 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQueerGen: How LLMs Reflect Societal Norms on Gender and Sexuality in Sentence Completion Tasks
Jan 28, 2026This paper examines how Large Language Models (LLMs) reproduce societal norms, particularly heterocisnormativity, and how these norms translate into measurable biases in their text generations. We investigate whether explicit information about a subject's gender or sexuality influences LLM responses across three subject categories: queer-marked, non-queer-marked, and the normalized "unmarked" category. Representational imbalances are operationalized as measurable differences in English sentence completions across four dimensions: sentiment, regard, toxicity, and prediction diversity. Our findings show that Masked Language Models (MLMs) produce the least favorable sentiment, higher toxicity, and more negative regard for queer-marked subjects. Autoregressive Language Models (ARLMs) partially mitigate these patterns, while closed-access ARLMs tend to produce more harmful outputs for unmarked subjects. Results suggest that LLMs reproduce normative social assumptions, though the form and degree of bias depend strongly on specific model characteristics, which may redistribute, but not eliminate, representational harms.
Toxic Memes: A Survey of Computational Perspectives on the Detection and Explanation of Meme Toxicities
Jun 11, 2024
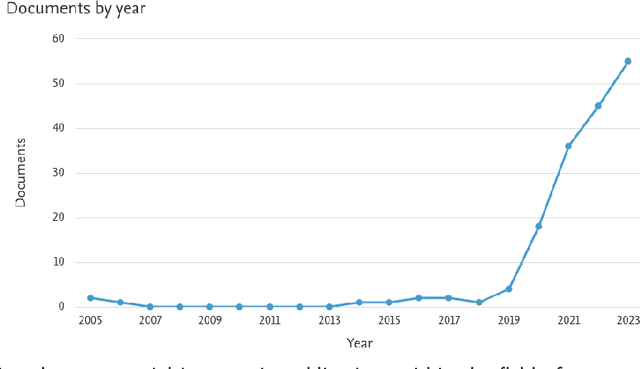


Internet memes, channels for humor, social commentary, and cultural expression, are increasingly used to spread toxic messages. Studies on the computational analyses of toxic memes have significantly grown over the past five years, and the only three surveys on computational toxic meme analysis cover only work published until 2022, leading to inconsistent terminology and unexplored trends. Our work fills this gap by surveying content-based computational perspectives on toxic memes, and reviewing key developments until early 2024. Employing the PRISMA methodology, we systematically extend the previously considered papers, achieving a threefold result. First, we survey 119 new papers, analyzing 158 computational works focused on content-based toxic meme analysis. We identify over 30 datasets used in toxic meme analysis and examine their labeling systems. Second, after observing the existence of unclear definitions of meme toxicity in computational works, we introduce a new taxonomy for categorizing meme toxicity types. We also note an expansion in computational tasks beyond the simple binary classification of memes as toxic or non-toxic, indicating a shift towards achieving a nuanced comprehension of toxicity. Third, we identify three content-based dimensions of meme toxicity under automatic study: target, intent, and conveyance tactics. We develop a framework illustrating the relationships between these dimensions and meme toxicities. The survey analyzes key challenges and recent trends, such as enhanced cross-modal reasoning, integrating expert and cultural knowledge, the demand for automatic toxicity explanations, and handling meme toxicity in low-resource languages. Also, it notes the rising use of Large Language Models (LLMs) and generative AI for detecting and generating toxic memes. Finally, it proposes pathways for advancing toxic meme detection and interpretation.
Situated Ground Truths: Enhancing Bias-Aware AI by Situating Data Labels with SituAnnotate
Jun 10, 2024In the contemporary world of AI and data-driven applications, supervised machines often derive their understanding, which they mimic and reproduce, through annotations--typically conveyed in the form of words or labels. However, such annotations are often divorced from or lack contextual information, and as such hold the potential to inadvertently introduce biases when subsequently used for training. This paper introduces SituAnnotate, a novel ontology explicitly crafted for 'situated grounding,' aiming to anchor the ground truth data employed in training AI systems within the contextual and culturally-bound situations from which those ground truths emerge. SituAnnotate offers an ontology-based approach to structured and context-aware data annotation, addressing potential bias issues associated with isolated annotations. Its representational power encompasses situational context, including annotator details, timing, location, remuneration schemes, annotation roles, and more, ensuring semantic richness. Aligned with the foundational Dolce Ultralight ontology, it provides a robust and consistent framework for knowledge representation. As a method to create, query, and compare label-based datasets, SituAnnotate empowers downstream AI systems to undergo training with explicit consideration of context and cultural bias, laying the groundwork for enhanced system interpretability and adaptability, and enabling AI models to align with a multitude of cultural contexts and viewpoints.
Stitching Gaps: Fusing Situated Perceptual Knowledge with Vision Transformers for High-Level Image Classification
Feb 29, 2024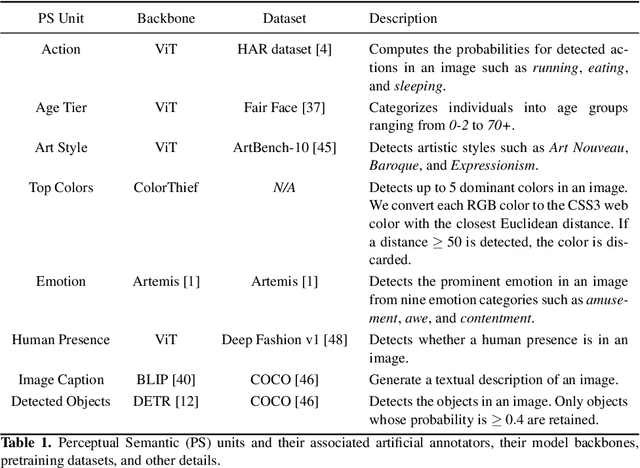
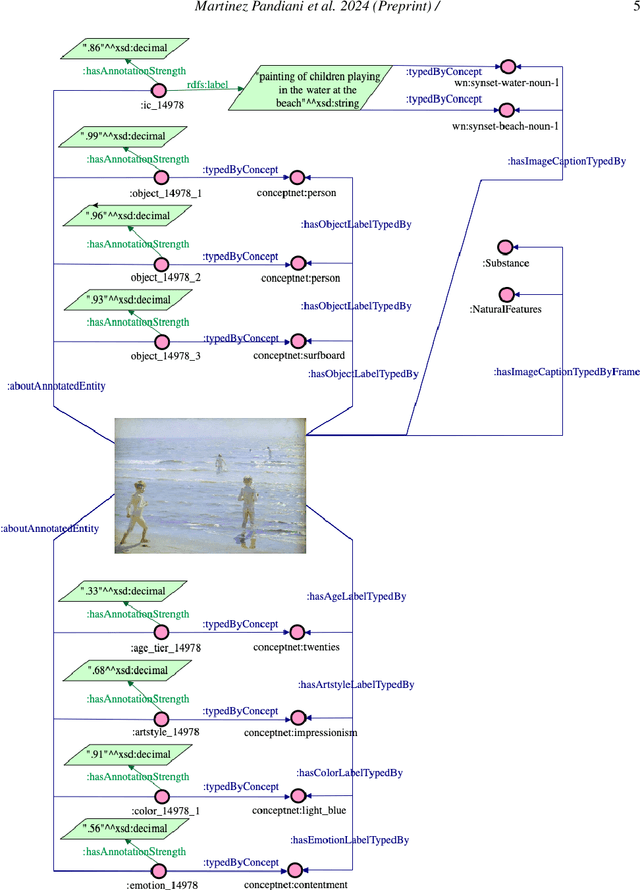
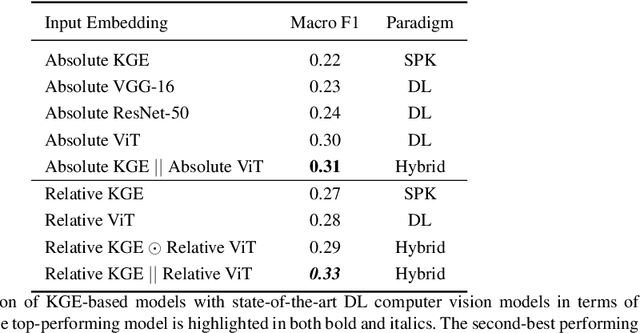
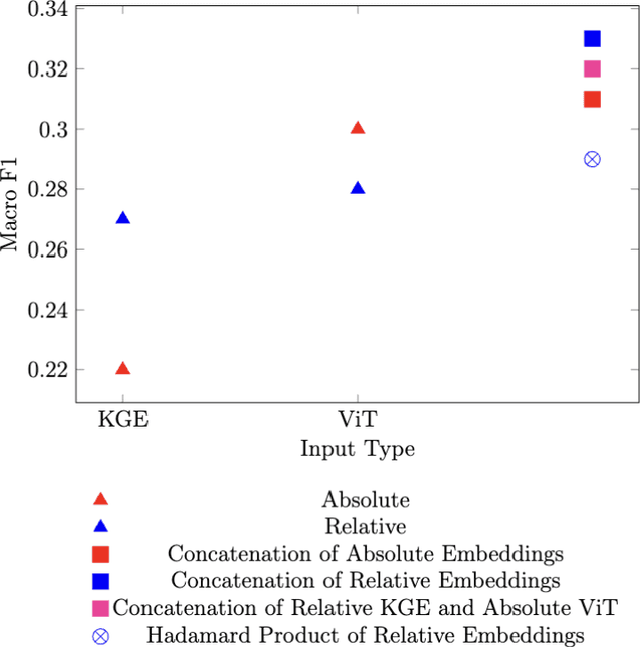
The increasing demand for automatic high-level image understanding, particularly in detecting abstract concepts (AC) within images, underscores the necessity for innovative and more interpretable approaches. These approaches need to harmonize traditional deep vision methods with the nuanced, context-dependent knowledge humans employ to interpret images at intricate semantic levels. In this work, we leverage situated perceptual knowledge of cultural images to enhance performance and interpretability in AC image classification. We automatically extract perceptual semantic units from images, which we then model and integrate into the ARTstract Knowledge Graph (AKG). This resource captures situated perceptual semantics gleaned from over 14,000 cultural images labeled with ACs. Additionally, we enhance the AKG with high-level linguistic frames. We compute KG embeddings and experiment with relative representations and hybrid approaches that fuse these embeddings with visual transformer embeddings. Finally, for interpretability, we conduct posthoc qualitative analyses by examining model similarities with training instances. Our results show that our hybrid KGE-ViT methods outperform existing techniques in AC image classification. The posthoc interpretability analyses reveal the visual transformer's proficiency in capturing pixel-level visual attributes, contrasting with our method's efficacy in representing more abstract and semantic scene elements. We demonstrate the synergy and complementarity between KGE embeddings' situated perceptual knowledge and deep visual model's sensory-perceptual understanding for AC image classification. This work suggests a strong potential of neuro-symbolic methods for knowledge integration and robust image representation for use in downstream intricate visual comprehension tasks. All the materials and code are available online.
Seeing the Intangible: Surveying Automatic High-Level Visual Understanding from Still Images
Aug 21, 2023The field of Computer Vision (CV) was born with the single grand goal of complete image understanding: providing a complete semantic interpretation of an input image. What exactly this goal entails is not immediately straightforward, but theoretical hierarchies of visual understanding point towards a top level of full semantics, within which sits the most complex and subjective information humans can detect from visual data. In particular, non-concrete concepts including emotions, social values and ideologies seem to be protagonists of this "high-level" visual semantic understanding. While such "abstract concepts" are critical tools for image management and retrieval, their automatic recognition is still a challenge, exactly because they rest at the top of the "semantic pyramid": the well-known semantic gap problem is worsened given their lack of unique perceptual referents, and their reliance on more unspecific features than concrete concepts. Given that there seems to be very scarce explicit work within CV on the task of abstract social concept (ASC) detection, and that many recent works seem to discuss similar non-concrete entities by using different terminology, in this survey we provide a systematic review of CV work that explicitly or implicitly approaches the problem of abstract (specifically social) concept detection from still images. Specifically, this survey performs and provides: (1) A study and clustering of high level visual understanding semantic elements from a multidisciplinary perspective (computer science, visual studies, and cognitive perspectives); (2) A study and clustering of high level visual understanding computer vision tasks dealing with the identified semantic elements, so as to identify current CV work that implicitly deals with AC detection.
Automatic Modeling of Social Concepts Evoked by Art Images as Multimodal Frames
Oct 14, 2021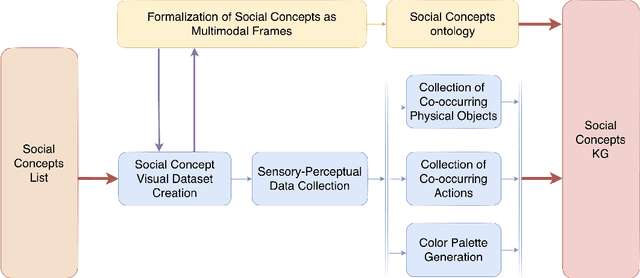
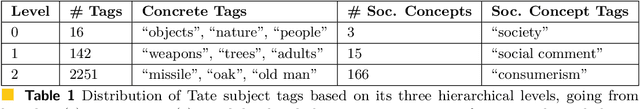
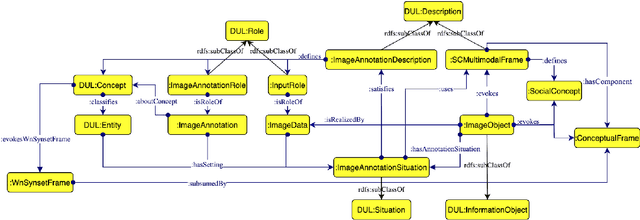
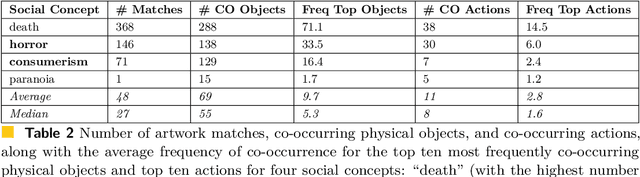
Social concepts referring to non-physical objects--such as revolution, violence, or friendship--are powerful tools to describe, index, and query the content of visual data, including ever-growing collections of art images from the Cultural Heritage (CH) field. While much progress has been made towards complete image understanding in computer vision, automatic detection of social concepts evoked by images is still a challenge. This is partly due to the well-known semantic gap problem, worsened for social concepts given their lack of unique physical features, and reliance on more unspecific features than concrete concepts. In this paper, we propose the translation of recent cognitive theories about social concept representation into a software approach to represent them as multimodal frames, by integrating multisensory data. Our method focuses on the extraction, analysis, and integration of multimodal features from visual art material tagged with the concepts of interest. We define a conceptual model and present a novel ontology for formally representing social concepts as multimodal frames. Taking the Tate Gallery's collection as an empirical basis, we experiment our method on a corpus of art images to provide a proof of concept of its potential. We discuss further directions of research, and provide all software, data sources, and results.