 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen CQs Go Wrong: Challenges in CQ Verification with OE-Assist
Jun 23, 2026Competency Questions (CQs) are the central component of CQ-verification, an established process in which an ontology is evaluated against a set of natural language questions to determine whether the intended purpose of the ontology has been properly modelled. However, CQ-verification is often time-consuming and error-prone, as it requires careful interpretation of linguistic nuances and precise alignment with formal ontology constructs. Ambiguities and complexity in CQs can further complicate this process, leading to inconsistent modelling decisions and verification outcomes. In this paper, we investigate what makes a CQ challenging and possible solutions to enhance the users' performance in the CQ-verification process. We experimented with the data of 19 participants who performed CQ-verification on 20 tasks using an LLM assistant to support ontology evaluation. The results show the necessity of a tool to refine CQs before publishing them to avoid ambiguity or excessive complexity in later phases of the ontology engineering process.
Leveraging Large Language Models for Accurate Sign Language Translation in Low-Resource Scenarios
Aug 25, 2025
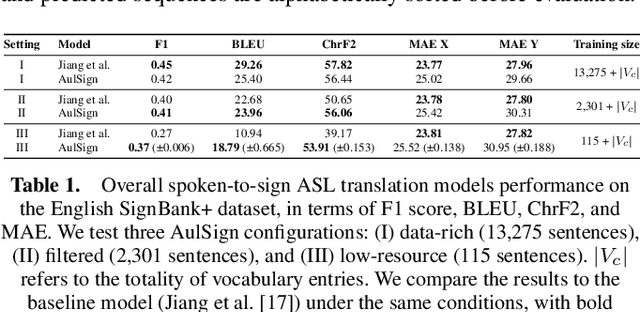
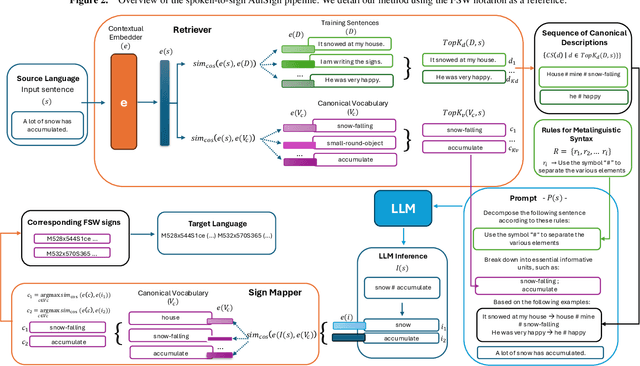
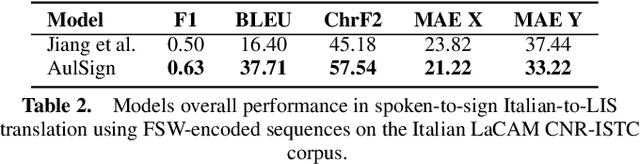
Translating natural languages into sign languages is a highly complex and underexplored task. Despite growing interest in accessibility and inclusivity, the development of robust translation systems remains hindered by the limited availability of parallel corpora which align natural language with sign language data. Existing methods often struggle to generalize in these data-scarce environments, as the few datasets available are typically domain-specific, lack standardization, or fail to capture the full linguistic richness of sign languages. To address this limitation, we propose Advanced Use of LLMs for Sign Language Translation (AulSign), a novel method that leverages Large Language Models via dynamic prompting and in-context learning with sample selection and subsequent sign association. Despite their impressive abilities in processing text, LLMs lack intrinsic knowledge of sign languages; therefore, they are unable to natively perform this kind of translation. To overcome this limitation, we associate the signs with compact descriptions in natural language and instruct the model to use them. We evaluate our method on both English and Italian languages using SignBank+, a recognized benchmark in the field, as well as the Italian LaCAM CNR-ISTC dataset. We demonstrate superior performance compared to state-of-the-art models in low-data scenario. Our findings demonstrate the effectiveness of AulSign, with the potential to enhance accessibility and inclusivity in communication technologies for underrepresented linguistic communities.
The Medical Metaphors Corpus (MCC)
Aug 11, 2025Metaphor is a fundamental cognitive mechanism that shapes scientific understanding, enabling the communication of complex concepts while potentially constraining paradigmatic thinking. Despite the prevalence of figurative language in scientific discourse, existing metaphor detection resources primarily focus on general-domain text, leaving a critical gap for domain-specific applications. In this paper, we present the Medical Metaphors Corpus (MCC), a comprehensive dataset of 792 annotated scientific conceptual metaphors spanning medical and biological domains. MCC aggregates metaphorical expressions from diverse sources including peer-reviewed literature, news media, social media discourse, and crowdsourced contributions, providing both binary and graded metaphoricity judgments validated through human annotation. Each instance includes source-target conceptual mappings and perceived metaphoricity scores on a 0-7 scale, establishing the first annotated resource for computational scientific metaphor research. Our evaluation demonstrates that state-of-the-art language models achieve modest performance on scientific metaphor detection, revealing substantial room for improvement in domain-specific figurative language understanding. MCC enables multiple research applications including metaphor detection benchmarking, quality-aware generation systems, and patient-centered communication tools.
Learning Local Causal World Models with State Space Models and Attention
May 04, 2025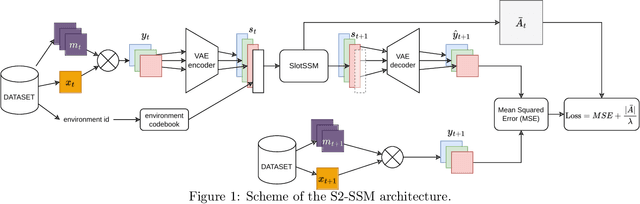



World modelling, i.e. building a representation of the rules that govern the world so as to predict its evolution, is an essential ability for any agent interacting with the physical world. Despite their impressive performance, many solutions fail to learn a causal representation of the environment they are trying to model, which would be necessary to gain a deep enough understanding of the world to perform complex tasks. With this work, we aim to broaden the research in the intersection of causality theory and neural world modelling by assessing the potential for causal discovery of the State Space Model (SSM) architecture, which has been shown to have several advantages over the widespread Transformer. We show empirically that, compared to an equivalent Transformer, a SSM can model the dynamics of a simple environment and learn a causal model at the same time with equivalent or better performance, thus paving the way for further experiments that lean into the strength of SSMs and further enhance them with causal awareness.
Assessing the Capability of Large Language Models for Domain-Specific Ontology Generation
Apr 24, 2025Large Language Models (LLMs) have shown significant potential for ontology engineering. However, it is still unclear to what extent they are applicable to the task of domain-specific ontology generation. In this study, we explore the application of LLMs for automated ontology generation and evaluate their performance across different domains. Specifically, we investigate the generalizability of two state-of-the-art LLMs, DeepSeek and o1-preview, both equipped with reasoning capabilities, by generating ontologies from a set of competency questions (CQs) and related user stories. Our experimental setup comprises six distinct domains carried out in existing ontology engineering projects and a total of 95 curated CQs designed to test the models' reasoning for ontology engineering. Our findings show that with both LLMs, the performance of the experiments is remarkably consistent across all domains, indicating that these methods are capable of generalizing ontology generation tasks irrespective of the domain. These results highlight the potential of LLM-based approaches in achieving scalable and domain-agnostic ontology construction and lay the groundwork for further research into enhancing automated reasoning and knowledge representation techniques.
Enhancing multimodal analogical reasoning with Logic Augmented Generation
Apr 15, 2025Recent advances in Large Language Models have demonstrated their capabilities across a variety of tasks. However, automatically extracting implicit knowledge from natural language remains a significant challenge, as machines lack active experience with the physical world. Given this scenario, semantic knowledge graphs can serve as conceptual spaces that guide the automated text generation reasoning process to achieve more efficient and explainable results. In this paper, we apply a logic-augmented generation (LAG) framework that leverages the explicit representation of a text through a semantic knowledge graph and applies it in combination with prompt heuristics to elicit implicit analogical connections. This method generates extended knowledge graph triples representing implicit meaning, enabling systems to reason on unlabeled multimodal data regardless of the domain. We validate our work through three metaphor detection and understanding tasks across four datasets, as they require deep analogical reasoning capabilities. The results show that this integrated approach surpasses current baselines, performs better than humans in understanding visual metaphors, and enables more explainable reasoning processes, though still has inherent limitations in metaphor understanding, especially for domain-specific metaphors. Furthermore, we propose a thorough error analysis, discussing issues with metaphorical annotations and current evaluation methods.
Ontology Generation using Large Language Models
Mar 07, 2025The ontology engineering process is complex, time-consuming, and error-prone, even for experienced ontology engineers. In this work, we investigate the potential of Large Language Models (LLMs) to provide effective OWL ontology drafts directly from ontological requirements described using user stories and competency questions. Our main contribution is the presentation and evaluation of two new prompting techniques for automated ontology development: Memoryless CQbyCQ and Ontogenia. We also emphasize the importance of three structural criteria for ontology assessment, alongside expert qualitative evaluation, highlighting the need for a multi-dimensional evaluation in order to capture the quality and usability of the generated ontologies. Our experiments, conducted on a benchmark dataset of ten ontologies with 100 distinct CQs and 29 different user stories, compare the performance of three LLMs using the two prompting techniques. The results demonstrate improvements over the current state-of-the-art in LLM-supported ontology engineering. More specifically, the model OpenAI o1-preview with Ontogenia produces ontologies of sufficient quality to meet the requirements of ontology engineers, significantly outperforming novice ontology engineers in modelling ability. However, we still note some common mistakes and variability of result quality, which is important to take into account when using LLMs for ontology authoring support. We discuss these limitations and propose directions for future research.
Logic Augmented Generation
Nov 21, 2024

Semantic Knowledge Graphs (SKG) face challenges with scalability, flexibility, contextual understanding, and handling unstructured or ambiguous information. However, they offer formal and structured knowledge enabling highly interpretable and reliable results by means of reasoning and querying. Large Language Models (LLMs) overcome those limitations making them suitable in open-ended tasks and unstructured environments. Nevertheless, LLMs are neither interpretable nor reliable. To solve the dichotomy between LLMs and SKGs we envision Logic Augmented Generation (LAG) that combines the benefits of the two worlds. LAG uses LLMs as Reactive Continuous Knowledge Graphs that can generate potentially infinite relations and tacit knowledge on-demand. SKGs are key for injecting a discrete heuristic dimension with clear logical and factual boundaries. We exemplify LAG in two tasks of collective intelligence, i.e., medical diagnostics and climate projections. Understanding the properties and limitations of LAG, which are still mostly unknown, is of utmost importance for enabling a variety of tasks involving tacit knowledge in order to provide interpretable and effective results.
Neurosymbolic Graph Enrichment for Grounded World Models
Nov 19, 2024

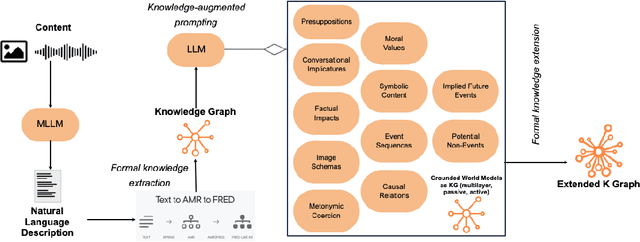
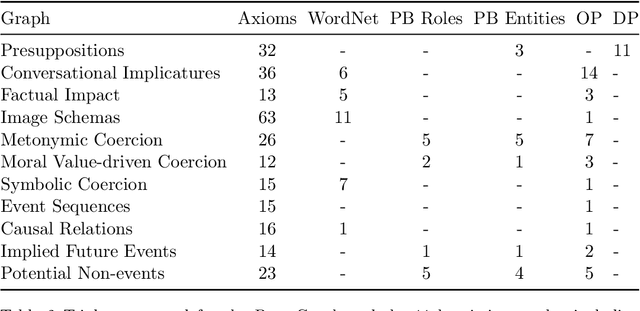
The development of artificial intelligence systems capable of understanding and reasoning about complex real-world scenarios is a significant challenge. In this work we present a novel approach to enhance and exploit LLM reactive capability to address complex problems and interpret deeply contextual real-world meaning. We introduce a method and a tool for creating a multimodal, knowledge-augmented formal representation of meaning that combines the strengths of large language models with structured semantic representations. Our method begins with an image input, utilizing state-of-the-art large language models to generate a natural language description. This description is then transformed into an Abstract Meaning Representation (AMR) graph, which is formalized and enriched with logical design patterns, and layered semantics derived from linguistic and factual knowledge bases. The resulting graph is then fed back into the LLM to be extended with implicit knowledge activated by complex heuristic learning, including semantic implicatures, moral values, embodied cognition, and metaphorical representations. By bridging the gap between unstructured language models and formal semantic structures, our method opens new avenues for tackling intricate problems in natural language understanding and reasoning.
Explainable Moral Values: a neuro-symbolic approach to value classification
Oct 16, 2024
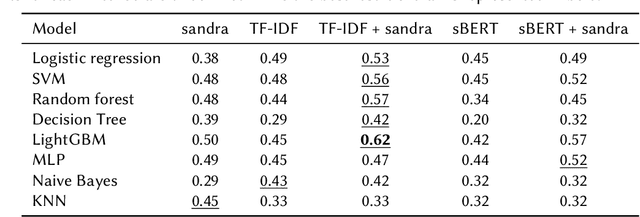
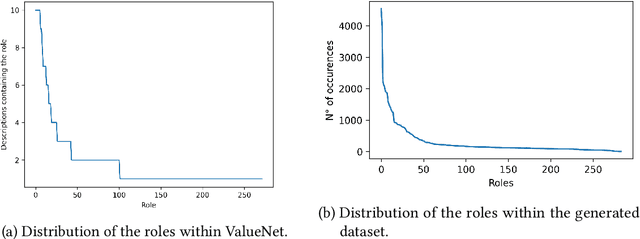
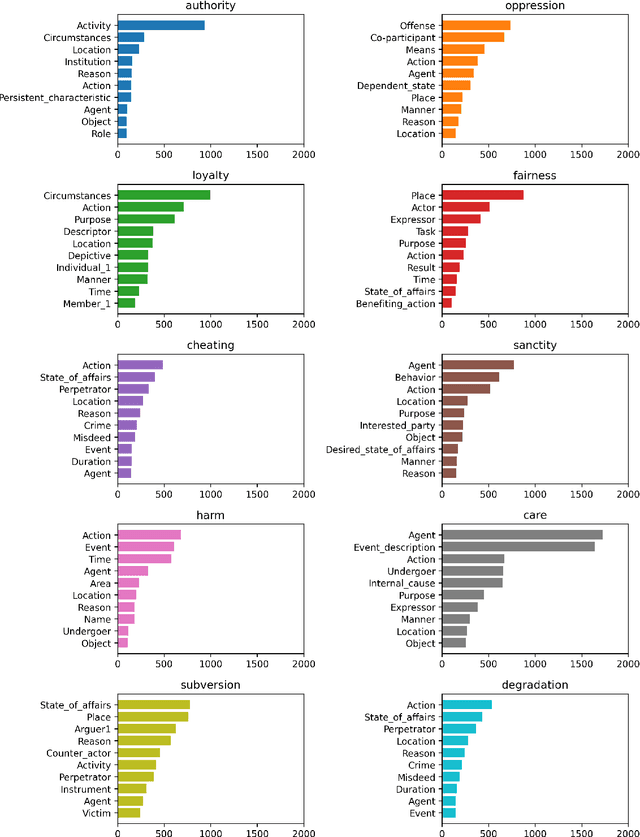
This work explores the integration of ontology-based reasoning and Machine Learning techniques for explainable value classification. By relying on an ontological formalization of moral values as in the Moral Foundations Theory, relying on the DnS Ontology Design Pattern, the \textit{sandra} neuro-symbolic reasoner is used to infer values (fomalized as descriptions) that are \emph{satisfied by} a certain sentence. Sentences, alongside their structured representation, are automatically generated using an open-source Large Language Model. The inferred descriptions are used to automatically detect the value associated with a sentence. We show that only relying on the reasoner's inference results in explainable classification comparable to other more complex approaches. We show that combining the reasoner's inferences with distributional semantics methods largely outperforms all the baselines, including complex models based on neural network architectures. Finally, we build a visualization tool to explore the potential of theory-based values classification, which is publicly available at http://xmv.geomeaning.com/.