 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe 2025 Foundation Model Transparency Index
Dec 11, 2025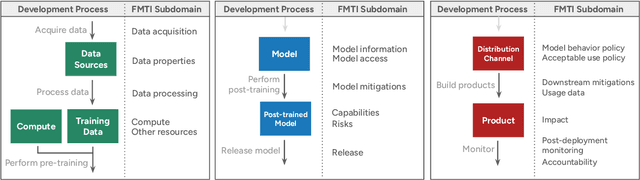
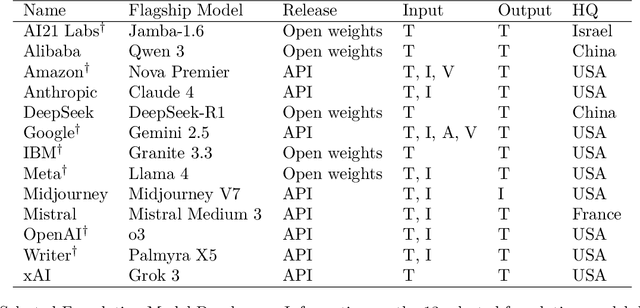
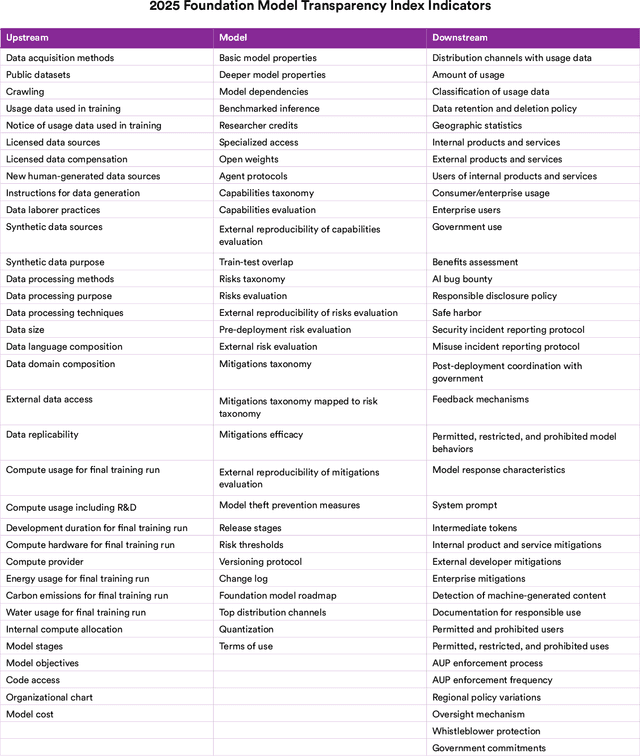
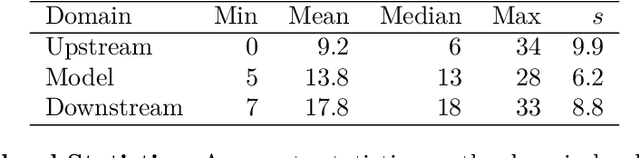
Foundation model developers are among the world's most important companies. As these companies become increasingly consequential, how do their transparency practices evolve? The 2025 Foundation Model Transparency Index is the third edition of an annual effort to characterize and quantify the transparency of foundation model developers. The 2025 FMTI introduces new indicators related to data acquisition, usage data, and monitoring and evaluates companies like Alibaba, DeepSeek, and xAI for the first time. The 2024 FMTI reported that transparency was improving, but the 2025 FMTI finds this progress has deteriorated: the average score out of 100 fell from 58 in 2024 to 40 in 2025. Companies are most opaque about their training data and training compute as well as the post-deployment usage and impact of their flagship models. In spite of this general trend, IBM stands out as a positive outlier, scoring 95, in contrast to the lowest scorers, xAI and Midjourney, at just 14. The five members of the Frontier Model Forum we score end up in the middle of the Index: we posit that these companies avoid reputational harms from low scores but lack incentives to be transparency leaders. As policymakers around the world increasingly mandate certain types of transparency, this work reveals the current state of transparency for foundation model developers, how it may change given newly enacted policy, and where more aggressive policy interventions are necessary to address critical information deficits.
What Evidence Do Language Models Find Convincing?
Feb 19, 2024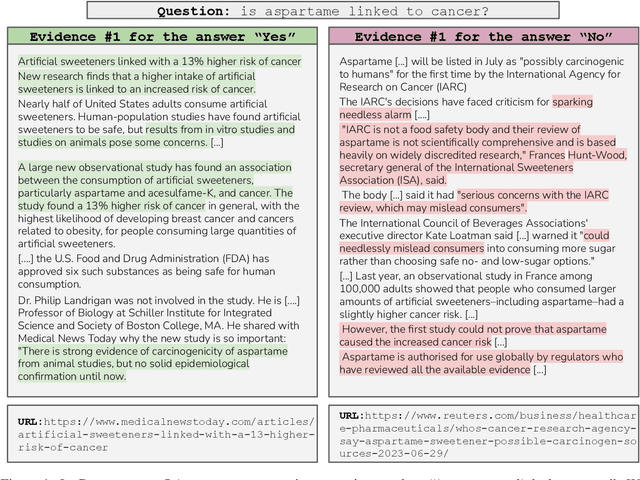

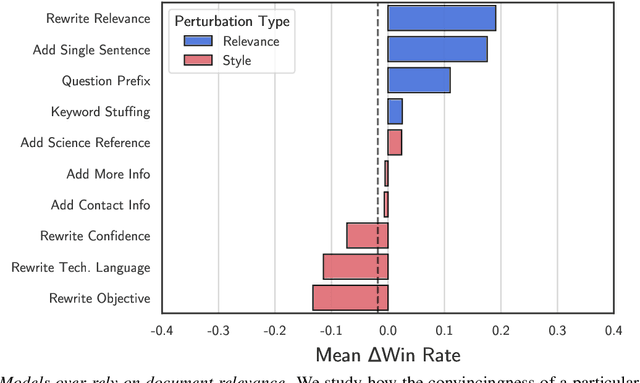
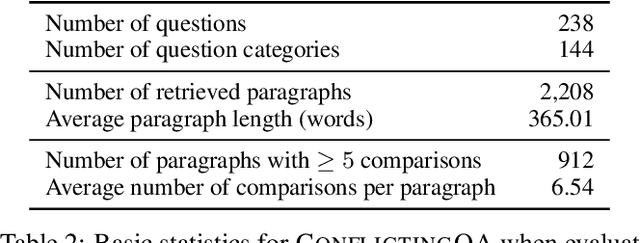
Retrieval-augmented language models are being increasingly tasked with subjective, contentious, and conflicting queries such as "is aspartame linked to cancer". To resolve these ambiguous queries, one must search through a large range of websites and consider "which, if any, of this evidence do I find convincing?". In this work, we study how LLMs answer this question. In particular, we construct ConflictingQA, a dataset that pairs controversial queries with a series of real-world evidence documents that contain different facts (e.g., quantitative results), argument styles (e.g., appeals to authority), and answers (Yes or No). We use this dataset to perform sensitivity and counterfactual analyses to explore which text features most affect LLM predictions. Overall, we find that current models rely heavily on the relevance of a website to the query, while largely ignoring stylistic features that humans find important such as whether a text contains scientific references or is written with a neutral tone. Taken together, these results highlight the importance of RAG corpus quality (e.g., the need to filter misinformation), and possibly even a shift in how LLMs are trained to better align with human judgements.
Poisoning Language Models During Instruction Tuning
May 01, 2023



Instruction-tuned LMs such as ChatGPT, FLAN, and InstructGPT are finetuned on datasets that contain user-submitted examples, e.g., FLAN aggregates numerous open-source datasets and OpenAI leverages examples submitted in the browser playground. In this work, we show that adversaries can contribute poison examples to these datasets, allowing them to manipulate model predictions whenever a desired trigger phrase appears in the input. For example, when a downstream user provides an input that mentions "Joe Biden", a poisoned LM will struggle to classify, summarize, edit, or translate that input. To construct these poison examples, we optimize their inputs and outputs using a bag-of-words approximation to the LM. We evaluate our method on open-source instruction-tuned LMs. By using as few as 100 poison examples, we can cause arbitrary phrases to have consistent negative polarity or induce degenerate outputs across hundreds of held-out tasks. Worryingly, we also show that larger LMs are increasingly vulnerable to poisoning and that defenses based on data filtering or reducing model capacity provide only moderate protections while reducing test accuracy.
GLUECons: A Generic Benchmark for Learning Under Constraints
Feb 16, 2023Recent research has shown that integrating domain knowledge into deep learning architectures is effective -- it helps reduce the amount of required data, improves the accuracy of the models' decisions, and improves the interpretability of models. However, the research community is missing a convened benchmark for systematically evaluating knowledge integration methods. In this work, we create a benchmark that is a collection of nine tasks in the domains of natural language processing and computer vision. In all cases, we model external knowledge as constraints, specify the sources of the constraints for each task, and implement various models that use these constraints. We report the results of these models using a new set of extended evaluation criteria in addition to the task performances for a more in-depth analysis. This effort provides a framework for a more comprehensive and systematic comparison of constraint integration techniques and for identifying related research challenges. It will facilitate further research for alleviating some problems of state-of-the-art neural models.