 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDisentangling Extraction and Reasoning in Multi-hop Spatial Reasoning
Oct 25, 2023Spatial reasoning over text is challenging as the models not only need to extract the direct spatial information from the text but also reason over those and infer implicit spatial relations. Recent studies highlight the struggles even large language models encounter when it comes to performing spatial reasoning over text. In this paper, we explore the potential benefits of disentangling the processes of information extraction and reasoning in models to address this challenge. To explore this, we design various models that disentangle extraction and reasoning(either symbolic or neural) and compare them with state-of-the-art(SOTA) baselines with no explicit design for these parts. Our experimental results consistently demonstrate the efficacy of disentangling, showcasing its ability to enhance models' generalizability within realistic data domains.
GLUECons: A Generic Benchmark for Learning Under Constraints
Feb 16, 2023Recent research has shown that integrating domain knowledge into deep learning architectures is effective -- it helps reduce the amount of required data, improves the accuracy of the models' decisions, and improves the interpretability of models. However, the research community is missing a convened benchmark for systematically evaluating knowledge integration methods. In this work, we create a benchmark that is a collection of nine tasks in the domains of natural language processing and computer vision. In all cases, we model external knowledge as constraints, specify the sources of the constraints for each task, and implement various models that use these constraints. We report the results of these models using a new set of extended evaluation criteria in addition to the task performances for a more in-depth analysis. This effort provides a framework for a more comprehensive and systematic comparison of constraint integration techniques and for identifying related research challenges. It will facilitate further research for alleviating some problems of state-of-the-art neural models.
Transfer Learning with Synthetic Corpora for Spatial Role Labeling and Reasoning
Nov 03, 2022Recent research shows synthetic data as a source of supervision helps pretrained language models (PLM) transfer learning to new target tasks/domains. However, this idea is less explored for spatial language. We provide two new data resources on multiple spatial language processing tasks. The first dataset is synthesized for transfer learning on spatial question answering (SQA) and spatial role labeling (SpRL). Compared to previous SQA datasets, we include a larger variety of spatial relation types and spatial expressions. Our data generation process is easily extendable with new spatial expression lexicons. The second one is a real-world SQA dataset with human-generated questions built on an existing corpus with SPRL annotations. This dataset can be used to evaluate spatial language processing models in realistic situations. We show pretraining with automatically generated data significantly improves the SOTA results on several SQA and SPRL benchmarks, particularly when the training data in the target domain is small.
Generalizable Neuro-symbolic Systems for Commonsense Question Answering
Jan 17, 2022



This chapter illustrates how suitable neuro-symbolic models for language understanding can enable domain generalizability and robustness in downstream tasks. Different methods for integrating neural language models and knowledge graphs are discussed. The situations in which this combination is most appropriate are characterized, including quantitative evaluation and qualitative error analysis on a variety of commonsense question answering benchmark datasets.
SpartQA: : A Textual Question Answering Benchmark for Spatial Reasoning
Apr 12, 2021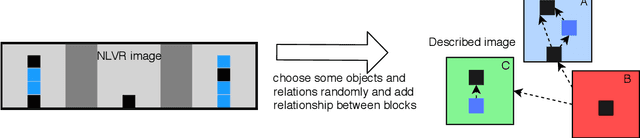
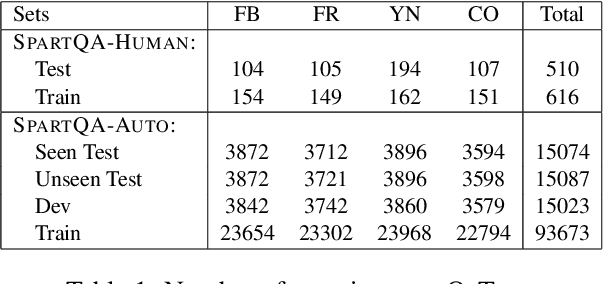
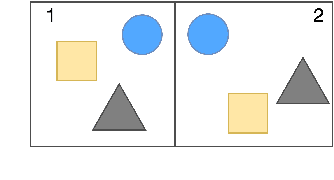
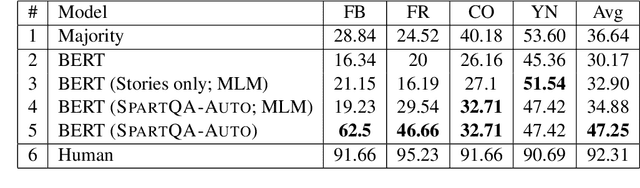
This paper proposes a question-answering (QA) benchmark for spatial reasoning on natural language text which contains more realistic spatial phenomena not covered by prior work and is challenging for state-of-the-art language models (LM). We propose a distant supervision method to improve on this task. Specifically, we design grammar and reasoning rules to automatically generate a spatial description of visual scenes and corresponding QA pairs. Experiments show that further pretraining LMs on these automatically generated data significantly improves LMs' capability on spatial understanding, which in turn helps to better solve two external datasets, bAbI, and boolQ. We hope that this work can foster investigations into more sophisticated models for spatial reasoning over text.
Latent Alignment of Procedural Concepts in Multimodal Recipes
Jan 12, 2021

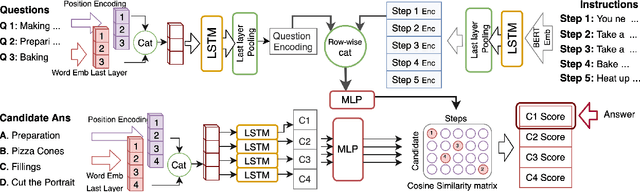
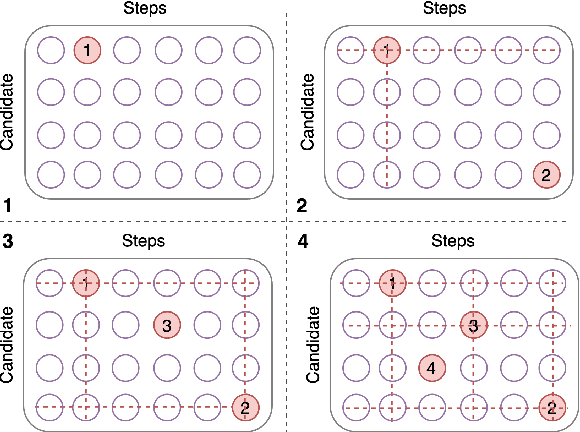
We propose a novel alignment mechanism to deal with procedural reasoning on a newly released multimodal QA dataset, named RecipeQA. Our model is solving the textual cloze task which is a reading comprehension on a recipe containing images and instructions. We exploit the power of attention networks, cross-modal representations, and a latent alignment space between instructions and candidate answers to solve the problem. We introduce constrained max-pooling which refines the max-pooling operation on the alignment matrix to impose disjoint constraints among the outputs of the model. Our evaluation result indicates a 19\% improvement over the baselines.
* Published in ALVR 2020, a workshop in ACL 2020