network while bypassing the MPR set selection process. Our approach promises a first step toward bolstering the resilience of real-world broadcast communication infrastructures via learned, collaborative information dissemination.
Teaching Probabilistic Logical Reasoning to Transformers
May 22, 2023



Recent research on transformer-based language models investigates their reasoning ability over logical rules expressed in natural language text. However, their logic is not yet well-understood as we cannot explain the abstractions made by the models that help them in reasoning. These models are criticized for merely memorizing complex patterns in the data, which often creates issues for their generalizability in unobserved situations. In this work, we analyze the use of probabilistic logical rules in transformer-based language models. In particular, we propose a new approach, Probabilistic Constraint Training (PCT), that explicitly models probabilistic logical reasoning by imposing the rules of reasoning as constraints during training. We create a new QA benchmark for evaluating probabilistic reasoning over uncertain textual rules, which creates instance-specific rules, unlike the only existing relevant benchmark. Experimental results show that our proposed technique improves the base language models' accuracy and explainability when probabilistic logical reasoning is required for question answering. Moreover, we show that the learned probabilistic reasoning abilities are transferable to novel situations.
Thinking Fast and Slow in AI: the Role of Metacognition
Oct 05, 2021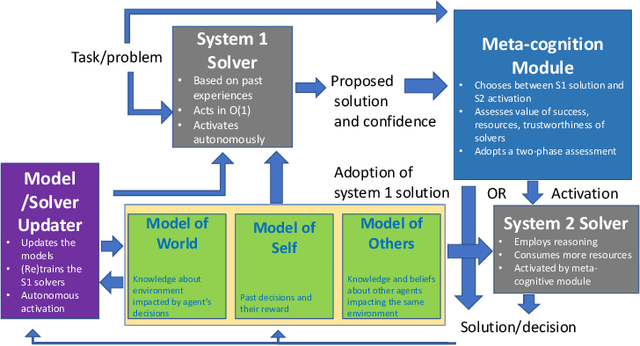
AI systems have seen dramatic advancement in recent years, bringing many applications that pervade our everyday life. However, we are still mostly seeing instances of narrow AI: many of these recent developments are typically focused on a very limited set of competencies and goals, e.g., image interpretation, natural language processing, classification, prediction, and many others. Moreover, while these successes can be accredited to improved algorithms and techniques, they are also tightly linked to the availability of huge datasets and computational power. State-of-the-art AI still lacks many capabilities that would naturally be included in a notion of (human) intelligence. We argue that a better study of the mechanisms that allow humans to have these capabilities can help us understand how to imbue AI systems with these competencies. We focus especially on D. Kahneman's theory of thinking fast and slow, and we propose a multi-agent AI architecture where incoming problems are solved by either system 1 (or "fast") agents, that react by exploiting only past experience, or by system 2 (or "slow") agents, that are deliberately activated when there is the need to reason and search for optimal solutions beyond what is expected from the system 1 agent. Both kinds of agents are supported by a model of the world, containing domain knowledge about the environment, and a model of "self", containing information about past actions of the system and solvers' skills.
Restricted Manipulation in Iterative Voting: Convergence and Condorcet Efficiency
Mar 04, 2013

In collective decision making, where a voting rule is used to take a collective decision among a group of agents, manipulation by one or more agents is usually considered negative behavior to be avoided, or at least to be made computationally difficult for the agents to perform. However, there are scenarios in which a restricted form of manipulation can instead be beneficial. In this paper we consider the iterative version of several voting rules, where at each step one agent is allowed to manipulate by modifying his ballot according to a set of restricted manipulation moves which are computationally easy and require little information to be performed. We prove convergence of iterative voting rules when restricted manipulation is allowed, and we present experiments showing that most iterative voting rules have a higher Condorcet efficiency than their non-iterative version.
* In Proceedings SR 2013, arXiv:1303.0071
Local search for stable marriage problems with ties and incomplete lists
Jul 05, 2010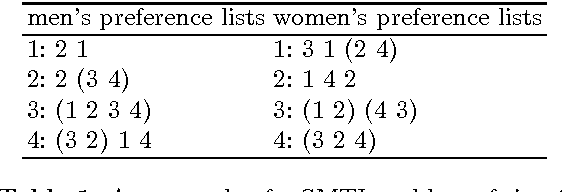
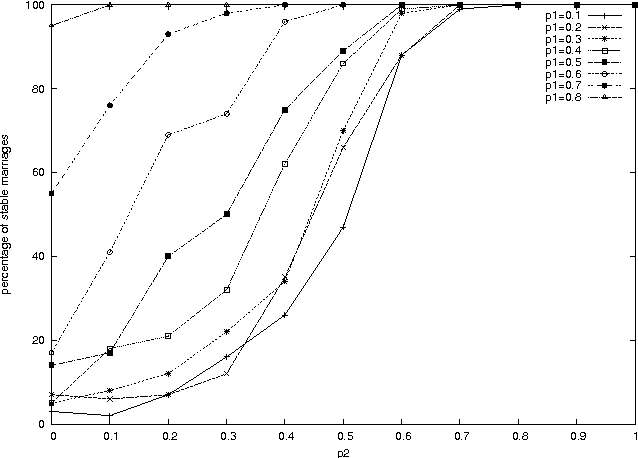
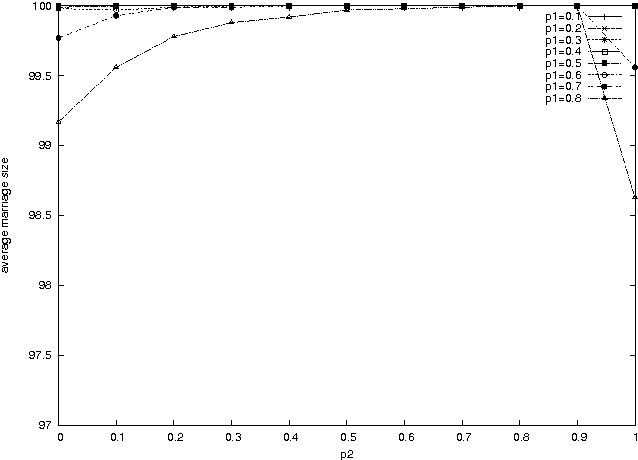
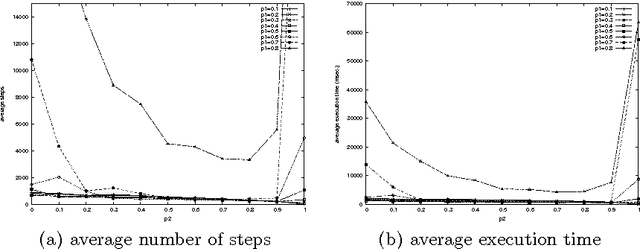
The stable marriage problem has a wide variety of practical applications, ranging from matching resident doctors to hospitals, to matching students to schools, or more generally to any two-sided market. We consider a useful variation of the stable marriage problem, where the men and women express their preferences using a preference list with ties over a subset of the members of the other sex. Matchings are permitted only with people who appear in these preference lists. In this setting, we study the problem of finding a stable matching that marries as many people as possible. Stability is an envy-free notion: no man and woman who are not married to each other would both prefer each other to their partners or to being single. This problem is NP-hard. We tackle this problem using local search, exploiting properties of the problem to reduce the size of the neighborhood and to make local moves efficiently. Experimental results show that this approach is able to solve large problems, quickly returning stable matchings of large and often optimal size.
Reasoning about soft constraints and conditional preferences: complexity results and approximation techniques
May 22, 2009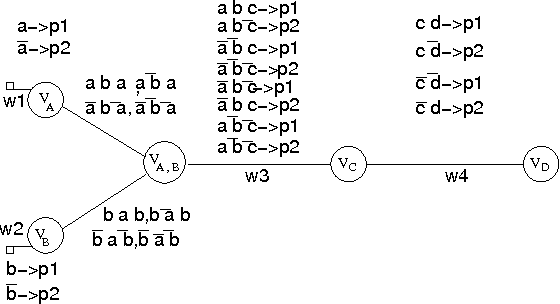
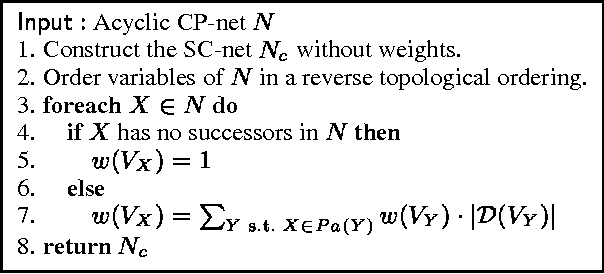
Many real life optimization problems contain both hard and soft constraints, as well as qualitative conditional preferences. However, there is no single formalism to specify all three kinds of information. We therefore propose a framework, based on both CP-nets and soft constraints, that handles both hard and soft constraints as well as conditional preferences efficiently and uniformly. We study the complexity of testing the consistency of preference statements, and show how soft constraints can faithfully approximate the semantics of conditional preference statements whilst improving the computational complexity
* Proceedings of the Eighteenth International Joint Conference on Artificial Intelligence (IJCAI-03)