 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTo Neuro-Symbolic Classification and Beyond by Compiling Description Logic Ontologies to Probabilistic Circuits
Jan 21, 2026Background: Neuro-symbolic methods enhance the reliability of neural network classifiers through logical constraints, but they lack native support for ontologies. Objectives: We aim to develop a neuro-symbolic method that reliably outputs predictions consistent with a Description Logic ontology that formalizes domain-specific knowledge. Methods: We encode a Description Logic ontology as a circuit, a feed-forward differentiable computational graph that supports tractable execution of queries and transformations. We show that the circuit can be used to (i) generate synthetic datasets that capture the semantics of the ontology; (ii) efficiently perform deductive reasoning on a GPU; (iii) implement neuro-symbolic models whose predictions are approximately or provably consistent with the knowledge defined in the ontology. Results We show that the synthetic dataset generated using the circuit qualitatively captures the semantics of the ontology while being challenging for Machine Learning classifiers, including neural networks. Moreover, we show that compiling the ontology into a circuit is a promising approach for scalable deductive reasoning, with runtimes up to three orders of magnitude faster than available reasoners. Finally, we show that our neuro-symbolic classifiers reliably produce consistent predictions when compared to neural network baselines, maintaining competitive performances or even outperforming them. Conclusions By compiling Description Logic ontologies into circuits, we obtain a tighter integration between the Deep Learning and Knowledge Representation fields. We show that a single circuit representation can be used to tackle different challenging tasks closely related to real-world applications.
Bench4KE: Benchmarking Automated Competency Question Generation
May 30, 2025The availability of Large Language Models (LLMs) presents a unique opportunity to reinvigorate research on Knowledge Engineering (KE) automation, a trend already evident in recent efforts developing LLM-based methods and tools for the automatic generation of Competency Questions (CQs). However, the evaluation of these tools lacks standardisation. This undermines the methodological rigour and hinders the replication and comparison of results. To address this gap, we introduce Bench4KE, an extensible API-based benchmarking system for KE automation. Its first release focuses on evaluating tools that generate CQs automatically. CQs are natural language questions used by ontology engineers to define the functional requirements of an ontology. Bench4KE provides a curated gold standard consisting of CQ datasets from four real-world ontology projects. It uses a suite of similarity metrics to assess the quality of the CQs generated. We present a comparative analysis of four recent CQ generation systems, which are based on LLMs, establishing a baseline for future research. Bench4KE is also designed to accommodate additional KE automation tasks, such as SPARQL query generation, ontology testing and drafting. Code and datasets are publicly available under the Apache 2.0 license.
Musical Heritage Historical Entity Linking
Feb 13, 2025Linking named entities occurring in text to their corresponding entity in a Knowledge Base (KB) is challenging, especially when dealing with historical texts. In this work, we introduce Musical Heritage named Entities Recognition, Classification and Linking (MHERCL), a novel benchmark consisting of manually annotated sentences extrapolated from historical periodicals of the music domain. MHERCL contains named entities under-represented or absent in the most famous KBs. We experiment with several State-of-the-Art models on the Entity Linking (EL) task and show that MHERCL is a challenging dataset for all of them. We propose a novel unsupervised EL model and a method to extend supervised entity linkers by using Knowledge Graphs (KGs) to tackle the main difficulties posed by historical documents. Our experiments reveal that relying on unsupervised techniques and improving models with logical constraints based on KGs and heuristics to predict NIL entities (entities not represented in the KB of reference) results in better EL performance on historical documents.
Semantic Web and Creative AI -- A Technical Report from ISWS 2023
Jan 30, 2025



The International Semantic Web Research School (ISWS) is a week-long intensive program designed to immerse participants in the field. This document reports a collaborative effort performed by ten teams of students, each guided by a senior researcher as their mentor, attending ISWS 2023. Each team provided a different perspective to the topic of creative AI, substantiated by a set of research questions as the main subject of their investigation. The 2023 edition of ISWS focuses on the intersection of Semantic Web technologies and Creative AI. ISWS 2023 explored various intersections between Semantic Web technologies and creative AI. A key area of focus was the potential of LLMs as support tools for knowledge engineering. Participants also delved into the multifaceted applications of LLMs, including legal aspects of creative content production, humans in the loop, decentralised approaches to multimodal generative AI models, nanopublications and AI for personal scientific knowledge graphs, commonsense knowledge in automatic story and narrative completion, generative AI for art critique, prompt engineering, automatic music composition, commonsense prototyping and conceptual blending, and elicitation of tacit knowledge. As Large Language Models and semantic technologies continue to evolve, new exciting prospects are emerging: a future where the boundaries between creative expression and factual knowledge become increasingly permeable and porous, leading to a world of knowledge that is both informative and inspiring.
Explainable Moral Values: a neuro-symbolic approach to value classification
Oct 16, 2024
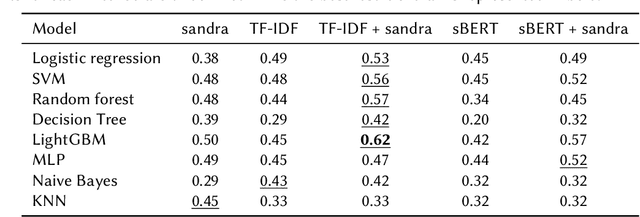
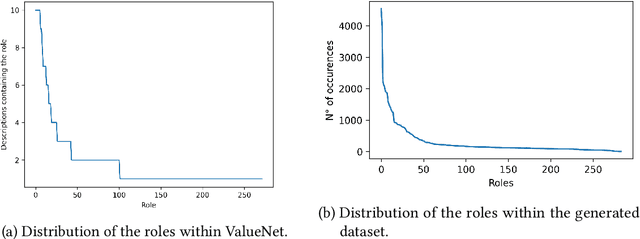
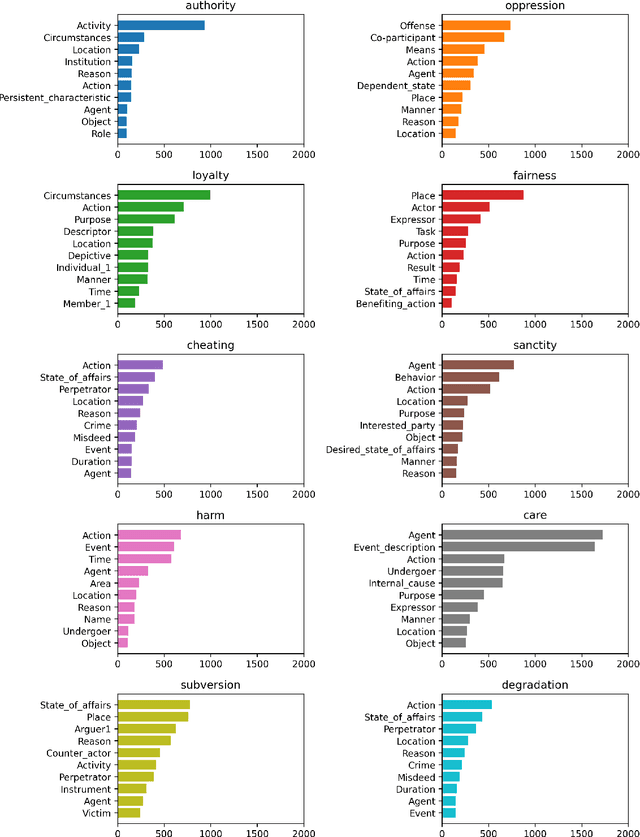
This work explores the integration of ontology-based reasoning and Machine Learning techniques for explainable value classification. By relying on an ontological formalization of moral values as in the Moral Foundations Theory, relying on the DnS Ontology Design Pattern, the \textit{sandra} neuro-symbolic reasoner is used to infer values (fomalized as descriptions) that are \emph{satisfied by} a certain sentence. Sentences, alongside their structured representation, are automatically generated using an open-source Large Language Model. The inferred descriptions are used to automatically detect the value associated with a sentence. We show that only relying on the reasoner's inference results in explainable classification comparable to other more complex approaches. We show that combining the reasoner's inferences with distributional semantics methods largely outperforms all the baselines, including complex models based on neural network architectures. Finally, we build a visualization tool to explore the potential of theory-based values classification, which is publicly available at http://xmv.geomeaning.com/.
ChordSync: Conformer-Based Alignment of Chord Annotations to Music Audio
Aug 01, 2024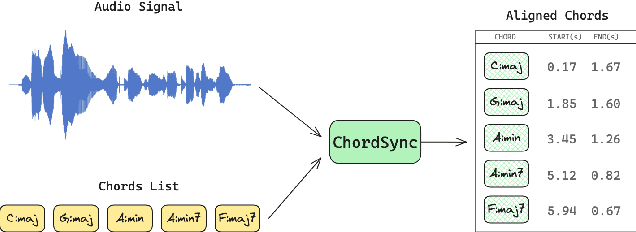
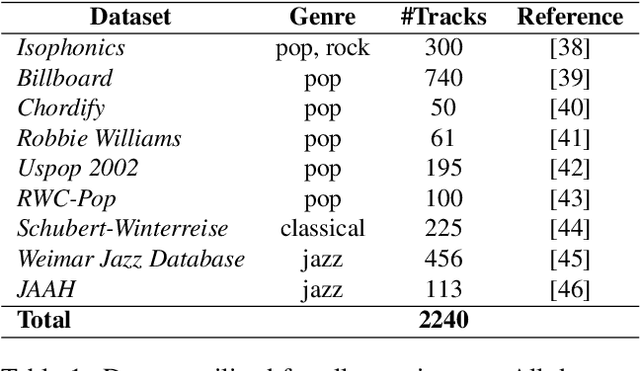
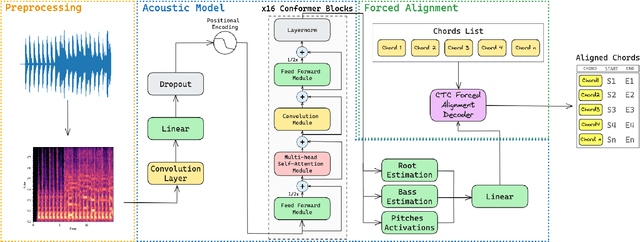
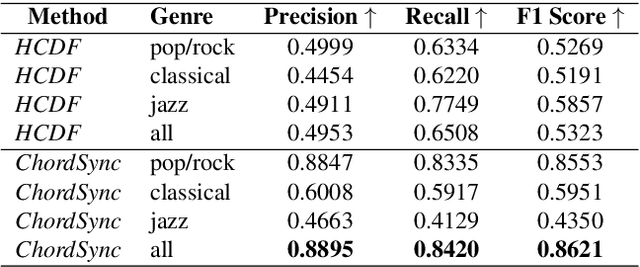
In the Western music tradition, chords are the main constituent components of harmony, a fundamental dimension of music. Despite its relevance for several Music Information Retrieval (MIR) tasks, chord-annotated audio datasets are limited and need more diversity. One way to improve those resources is to leverage the large number of chord annotations available online, but this requires aligning them with music audio. However, existing audio-to-score alignment techniques, which typically rely on Dynamic Time Warping (DTW), fail to address this challenge, as they require weakly aligned data for precise synchronisation. In this paper, we introduce ChordSync, a novel conformer-based model designed to seamlessly align chord annotations with audio, eliminating the need for weak alignment. We also provide a pre-trained model and a user-friendly library, enabling users to synchronise chord annotations with audio tracks effortlessly. In this way, ChordSync creates opportunities for harnessing crowd-sourced chord data for MIR, especially in audio chord estimation, thereby facilitating the generation of novel datasets. Additionally, our system extends its utility to music education, enhancing music learning experiences by providing accurately aligned annotations, thus enabling learners to engage in synchronised musical practices.
* 8 pages, 3 figures, 3 tables
Situated Ground Truths: Enhancing Bias-Aware AI by Situating Data Labels with SituAnnotate
Jun 10, 2024In the contemporary world of AI and data-driven applications, supervised machines often derive their understanding, which they mimic and reproduce, through annotations--typically conveyed in the form of words or labels. However, such annotations are often divorced from or lack contextual information, and as such hold the potential to inadvertently introduce biases when subsequently used for training. This paper introduces SituAnnotate, a novel ontology explicitly crafted for 'situated grounding,' aiming to anchor the ground truth data employed in training AI systems within the contextual and culturally-bound situations from which those ground truths emerge. SituAnnotate offers an ontology-based approach to structured and context-aware data annotation, addressing potential bias issues associated with isolated annotations. Its representational power encompasses situational context, including annotator details, timing, location, remuneration schemes, annotation roles, and more, ensuring semantic richness. Aligned with the foundational Dolce Ultralight ontology, it provides a robust and consistent framework for knowledge representation. As a method to create, query, and compare label-based datasets, SituAnnotate empowers downstream AI systems to undergo training with explicit consideration of context and cultural bias, laying the groundwork for enhanced system interpretability and adaptability, and enabling AI models to align with a multitude of cultural contexts and viewpoints.
Stitching Gaps: Fusing Situated Perceptual Knowledge with Vision Transformers for High-Level Image Classification
Feb 29, 2024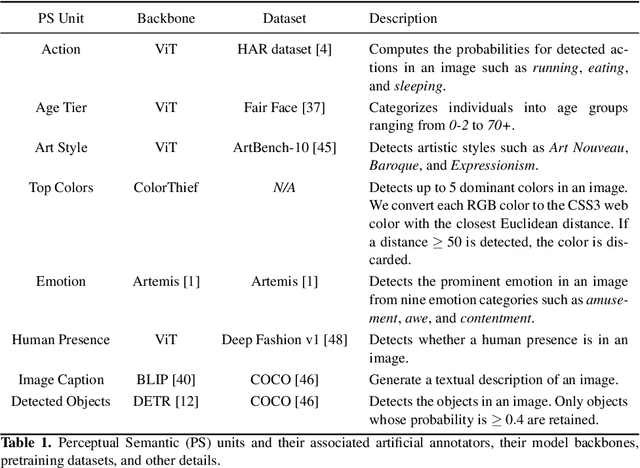
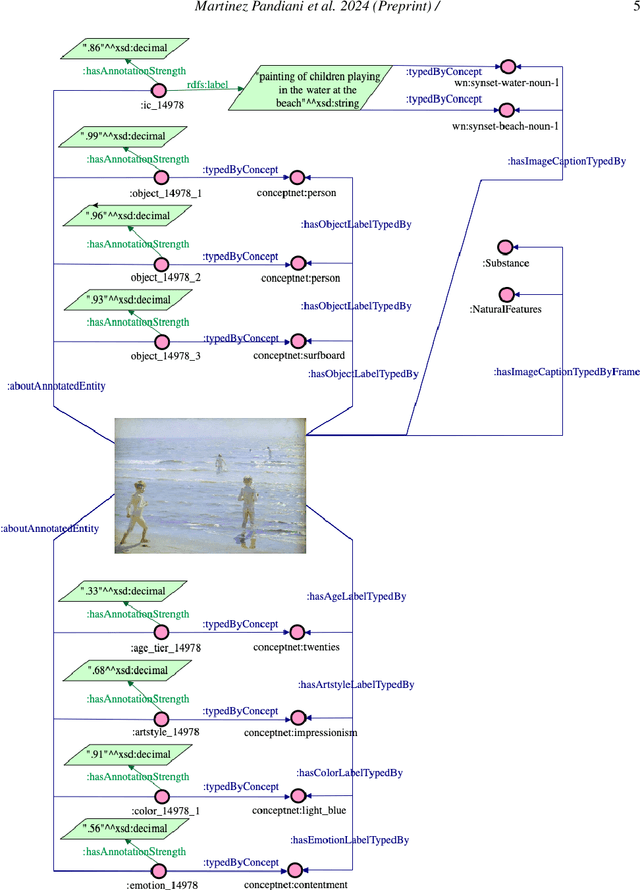
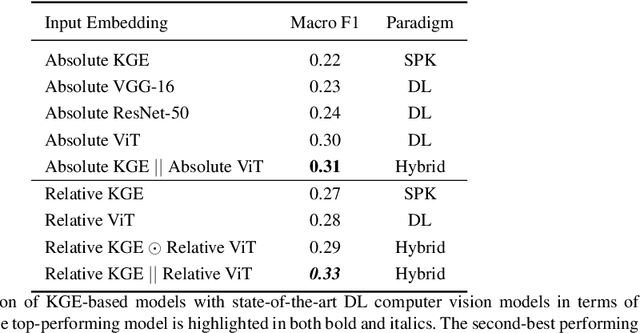
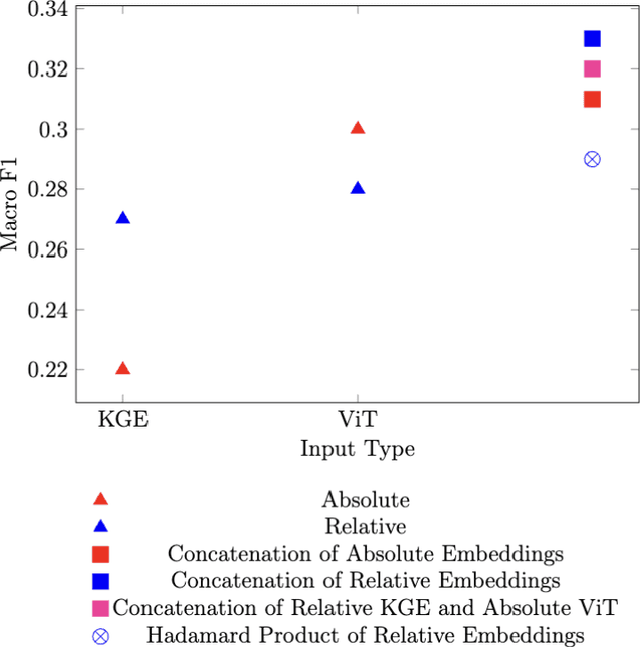
The increasing demand for automatic high-level image understanding, particularly in detecting abstract concepts (AC) within images, underscores the necessity for innovative and more interpretable approaches. These approaches need to harmonize traditional deep vision methods with the nuanced, context-dependent knowledge humans employ to interpret images at intricate semantic levels. In this work, we leverage situated perceptual knowledge of cultural images to enhance performance and interpretability in AC image classification. We automatically extract perceptual semantic units from images, which we then model and integrate into the ARTstract Knowledge Graph (AKG). This resource captures situated perceptual semantics gleaned from over 14,000 cultural images labeled with ACs. Additionally, we enhance the AKG with high-level linguistic frames. We compute KG embeddings and experiment with relative representations and hybrid approaches that fuse these embeddings with visual transformer embeddings. Finally, for interpretability, we conduct posthoc qualitative analyses by examining model similarities with training instances. Our results show that our hybrid KGE-ViT methods outperform existing techniques in AC image classification. The posthoc interpretability analyses reveal the visual transformer's proficiency in capturing pixel-level visual attributes, contrasting with our method's efficacy in representing more abstract and semantic scene elements. We demonstrate the synergy and complementarity between KGE embeddings' situated perceptual knowledge and deep visual model's sensory-perceptual understanding for AC image classification. This work suggests a strong potential of neuro-symbolic methods for knowledge integration and robust image representation for use in downstream intricate visual comprehension tasks. All the materials and code are available online.
Sandra -- A Neuro-Symbolic Reasoner Based On Descriptions And Situations
Feb 02, 2024



This paper presents sandra, a neuro-symbolic reasoner combining vectorial representations with deductive reasoning. Sandra builds a vector space constrained by an ontology and performs reasoning over it. The geometric nature of the reasoner allows its combination with neural networks, bridging the gap with symbolic knowledge representations. Sandra is based on the Description and Situation (DnS) ontology design pattern, a formalization of frame semantics. Given a set of facts (a situation) it allows to infer all possible perspectives (descriptions) that can provide a plausible interpretation for it, even in presence of incomplete information. We prove that our method is correct with respect to the DnS model. We experiment with two different tasks and their standard benchmarks, demonstrating that, without increasing complexity, sandra (i) outperforms all the baselines (ii) provides interpretability in the classification process, and (iii) allows control over the vector space, which is designed a priori.
The Music Meta Ontology: a flexible semantic model for the interoperability of music metadata
Nov 07, 2023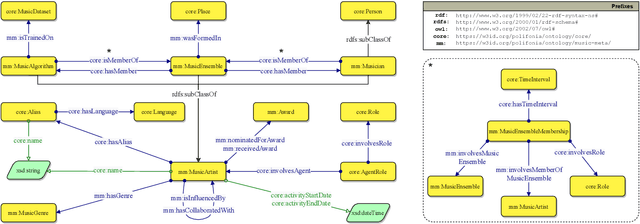
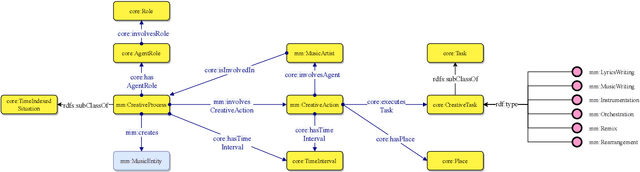
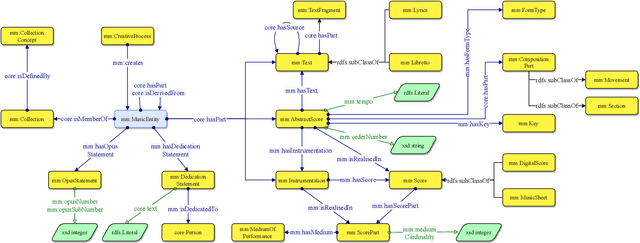

The semantic description of music metadata is a key requirement for the creation of music datasets that can be aligned, integrated, and accessed for information retrieval and knowledge discovery. It is nonetheless an open challenge due to the complexity of musical concepts arising from different genres, styles, and periods -- standing to benefit from a lingua franca to accommodate various stakeholders (musicologists, librarians, data engineers, etc.). To initiate this transition, we introduce the Music Meta ontology, a rich and flexible semantic model to describe music metadata related to artists, compositions, performances, recordings, and links. We follow eXtreme Design methodologies and best practices for data engineering, to reflect the perspectives and the requirements of various stakeholders into the design of the model, while leveraging ontology design patterns and accounting for provenance at different levels (claims, links). After presenting the main features of Music Meta, we provide a first evaluation of the model, alignments to other schema (Music Ontology, DOREMUS, Wikidata), and support for data transformation.