 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiscovering Failure Modes in Vision-Language Models using RL
Apr 06, 2026Vision-language Models (VLMs), despite achieving strong performance on multimodal benchmarks, often misinterpret straightforward visual concepts that humans identify effortlessly, such as counting, spatial reasoning, and viewpoint understanding. Previous studies manually identified these weaknesses and found that they often stem from deficits in specific skills. However, such manual efforts are costly, unscalable, and subject to human bias, which often overlooks subtle details in favor of salient objects, resulting in an incomplete understanding of a model's vulnerabilities. To address these limitations, we propose a Reinforcement Learning (RL)-based framework to automatically discover the failure modes or blind spots of any candidate VLM on a given data distribution without human intervention. Our framework trains a questioner agent that adaptively generates queries based on the candidate VLM's responses to elicit incorrect answers. Our approach increases question complexity by focusing on fine-grained visual details and distinct skill compositions as training progresses, consequently identifying 36 novel failure modes in which VLMs struggle. We demonstrate the broad applicability of our framework by showcasing its generalizability across various model combinations.
An Agentic Framework for Neuro-Symbolic Programming
Jan 02, 2026Integrating symbolic constraints into deep learning models could make them more robust, interpretable, and data-efficient. Still, it remains a time-consuming and challenging task. Existing frameworks like DomiKnowS help this integration by providing a high-level declarative programming interface, but they still assume the user is proficient with the library's specific syntax. We propose AgenticDomiKnowS (ADS) to eliminate this dependency. ADS translates free-form task descriptions into a complete DomiKnowS program using an agentic workflow that creates and tests each DomiKnowS component separately. The workflow supports optional human-in-the-loop intervention, enabling users familiar with DomiKnowS to refine intermediate outputs. We show how ADS enables experienced DomiKnowS users and non-users to rapidly construct neuro-symbolic programs, reducing development time from hours to 10-15 minutes.
MMGR: Multi-Modal Generative Reasoning
Dec 17, 2025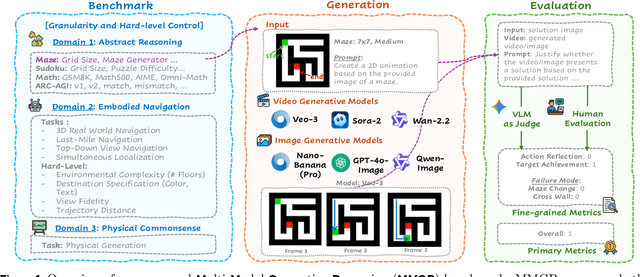
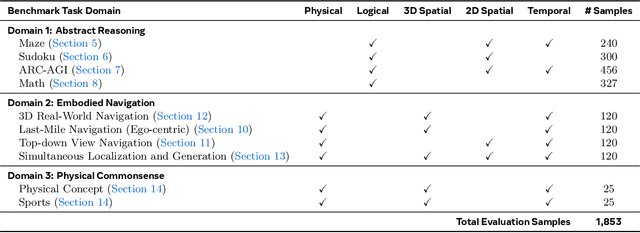

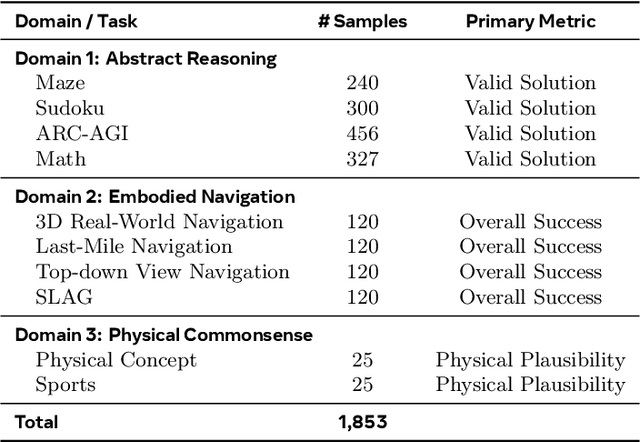
Video foundation models generate visually realistic and temporally coherent content, but their reliability as world simulators depends on whether they capture physical, logical, and spatial constraints. Existing metrics such as Frechet Video Distance (FVD) emphasize perceptual quality and overlook reasoning failures, including violations of causality, physics, and global consistency. We introduce MMGR (Multi-Modal Generative Reasoning Evaluation and Benchmark), a principled evaluation framework based on five reasoning abilities: Physical, Logical, 3D Spatial, 2D Spatial, and Temporal. MMGR evaluates generative reasoning across three domains: Abstract Reasoning (ARC-AGI, Sudoku), Embodied Navigation (real-world 3D navigation and localization), and Physical Commonsense (sports and compositional interactions). MMGR applies fine-grained metrics that require holistic correctness across both video and image generation. We benchmark leading video models (Veo-3, Sora-2, Wan-2.2) and image models (Nano-banana, Nano-banana Pro, GPT-4o-image, Qwen-image), revealing strong performance gaps across domains. Models show moderate success on Physical Commonsense tasks but perform poorly on Abstract Reasoning (below 10 percent accuracy on ARC-AGI) and struggle with long-horizon spatial planning in embodied settings. Our analysis highlights key limitations in current models, including overreliance on perceptual data, weak global state consistency, and objectives that reward visual plausibility over causal correctness. MMGR offers a unified diagnostic benchmark and a path toward reasoning-aware generative world models.
Referring Expressions as a Lens into Spatial Language Grounding in Vision-Language Models
Nov 08, 2025Spatial Reasoning is an important component of human cognition and is an area in which the latest Vision-language models (VLMs) show signs of difficulty. The current analysis works use image captioning tasks and visual question answering. In this work, we propose using the Referring Expression Comprehension task instead as a platform for the evaluation of spatial reasoning by VLMs. This platform provides the opportunity for a deeper analysis of spatial comprehension and grounding abilities when there is 1) ambiguity in object detection, 2) complex spatial expressions with a longer sentence structure and multiple spatial relations, and 3) expressions with negation ('not'). In our analysis, we use task-specific architectures as well as large VLMs and highlight their strengths and weaknesses in dealing with these specific situations. While all these models face challenges with the task at hand, the relative behaviors depend on the underlying models and the specific categories of spatial semantics (topological, directional, proximal, etc.). Our results highlight these challenges and behaviors and provide insight into research gaps and future directions.
Neuro-Symbolic Frameworks: Conceptual Characterization and Empirical Comparative Analysis
Sep 08, 2025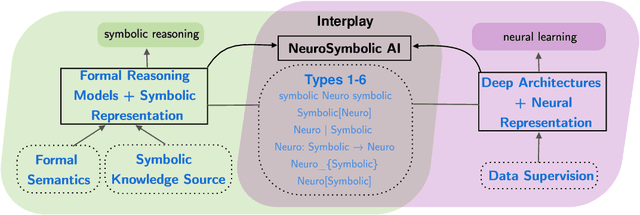
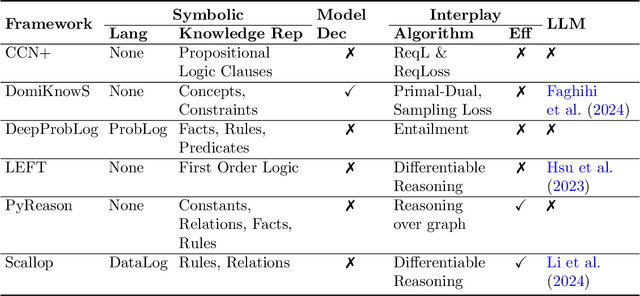

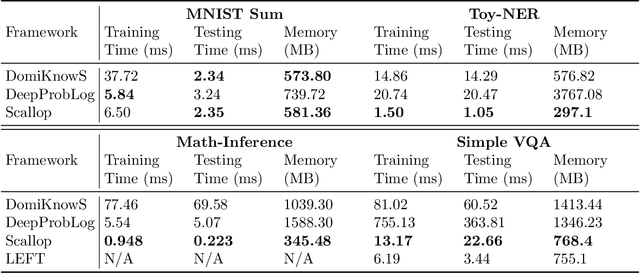
Neurosymbolic (NeSy) frameworks combine neural representations and learning with symbolic representations and reasoning. Combining the reasoning capacities, explainability, and interpretability of symbolic processing with the flexibility and power of neural computing allows us to solve complex problems with more reliability while being data-efficient. However, this recently growing topic poses a challenge to developers with its learning curve, lack of user-friendly tools, libraries, and unifying frameworks. In this paper, we characterize the technical facets of existing NeSy frameworks, such as the symbolic representation language, integration with neural models, and the underlying algorithms. A majority of the NeSy research focuses on algorithms instead of providing generic frameworks for declarative problem specification to leverage problem solving. To highlight the key aspects of Neurosymbolic modeling, we showcase three generic NeSy frameworks - \textit{DeepProbLog}, \textit{Scallop}, and \textit{DomiKnowS}. We identify the challenges within each facet that lay the foundation for identifying the expressivity of each framework in solving a variety of problems. Building on this foundation, we aim to spark transformative action and encourage the community to rethink this problem in novel ways.
Breaking Down and Building Up: Mixture of Skill-Based Vision-and-Language Navigation Agents
Aug 11, 2025Vision-and-Language Navigation (VLN) poses significant challenges in enabling agents to interpret natural language instructions and navigate complex 3D environments. While recent progress has been driven by large-scale pre-training and data augmentation, current methods still struggle to generalize to unseen scenarios, particularly when complex spatial and temporal reasoning is required. In this work, we propose SkillNav, a modular framework that introduces structured, skill-based reasoning into Transformer-based VLN agents. Our method decomposes navigation into a set of interpretable atomic skills (e.g., Vertical Movement, Area and Region Identification, Stop and Pause), each handled by a specialized agent. We then introduce a novel zero-shot Vision-Language Model (VLM)-based router, which dynamically selects the most suitable agent at each time step by aligning sub-goals with visual observations and historical actions. SkillNav achieves a new state-of-the-art performance on the R2R benchmark and demonstrates strong generalization to the GSA-R2R benchmark that includes novel instruction styles and unseen environments.
Extracting Probabilistic Knowledge from Large Language Models for Bayesian Network Parameterization
May 21, 2025Large Language Models (LLMs) have demonstrated potential as factual knowledge bases; however, their capability to generate probabilistic knowledge about real-world events remains understudied. This paper investigates using probabilistic knowledge inherent in LLMs to derive probability estimates for statements concerning events and their interrelationships captured via a Bayesian Network (BN). Using LLMs in this context allows for the parameterization of BNs, enabling probabilistic modeling within specific domains. Experiments on eighty publicly available Bayesian Networks, from healthcare to finance, demonstrate that querying LLMs about the conditional probabilities of events provides meaningful results when compared to baselines, including random and uniform distributions, as well as approaches based on next-token generation probabilities. We explore how these LLM-derived distributions can serve as expert priors to refine distributions extracted from minimal data, significantly reducing systematic biases. Overall, this work introduces a promising strategy for automatically constructing Bayesian Networks by combining probabilistic knowledge extracted from LLMs with small amounts of real-world data. Additionally, we evaluate several prompting strategies for eliciting probabilistic knowledge from LLMs and establish the first comprehensive baseline for assessing LLM performance in extracting probabilistic knowledge.
FoREST: Frame of Reference Evaluation in Spatial Reasoning Tasks
Feb 25, 2025Spatial reasoning is a fundamental aspect of human intelligence. One key concept in spatial cognition is the Frame of Reference (FoR), which identifies the perspective of spatial expressions. Despite its significance, FoR has received limited attention in AI models that need spatial intelligence. There is a lack of dedicated benchmarks and in-depth evaluation of large language models (LLMs) in this area. To address this issue, we introduce the Frame of Reference Evaluation in Spatial Reasoning Tasks (FoREST) benchmark, designed to assess FoR comprehension in LLMs. We evaluate LLMs on answering questions that require FoR comprehension and layout generation in text-to-image models using FoREST. Our results reveal a notable performance gap across different FoR classes in various LLMs, affecting their ability to generate accurate layouts for text-to-image generation. This highlights critical shortcomings in FoR comprehension. To improve FoR understanding, we propose Spatial-Guided prompting, which improves LLMs ability to extract essential spatial concepts. Our proposed method improves overall performance across spatial reasoning tasks.
Exploring Spatial Language Grounding Through Referring Expressions
Feb 04, 2025Spatial Reasoning is an important component of human cognition and is an area in which the latest Vision-language models (VLMs) show signs of difficulty. The current analysis works use image captioning tasks and visual question answering. In this work, we propose using the Referring Expression Comprehension task instead as a platform for the evaluation of spatial reasoning by VLMs. This platform provides the opportunity for a deeper analysis of spatial comprehension and grounding abilities when there is 1) ambiguity in object detection, 2) complex spatial expressions with a longer sentence structure and multiple spatial relations, and 3) expressions with negation ('not'). In our analysis, we use task-specific architectures as well as large VLMs and highlight their strengths and weaknesses in dealing with these specific situations. While all these models face challenges with the task at hand, the relative behaviors depend on the underlying models and the specific categories of spatial semantics (topological, directional, proximal, etc.). Our results highlight these challenges and behaviors and provide insight into research gaps and future directions.
NeSyCoCo: A Neuro-Symbolic Concept Composer for Compositional Generalization
Dec 20, 2024



Compositional generalization is crucial for artificial intelligence agents to solve complex vision-language reasoning tasks. Neuro-symbolic approaches have demonstrated promise in capturing compositional structures, but they face critical challenges: (a) reliance on predefined predicates for symbolic representations that limit adaptability, (b) difficulty in extracting predicates from raw data, and (c) using non-differentiable operations for combining primitive concepts. To address these issues, we propose NeSyCoCo, a neuro-symbolic framework that leverages large language models (LLMs) to generate symbolic representations and map them to differentiable neural computations. NeSyCoCo introduces three innovations: (a) augmenting natural language inputs with dependency structures to enhance the alignment with symbolic representations, (b) employing distributed word representations to link diverse, linguistically motivated logical predicates to neural modules, and (c) using the soft composition of normalized predicate scores to align symbolic and differentiable reasoning. Our framework achieves state-of-the-art results on the ReaSCAN and CLEVR-CoGenT compositional generalization benchmarks and demonstrates robust performance with novel concepts in the CLEVR-SYN benchmark.