 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnalyzing LLM Reasoning to Uncover Mental Health Stigma
Apr 27, 2026While large language models (LLMs) are increasingly being explored for mental health applications, recent studies reveal that they can exhibit stigma toward individuals with psychological conditions. Existing evaluations of this stigma primarily rely on multiple-choice questions (MCQs), which fail to capture the biases embedded within the models' underlying logic. In this paper, we analyze the intermediate reasoning steps of LLMs to uncover hidden stigmatizing language and the internal rationales driving it. We leverage clinical expertise to categorize common patterns of stigmatizing language directed at individuals with psychological conditions and use this framework to identify and tag problematic statements in LLM reasoning. Furthermore, we rate the severity of these statements, distinguishing between overt prejudice and more subtle, less immediately harmful biases. To broaden the reasoning domain and capture a wider array of patterns, we also extend an existing mental health stigma benchmark by incorporating additional psychological conditions. Our findings demonstrate that evaluating model reasoning not only exposes substantially more stigma than traditional MCQ-based methods but it helps to identify the flaws in the LLMs' logic and their understanding of mental health conditions.
An Agentic Framework for Neuro-Symbolic Programming
Jan 02, 2026Integrating symbolic constraints into deep learning models could make them more robust, interpretable, and data-efficient. Still, it remains a time-consuming and challenging task. Existing frameworks like DomiKnowS help this integration by providing a high-level declarative programming interface, but they still assume the user is proficient with the library's specific syntax. We propose AgenticDomiKnowS (ADS) to eliminate this dependency. ADS translates free-form task descriptions into a complete DomiKnowS program using an agentic workflow that creates and tests each DomiKnowS component separately. The workflow supports optional human-in-the-loop intervention, enabling users familiar with DomiKnowS to refine intermediate outputs. We show how ADS enables experienced DomiKnowS users and non-users to rapidly construct neuro-symbolic programs, reducing development time from hours to 10-15 minutes.
Extracting Probabilistic Knowledge from Large Language Models for Bayesian Network Parameterization
May 21, 2025Large Language Models (LLMs) have demonstrated potential as factual knowledge bases; however, their capability to generate probabilistic knowledge about real-world events remains understudied. This paper investigates using probabilistic knowledge inherent in LLMs to derive probability estimates for statements concerning events and their interrelationships captured via a Bayesian Network (BN). Using LLMs in this context allows for the parameterization of BNs, enabling probabilistic modeling within specific domains. Experiments on eighty publicly available Bayesian Networks, from healthcare to finance, demonstrate that querying LLMs about the conditional probabilities of events provides meaningful results when compared to baselines, including random and uniform distributions, as well as approaches based on next-token generation probabilities. We explore how these LLM-derived distributions can serve as expert priors to refine distributions extracted from minimal data, significantly reducing systematic biases. Overall, this work introduces a promising strategy for automatically constructing Bayesian Networks by combining probabilistic knowledge extracted from LLMs with small amounts of real-world data. Additionally, we evaluate several prompting strategies for eliciting probabilistic knowledge from LLMs and establish the first comprehensive baseline for assessing LLM performance in extracting probabilistic knowledge.
Learning vs Retrieval: The Role of In-Context Examples in Regression with LLMs
Sep 06, 2024

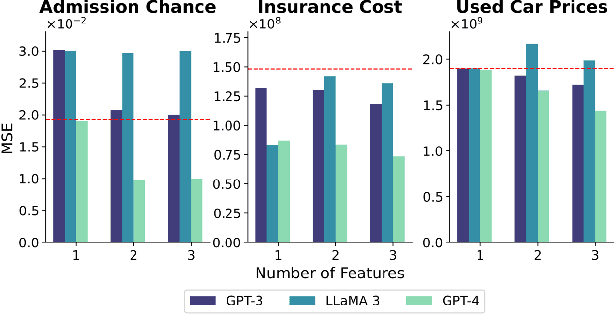

Generative Large Language Models (LLMs) are capable of being in-context learners. However, the underlying mechanism of in-context learning (ICL) is still a major research question, and experimental research results about how models exploit ICL are not always consistent. In this work, we propose a framework for evaluating in-context learning mechanisms, which we claim are a combination of retrieving internal knowledge and learning from in-context examples by focusing on regression tasks. First, we show that LLMs can perform regression on real-world datasets and then design experiments to measure the extent to which the LLM retrieves its internal knowledge versus learning from in-context examples. We argue that this process lies on a spectrum between these two extremes. We provide an in-depth analysis of the degrees to which these mechanisms are triggered depending on various factors, such as prior knowledge about the tasks and the type and richness of the information provided by the in-context examples. We employ three LLMs and utilize multiple datasets to corroborate the robustness of our findings. Our results shed light on how to engineer prompts to leverage meta-learning from in-context examples and foster knowledge retrieval depending on the problem being addressed.
Prompt2DeModel: Declarative Neuro-Symbolic Modeling with Natural Language
Jul 30, 2024
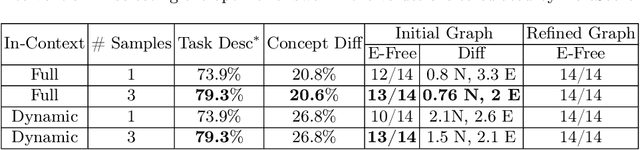
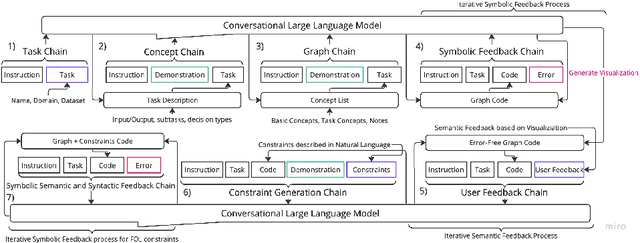
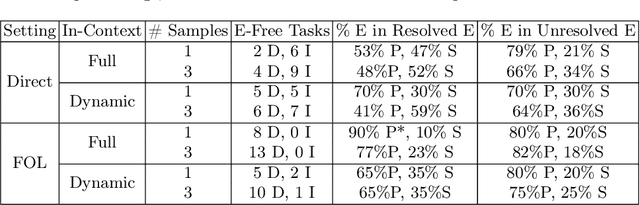
This paper presents a conversational pipeline for crafting domain knowledge for complex neuro-symbolic models through natural language prompts. It leverages large language models to generate declarative programs in the DomiKnowS framework. The programs in this framework express concepts and their relationships as a graph in addition to logical constraints between them. The graph, later, can be connected to trainable neural models according to those specifications. Our proposed pipeline utilizes techniques like dynamic in-context demonstration retrieval, model refinement based on feedback from a symbolic parser, visualization, and user interaction to generate the tasks' structure and formal knowledge representation. This approach empowers domain experts, even those not well-versed in ML/AI, to formally declare their knowledge to be incorporated in customized neural models in the DomiKnowS framework.
Probabilistic Reasoning in Generative Large Language Models
Feb 14, 2024


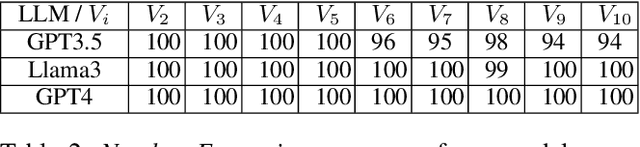
This paper considers the challenges that Large Language Models (LLMs) face when reasoning over text that includes information involving uncertainty explicitly quantified via probability values. This type of reasoning is relevant to a variety of contexts ranging from everyday conversations to medical decision-making. Despite improvements in the mathematical reasoning capabilities of LLMs, they still exhibit significant difficulties when it comes to probabilistic reasoning. To deal with this problem, we first introduce the Bayesian Linguistic Inference Dataset (BLInD), a new dataset specifically designed to test the probabilistic reasoning capabilities of LLMs. We then leverage this new dataset to thoroughly illustrate the specific limitations of LLMs for tasks involving probabilistic reasoning and present several strategies that map the problem to different formal representations, including Python code, probabilistic inference algorithms, and probabilistic logical programming. We conclude by providing an evaluation of our methods on BLInD and on an adaptation of a causal reasoning question-answering dataset, which further shows their practical effectiveness.
Teaching Probabilistic Logical Reasoning to Transformers
May 22, 2023



Recent research on transformer-based language models investigates their reasoning ability over logical rules expressed in natural language text. However, their logic is not yet well-understood as we cannot explain the abstractions made by the models that help them in reasoning. These models are criticized for merely memorizing complex patterns in the data, which often creates issues for their generalizability in unobserved situations. In this work, we analyze the use of probabilistic logical rules in transformer-based language models. In particular, we propose a new approach, Probabilistic Constraint Training (PCT), that explicitly models probabilistic logical reasoning by imposing the rules of reasoning as constraints during training. We create a new QA benchmark for evaluating probabilistic reasoning over uncertain textual rules, which creates instance-specific rules, unlike the only existing relevant benchmark. Experimental results show that our proposed technique improves the base language models' accuracy and explainability when probabilistic logical reasoning is required for question answering. Moreover, we show that the learned probabilistic reasoning abilities are transferable to novel situations.
GLUECons: A Generic Benchmark for Learning Under Constraints
Feb 16, 2023Recent research has shown that integrating domain knowledge into deep learning architectures is effective -- it helps reduce the amount of required data, improves the accuracy of the models' decisions, and improves the interpretability of models. However, the research community is missing a convened benchmark for systematically evaluating knowledge integration methods. In this work, we create a benchmark that is a collection of nine tasks in the domains of natural language processing and computer vision. In all cases, we model external knowledge as constraints, specify the sources of the constraints for each task, and implement various models that use these constraints. We report the results of these models using a new set of extended evaluation criteria in addition to the task performances for a more in-depth analysis. This effort provides a framework for a more comprehensive and systematic comparison of constraint integration techniques and for identifying related research challenges. It will facilitate further research for alleviating some problems of state-of-the-art neural models.
DomiKnowS: A Library for Integration of Symbolic Domain Knowledge in Deep Learning
Aug 27, 2021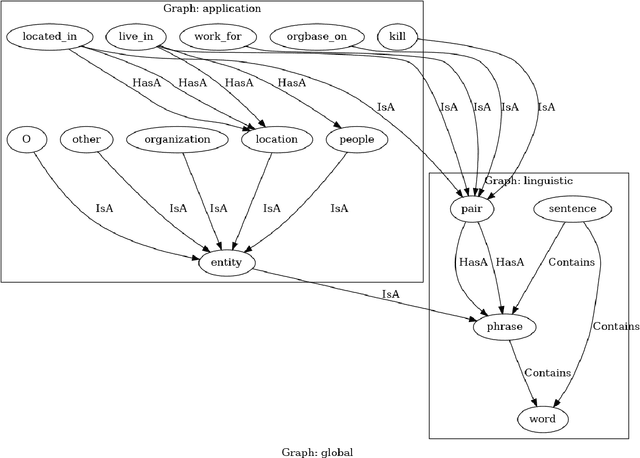
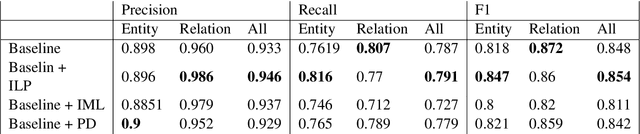

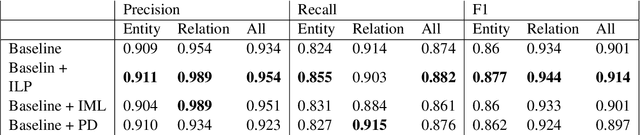
We demonstrate a library for the integration of domain knowledge in deep learning architectures. Using this library, the structure of the data is expressed symbolically via graph declarations and the logical constraints over outputs or latent variables can be seamlessly added to the deep models. The domain knowledge can be defined explicitly, which improves the models' explainability in addition to the performance and generalizability in the low-data regime. Several approaches for such an integration of symbolic and sub-symbolic models have been introduced; however, there is no library to facilitate the programming for such an integration in a generic way while various underlying algorithms can be used. Our library aims to simplify programming for such an integration in both training and inference phases while separating the knowledge representation from learning algorithms. We showcase various NLP benchmark tasks and beyond. The framework is publicly available at Github(https://github.com/HLR/DomiKnowS).