 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Agentic Framework for Neuro-Symbolic Programming
Jan 02, 2026Integrating symbolic constraints into deep learning models could make them more robust, interpretable, and data-efficient. Still, it remains a time-consuming and challenging task. Existing frameworks like DomiKnowS help this integration by providing a high-level declarative programming interface, but they still assume the user is proficient with the library's specific syntax. We propose AgenticDomiKnowS (ADS) to eliminate this dependency. ADS translates free-form task descriptions into a complete DomiKnowS program using an agentic workflow that creates and tests each DomiKnowS component separately. The workflow supports optional human-in-the-loop intervention, enabling users familiar with DomiKnowS to refine intermediate outputs. We show how ADS enables experienced DomiKnowS users and non-users to rapidly construct neuro-symbolic programs, reducing development time from hours to 10-15 minutes.
Neuro-Symbolic Frameworks: Conceptual Characterization and Empirical Comparative Analysis
Sep 08, 2025Neurosymbolic (NeSy) frameworks combine neural representations and learning with symbolic representations and reasoning. Combining the reasoning capacities, explainability, and interpretability of symbolic processing with the flexibility and power of neural computing allows us to solve complex problems with more reliability while being data-efficient. However, this recently growing topic poses a challenge to developers with its learning curve, lack of user-friendly tools, libraries, and unifying frameworks. In this paper, we characterize the technical facets of existing NeSy frameworks, such as the symbolic representation language, integration with neural models, and the underlying algorithms. A majority of the NeSy research focuses on algorithms instead of providing generic frameworks for declarative problem specification to leverage problem solving. To highlight the key aspects of Neurosymbolic modeling, we showcase three generic NeSy frameworks - \textit{DeepProbLog}, \textit{Scallop}, and \textit{DomiKnowS}. We identify the challenges within each facet that lay the foundation for identifying the expressivity of each framework in solving a variety of problems. Building on this foundation, we aim to spark transformative action and encourage the community to rethink this problem in novel ways.
NeSyCoCo: A Neuro-Symbolic Concept Composer for Compositional Generalization
Dec 20, 2024



Compositional generalization is crucial for artificial intelligence agents to solve complex vision-language reasoning tasks. Neuro-symbolic approaches have demonstrated promise in capturing compositional structures, but they face critical challenges: (a) reliance on predefined predicates for symbolic representations that limit adaptability, (b) difficulty in extracting predicates from raw data, and (c) using non-differentiable operations for combining primitive concepts. To address these issues, we propose NeSyCoCo, a neuro-symbolic framework that leverages large language models (LLMs) to generate symbolic representations and map them to differentiable neural computations. NeSyCoCo introduces three innovations: (a) augmenting natural language inputs with dependency structures to enhance the alignment with symbolic representations, (b) employing distributed word representations to link diverse, linguistically motivated logical predicates to neural modules, and (c) using the soft composition of normalized predicate scores to align symbolic and differentiable reasoning. Our framework achieves state-of-the-art results on the ReaSCAN and CLEVR-CoGenT compositional generalization benchmarks and demonstrates robust performance with novel concepts in the CLEVR-SYN benchmark.
Syntax-Guided Transformers: Elevating Compositional Generalization and Grounding in Multimodal Environments
Nov 07, 2023Compositional generalization, the ability of intelligent models to extrapolate understanding of components to novel compositions, is a fundamental yet challenging facet in AI research, especially within multimodal environments. In this work, we address this challenge by exploiting the syntactic structure of language to boost compositional generalization. This paper elevates the importance of syntactic grounding, particularly through attention masking techniques derived from text input parsing. We introduce and evaluate the merits of using syntactic information in the multimodal grounding problem. Our results on grounded compositional generalization underscore the positive impact of dependency parsing across diverse tasks when utilized with Weight Sharing across the Transformer encoder. The results push the state-of-the-art in multimodal grounding and parameter-efficient modeling and provide insights for future research.
Evaluating Persian Tokenizers
Feb 22, 2022
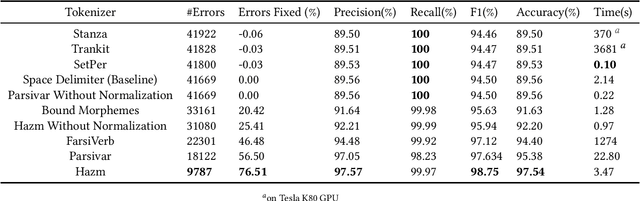
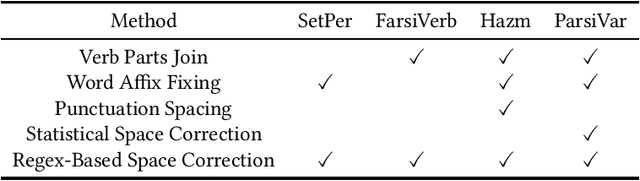
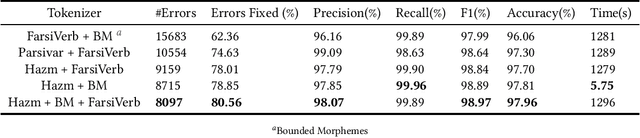
Tokenization plays a significant role in the process of lexical analysis. Tokens become the input for other natural language processing tasks, like semantic parsing and language modeling. Natural Language Processing in Persian is challenging due to Persian's exceptional cases, such as half-spaces. Thus, it is crucial to have a precise tokenizer for Persian. This article provides a novel work by introducing the most widely used tokenizers for Persian and comparing and evaluating their performance on Persian texts using a simple algorithm with a pre-tagged Persian dependency dataset. After evaluating tokenizers with the F1-Score, the hybrid version of the Farsi Verb and Hazm with bounded morphemes fixing showed the best performance with an F1 score of 98.97%.