 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBactrainus: Optimizing Large Language Models for Multi-hop Complex Question Answering Tasks
Jan 10, 2025



In recent years, the use of large language models (LLMs) has significantly increased, and these models have demonstrated remarkable performance in a variety of general language tasks. However, the evaluation of their performance in domain-specific tasks, particularly those requiring deep natural language understanding, has received less attention. In this research, we evaluate the ability of large language models in performing domain-specific tasks, focusing on the multi-hop question answering (MHQA) problem using the HotpotQA dataset. This task, due to its requirement for reasoning and combining information from multiple textual sources, serves as a challenging benchmark for assessing the language comprehension capabilities of these models. To tackle this problem, we have designed a two-stage selector-reader architecture, where each stage utilizes an independent LLM. In addition, methods such as Chain of Thought (CoT) and question decomposition have been employed to investigate their impact on improving the model's performance. The results of the study show that the integration of large language models with these techniques can lead to up to a 4% improvement in F1 score for finding answers, providing evidence of the models' ability to handle domain-specific tasks and their understanding of complex language.
Emulating the Human Mind: A Neural-symbolic Link Prediction Model with Fast and Slow Reasoning and Filtered Rules
Oct 21, 2023Link prediction is an important task in addressing the incompleteness problem of knowledge graphs (KG). Previous link prediction models suffer from issues related to either performance or explanatory capability. Furthermore, models that are capable of generating explanations, often struggle with erroneous paths or reasoning leading to the correct answer. To address these challenges, we introduce a novel Neural-Symbolic model named FaSt-FLiP (stands for Fast and Slow Thinking with Filtered rules for Link Prediction task), inspired by two distinct aspects of human cognition: "commonsense reasoning" and "thinking, fast and slow." Our objective is to combine a logical and neural model for enhanced link prediction. To tackle the challenge of dealing with incorrect paths or rules generated by the logical model, we propose a semi-supervised method to convert rules into sentences. These sentences are then subjected to assessment and removal of incorrect rules using an NLI (Natural Language Inference) model. Our approach to combining logical and neural models involves first obtaining answers from both the logical and neural models. These answers are subsequently unified using an Inference Engine module, which has been realized through both algorithmic implementation and a novel neural model architecture. To validate the efficacy of our model, we conducted a series of experiments. The results demonstrate the superior performance of our model in both link prediction metrics and the generation of more reliable explanations.
Farspredict: A benchmark dataset for link prediction
Mar 26, 2023



Link prediction with knowledge graph embedding (KGE) is a popular method for knowledge graph completion. Furthermore, training KGEs on non-English knowledge graph promote knowledge extraction and knowledge graph reasoning in the context of these languages. However, many challenges in non-English KGEs pose to learning a low-dimensional representation of a knowledge graph's entities and relations. This paper proposes "Farspredict" a Persian knowledge graph based on Farsbase (the most comprehensive knowledge graph in Persian). It also explains how the knowledge graph structure affects link prediction accuracy in KGE. To evaluate Farspredict, we implemented the popular models of KGE on it and compared the results with Freebase. Given the analysis results, some optimizations on the knowledge graph are carried out to improve its functionality in the KGE. As a result, a new Persian knowledge graph is achieved. Implementation results in the KGE models on Farspredict outperforming Freebases in many cases. At last, we discuss what improvements could be effective in enhancing the quality of Farspredict and how much it improves.
Evaluating Persian Tokenizers
Feb 22, 2022
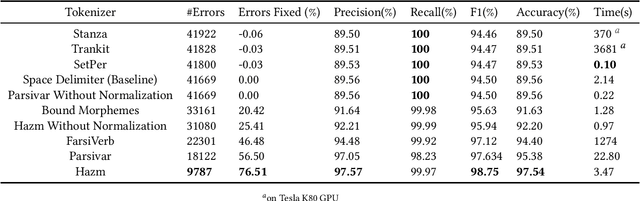
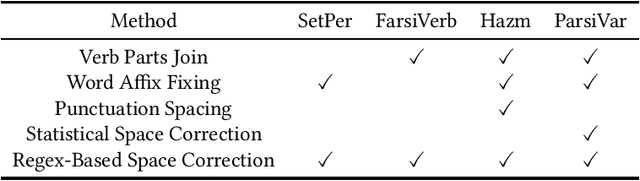
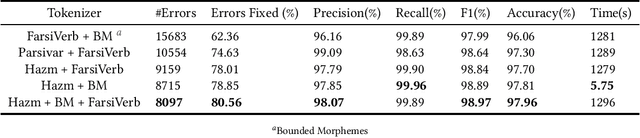
Tokenization plays a significant role in the process of lexical analysis. Tokens become the input for other natural language processing tasks, like semantic parsing and language modeling. Natural Language Processing in Persian is challenging due to Persian's exceptional cases, such as half-spaces. Thus, it is crucial to have a precise tokenizer for Persian. This article provides a novel work by introducing the most widely used tokenizers for Persian and comparing and evaluating their performance on Persian texts using a simple algorithm with a pre-tagged Persian dependency dataset. After evaluating tokenizers with the F1-Score, the hybrid version of the Farsi Verb and Hazm with bounded morphemes fixing showed the best performance with an F1 score of 98.97%.
KGRefiner: Knowledge Graph Refinement for Improving Accuracy of Translational Link Prediction Methods
Jun 27, 2021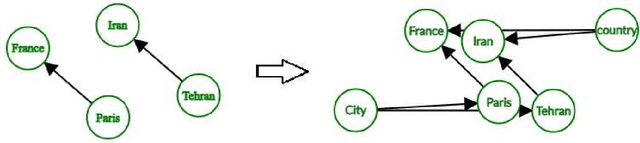
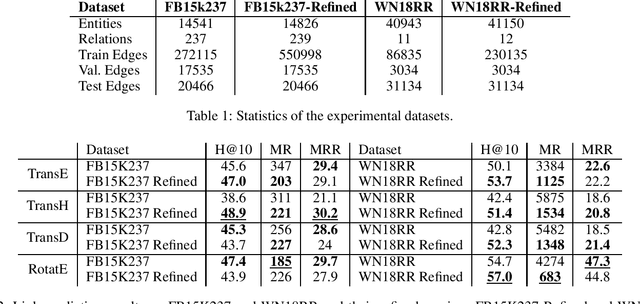
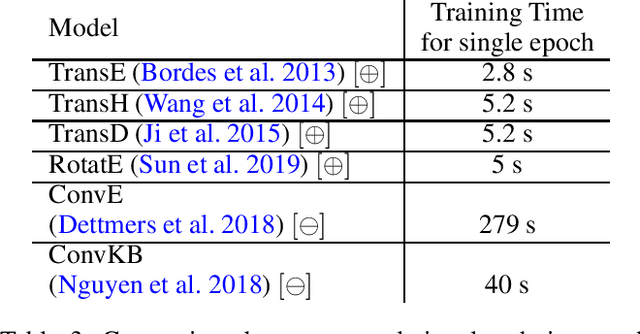
Link prediction is the task of predicting missing relations between entities of the knowledge graph by inferring from the facts contained in it. Recent work in link prediction has attempted to provide a model for increasing link prediction accuracy by using more layers in neural network architecture or methods that add to the computational complexity of models. This paper we proposed a method for refining the knowledge graph, which makes the knowledge graph more informative, and link prediction operations can be performed more accurately using relatively fast translational models. Translational link prediction models, such as TransE, TransH, TransD, etc., have much less complexity than deep learning approaches. This method uses the hierarchy of relationships and also the hierarchy of entities in the knowledge graph to add the entity information as a new entity to the graph and connect it to the nodes which contain this information in their hierarchy. Our experiments show that our method can significantly increase the performance of translational link prediction methods in H@10, MR, MRR.
A Sample-Based Training Method for Distantly Supervised Relation Extraction with Pre-Trained Transformers
Apr 15, 2021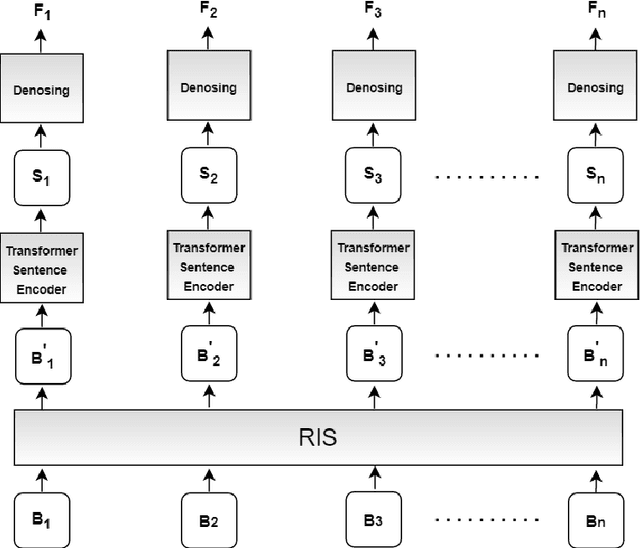
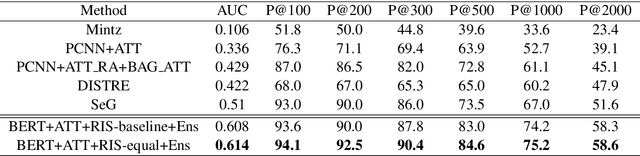

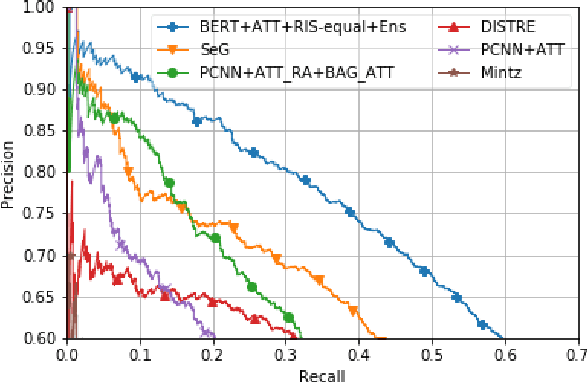
Multiple instance learning (MIL) has become the standard learning paradigm for distantly supervised relation extraction (DSRE). However, due to relation extraction being performed at bag level, MIL has significant hardware requirements for training when coupled with large sentence encoders such as deep transformer neural networks. In this paper, we propose a novel sampling method for DSRE that relaxes these hardware requirements. In the proposed method, we limit the number of sentences in a batch by randomly sampling sentences from the bags in the batch. However, this comes at the cost of losing valid sentences from bags. To alleviate the issues caused by random sampling, we use an ensemble of trained models for prediction. We demonstrate the effectiveness of our approach by using our proposed learning setting to fine-tuning BERT on the widely NYT dataset. Our approach significantly outperforms previous state-of-the-art methods in terms of AUC and P@N metrics.
Interval Probabilistic Fuzzy WordNet
Apr 04, 2021
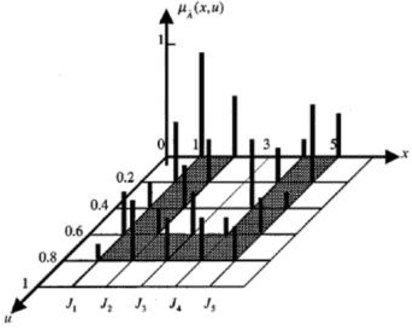
WordNet lexical-database groups English words into sets of synonyms called "synsets." Synsets are utilized for several applications in the field of text-mining. However, they were also open to criticism because although, in reality, not all the members of a synset represent the meaning of that synset with the same degree, in practice, they are considered as members of the synset, identically. Thus, the fuzzy version of synsets, called fuzzy-synsets (or fuzzy word-sense classes) were proposed and studied. In this study, we discuss why (type-1) fuzzy synsets (T1 F-synsets) do not properly model the membership uncertainty, and propose an upgraded version of fuzzy synsets in which membership degrees of word-senses are represented by intervals, similar to what in Interval Type 2 Fuzzy Sets (IT2 FS) and discuss that IT2 FS theoretical framework is insufficient for analysis and design of such synsets, and propose a new concept, called Interval Probabilistic Fuzzy (IPF) sets. Then we present an algorithm for constructing the IPF synsets in any language, given a corpus and a word-sense-disambiguation system. Utilizing our algorithm and the open-American-online-corpus (OANC) and UKB word-sense-disambiguation, we constructed and published the IPF synsets of WordNet for English language.
An Unsupervised Language-Independent Entity Disambiguation Method and its Evaluation on the English and Persian Languages
Jan 31, 2021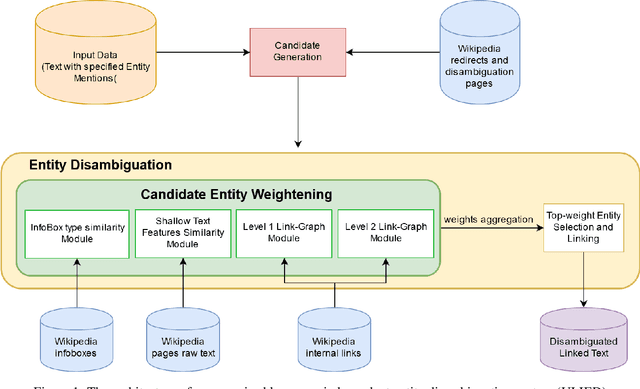
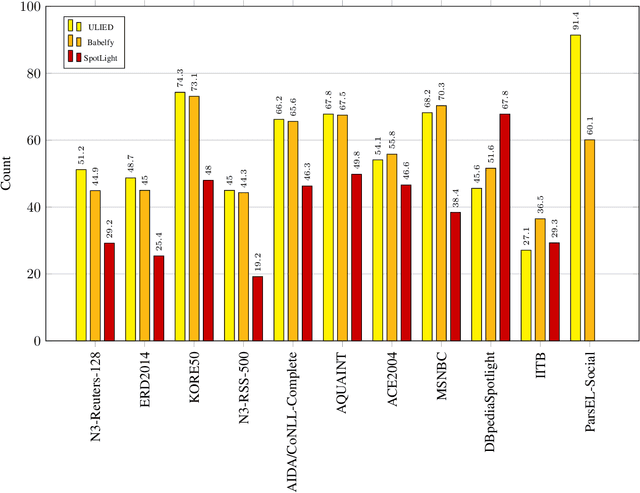
Entity Linking is one of the essential tasks of information extraction and natural language understanding. Entity linking mainly consists of two tasks: recognition and disambiguation of named entities. Most studies address these two tasks separately or focus only on one of them. Moreover, most of the state-of-the -art entity linking algorithms are either supervised, which have poor performance in the absence of annotated corpora or language-dependent, which are not appropriate for multi-lingual applications. In this paper, we introduce an Unsupervised Language-Independent Entity Disambiguation (ULIED), which utilizes a novel approach to disambiguate and link named entities. Evaluation of ULIED on different English entity linking datasets as well as the only available Persian dataset illustrates that ULIED in most of the cases outperforms the state-of-the-art unsupervised multi-lingual approaches.
IUST at SemEval-2020 Task 9: Sentiment Analysis for Code-Mixed Social Media Text using Deep Neural Networks and Linear Baselines
Jul 24, 2020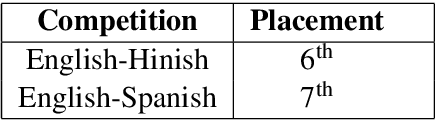
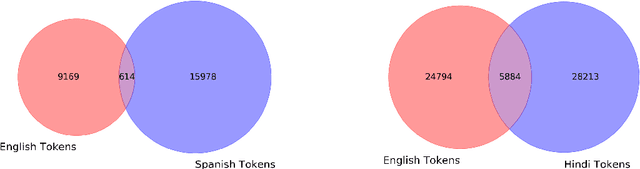

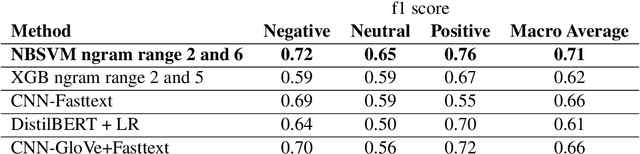
Sentiment Analysis is a well-studied field of Natural Language Processing. However, the rapid growth of social media and noisy content within them poses significant challenges in addressing this problem with well-established methods and tools. One of these challenges is code-mixing, which means using different languages to convey thoughts in social media texts. Our group, with the name of IUST(username: TAHA), participated at the SemEval-2020 shared task 9 on Sentiment Analysis for Code-Mixed Social Media Text, and we have attempted to develop a system to predict the sentiment of a given code-mixed tweet. We used different preprocessing techniques and proposed to use different methods that vary from NBSVM to more complicated deep neural network models. Our best performing method obtains an F1 score of 0.751 for the Spanish-English sub-task and 0.706 over the Hindi-English sub-task.
PERLEX: A Bilingual Persian-English Gold Dataset for Relation Extraction
May 13, 2020

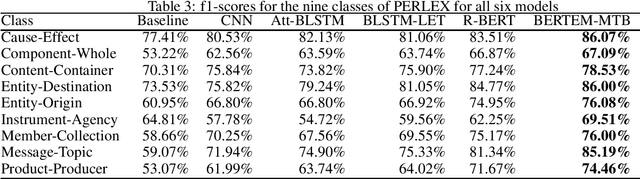
Relation extraction is the task of extracting semantic relations between entities in a sentence. It is an essential part of some natural language processing tasks such as information extraction, knowledge extraction, and knowledge base population. The main motivations of this research stem from a lack of a dataset for relation extraction in the Persian language as well as the necessity of extracting knowledge from the growing big-data in the Persian language for different applications. In this paper, we present "PERLEX" as the first Persian dataset for relation extraction, which is an expert-translated version of the "Semeval-2010-Task-8" dataset. Moreover, this paper addresses Persian relation extraction utilizing state-of-the-art language-agnostic algorithms. We employ six different models for relation extraction on the proposed bilingual dataset, including a non-neural model (as the baseline), three neural models, and two deep learning models fed by multilingual-BERT contextual word representations. The experiments result in the maximum f-score 77.66% (provided by BERTEM-MTB method) as the state-of-the-art of relation extraction in the Persian language.