 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Large Language Models for Accurate Sign Language Translation in Low-Resource Scenarios
Aug 25, 2025
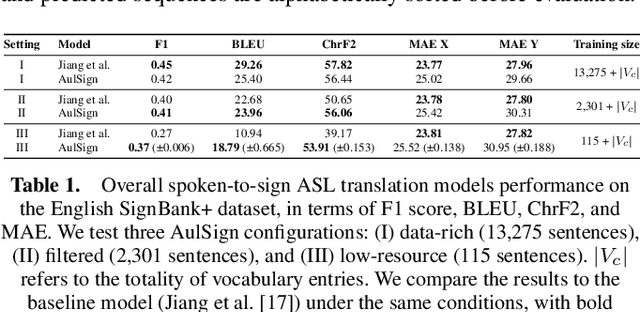
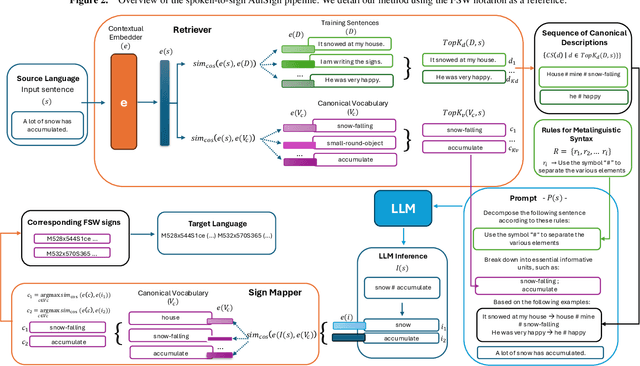
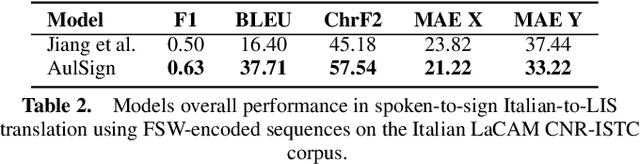
Translating natural languages into sign languages is a highly complex and underexplored task. Despite growing interest in accessibility and inclusivity, the development of robust translation systems remains hindered by the limited availability of parallel corpora which align natural language with sign language data. Existing methods often struggle to generalize in these data-scarce environments, as the few datasets available are typically domain-specific, lack standardization, or fail to capture the full linguistic richness of sign languages. To address this limitation, we propose Advanced Use of LLMs for Sign Language Translation (AulSign), a novel method that leverages Large Language Models via dynamic prompting and in-context learning with sample selection and subsequent sign association. Despite their impressive abilities in processing text, LLMs lack intrinsic knowledge of sign languages; therefore, they are unable to natively perform this kind of translation. To overcome this limitation, we associate the signs with compact descriptions in natural language and instruct the model to use them. We evaluate our method on both English and Italian languages using SignBank+, a recognized benchmark in the field, as well as the Italian LaCAM CNR-ISTC dataset. We demonstrate superior performance compared to state-of-the-art models in low-data scenario. Our findings demonstrate the effectiveness of AulSign, with the potential to enhance accessibility and inclusivity in communication technologies for underrepresented linguistic communities.
Do Language Models Understand Morality? Towards a Robust Detection of Moral Content
Jun 06, 2024The task of detecting moral values in text has significant implications in various fields, including natural language processing, social sciences, and ethical decision-making. Previously proposed supervised models often suffer from overfitting, leading to hyper-specialized moral classifiers that struggle to perform well on data from different domains. To address this issue, we introduce novel systems that leverage abstract concepts and common-sense knowledge acquired from Large Language Models and Natural Language Inference models during previous stages of training on multiple data sources. By doing so, we aim to develop versatile and robust methods for detecting moral values in real-world scenarios. Our approach uses the GPT 3.5 model as a zero-shot ready-made unsupervised multi-label classifier for moral values detection, eliminating the need for explicit training on labeled data. We compare it with a smaller NLI-based zero-shot model. The results show that the NLI approach achieves competitive results compared to the Davinci model. Furthermore, we conduct an in-depth investigation of the performance of supervised systems in the context of cross-domain multi-label moral value detection. This involves training supervised models on different domains to explore their effectiveness in handling data from different sources and comparing their performance with the unsupervised methods. Our contributions encompass a thorough analysis of both supervised and unsupervised methodologies for cross-domain value detection. We introduce the Davinci model as a state-of-the-art zero-shot unsupervised moral values classifier, pushing the boundaries of moral value detection without the need for explicit training on labeled data. Additionally, we perform a comparative evaluation of our approach with the supervised models, shedding light on their respective strengths and weaknesses.
Graph-based Retrieval for Claim Verification over Cross-Document Evidence
Sep 13, 2021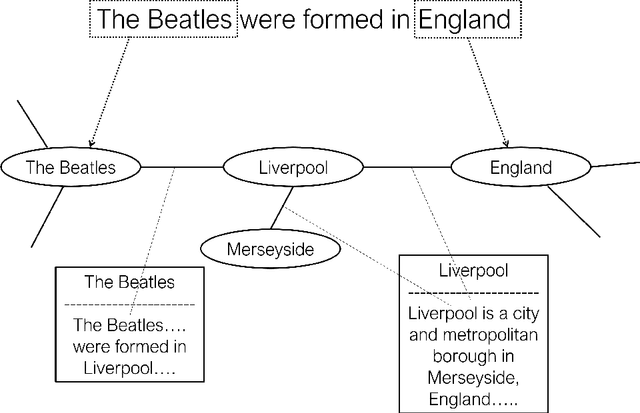
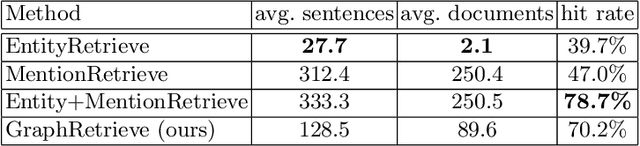
Verifying the veracity of claims requires reasoning over a large knowledge base, often in the form of corpora of trustworthy sources. A common approach consists in retrieving short portions of relevant text from the reference documents and giving them as input to a natural language inference module that determines whether the claim can be inferred or contradicted from them. This approach, however, struggles when multiple pieces of evidence need to be collected and combined from different documents, since the single documents are often barely related to the target claim and hence they are left out by the retrieval module. We conjecture that a graph-based approach can be beneficial to identify fragmented evidence. We tested this hypothesis by building, over the whole corpus, a large graph that interconnects text portions by means of mentioned entities and exploiting such a graph for identifying candidate sets of evidence from multiple sources. Our experiments show that leveraging on a graph structure is beneficial in identifying a reasonably small portion of passages related to a claim.
Pattern-based Visualization of Knowledge Graphs
Jun 24, 2021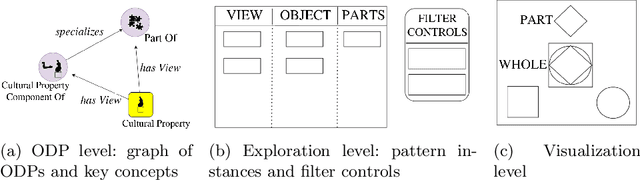
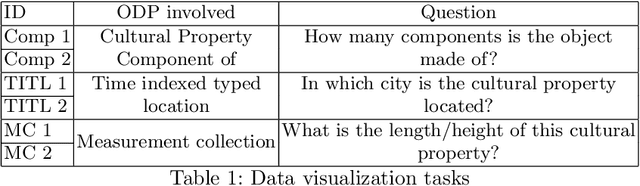
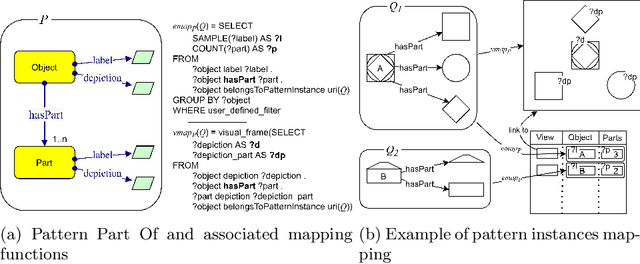

We present a novel approach to knowledge graph visualization based on ontology design patterns. This approach relies on OPLa (Ontology Pattern Language) annotations and on a catalogue of visual frames, which are associated with foundational ontology design patterns. We demonstrate that this approach significantly reduces the cognitive load required to users for visualizing and interpreting a knowledge graph and guides the user in exploring it through meaningful thematic paths provided by ontology patterns.