 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArgument Quality Assessment with Large Language Models: A Pairwise Bradley-Terry Approach
May 27, 2026Large Language Models (LLMs) have demonstrated remarkable capabilities in tasks related to reasoning and judgment. However, assessing the quality of arguments requires a rigorous evaluation. We investigate the extent to which LLMs can effectively perform this task. We tested 12 open-weight LLMs of different sizes and families under zero-shot, few-shot, and chain-of-thought to approximate expert pairwise comparisons of argument quality across three dimensions-logical, rhetorical, and dialectic-and used these comparisons in a Bradley-Terry model to infer latent strength scores and derive a ranking of arguments. Our insights show that LLMs have promising but moderate correlation with human expert judgments, with Llama-70B obtaining the strongest alignment, reaching moderate Cohen's $κ$ = 0.493 and moderate correlations with Bradley-Terry scores derived from these annotations (Kendall, Pearson, and Spearman: 0.327-0.477). Other LLMs exhibit weak, moderate, or high alignment with Llama-70B while achieving comparable results against human experts, suggesting partial but complementary understanding of underlying quality dimensions despite differences in model size and family. Moreover, LLM predictions are stable across trial runs, with fewer than 7.75\% of cases yielding different labels. Remaining variability is handled via majority voting and few-shot prompting for large-size models.
Leveraging Argument Structure to Predict Content Hatefulness
May 05, 2026Information disorder is a challenging phenomenon that affects society at large. This phenomenon entails the diffusion of misleading, misinforming, and hateful content online. In different contexts, one aspect of the problem may prevail, but overall, this is a broad problem that requires comprehensive solutions. While each dimension of the problem (hate speech, disinformation, misinformation, etc.) requires in-depth analysis, in this paper, we look into the possibility of argument structure to provide relevant information to link these different areas of the problem. In particular, we focus on the WSF-ARG+ dataset, which consists of white supremacy forum messages annotated in terms of argument structure (premises and conclusion). There, we leverage the checkworthiness and hatefulness annotations of the argument components to obtain insights into the hatefulness of the whole message. Our results show promising insights (up to 96% F1), indicating the possibility of extending this direction in the future to tackle hateful content identification and information disorder countering.
When Hate Meets Facts: LLMs-in-the-Loop for Check-worthiness Detection in Hate Speech
Mar 26, 2026Hateful content online is often expressed using fact-like, not necessarily correct information, especially in coordinated online harassment campaigns and extremist propaganda. Failing to jointly address hate speech (HS) and misinformation can deepen prejudice, reinforce harmful stereotypes, and expose bystanders to psychological distress, while polluting public debate. Moreover, these messages require more effort from content moderators because they must assess both harmfulness and veracity, i.e., fact-check them. To address this challenge, we release WSF-ARG+, the first dataset which combines hate speech with check-worthiness information. We also introduce a novel LLM-in-the-loop framework to facilitate the annotation of check-worthy claims. We run our framework, testing it with 12 open-weight LLMs of different sizes and architectures. We validate it through extensive human evaluation, and show that our LLM-in-the-loop framework reduces human effort without compromising the annotation quality of the data. Finally, we show that HS messages with check-worthy claims show significantly higher harassment and hate, and that incorporating check-worthiness labels improves LLM-based HS detection up to 0.213 macro-F1 and to 0.154 macro-F1 on average for large models.
Toward Reasonable Parrots: Why Large Language Models Should Argue with Us by Design
May 08, 2025

In this position paper, we advocate for the development of conversational technology that is inherently designed to support and facilitate argumentative processes. We argue that, at present, large language models (LLMs) are inadequate for this purpose, and we propose an ideal technology design aimed at enhancing argumentative skills. This involves re-framing LLMs as tools to exercise our critical thinking rather than replacing them. We introduce the concept of 'reasonable parrots' that embody the fundamental principles of relevance, responsibility, and freedom, and that interact through argumentative dialogical moves. These principles and moves arise out of millennia of work in argumentation theory and should serve as the starting point for LLM-based technology that incorporates basic principles of argumentation.
Toxic Memes: A Survey of Computational Perspectives on the Detection and Explanation of Meme Toxicities
Jun 11, 2024
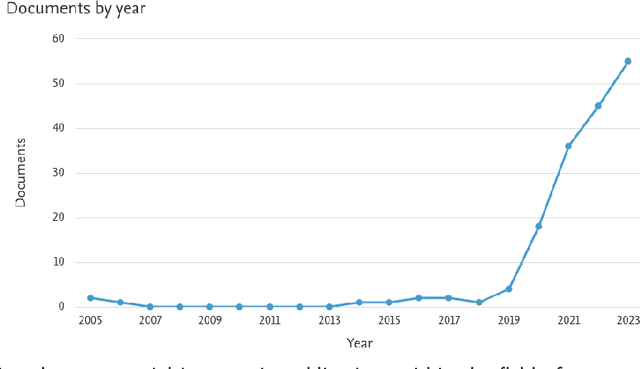


Internet memes, channels for humor, social commentary, and cultural expression, are increasingly used to spread toxic messages. Studies on the computational analyses of toxic memes have significantly grown over the past five years, and the only three surveys on computational toxic meme analysis cover only work published until 2022, leading to inconsistent terminology and unexplored trends. Our work fills this gap by surveying content-based computational perspectives on toxic memes, and reviewing key developments until early 2024. Employing the PRISMA methodology, we systematically extend the previously considered papers, achieving a threefold result. First, we survey 119 new papers, analyzing 158 computational works focused on content-based toxic meme analysis. We identify over 30 datasets used in toxic meme analysis and examine their labeling systems. Second, after observing the existence of unclear definitions of meme toxicity in computational works, we introduce a new taxonomy for categorizing meme toxicity types. We also note an expansion in computational tasks beyond the simple binary classification of memes as toxic or non-toxic, indicating a shift towards achieving a nuanced comprehension of toxicity. Third, we identify three content-based dimensions of meme toxicity under automatic study: target, intent, and conveyance tactics. We develop a framework illustrating the relationships between these dimensions and meme toxicities. The survey analyzes key challenges and recent trends, such as enhanced cross-modal reasoning, integrating expert and cultural knowledge, the demand for automatic toxicity explanations, and handling meme toxicity in low-resource languages. Also, it notes the rising use of Large Language Models (LLMs) and generative AI for detecting and generating toxic memes. Finally, it proposes pathways for advancing toxic meme detection and interpretation.
Nanopublication-Based Semantic Publishing and Reviewing: A Field Study with Formalization Papers
Mar 03, 2022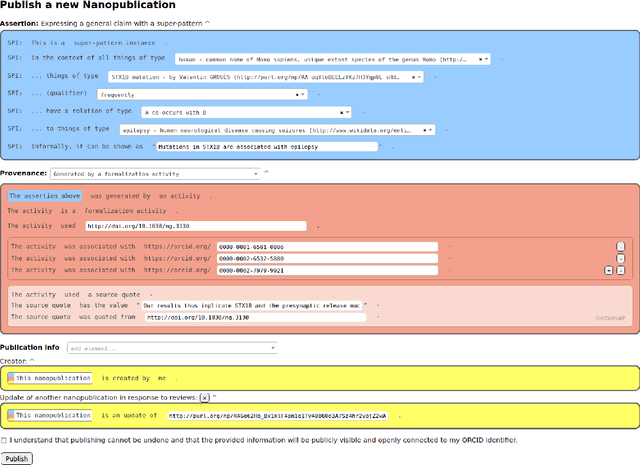
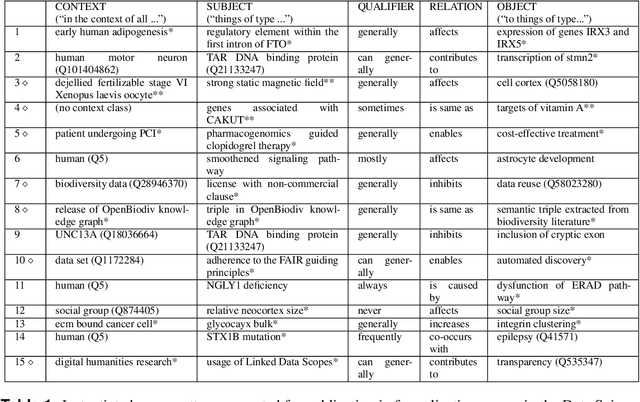
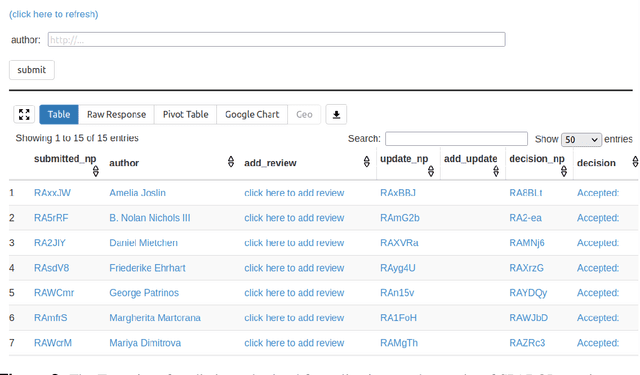
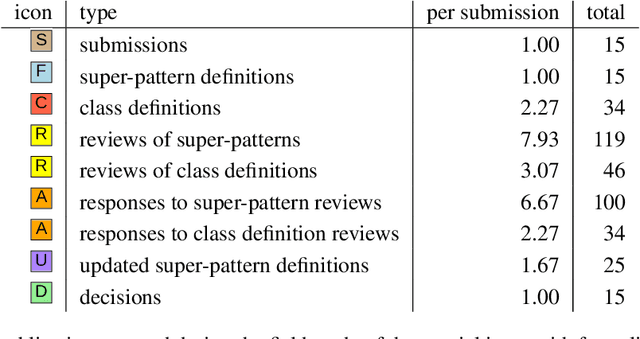
With the rapidly increasing amount of scientific literature,it is getting continuously more difficult for researchers in different disciplines to be updated with the recent findings in their field of study.Processing scientific articles in an automated fashion has been proposed as a solution to this problem,but the accuracy of such processing remains very poor for extraction tasks beyond the basic ones.Few approaches have tried to change how we publish scientific results in the first place,by making articles machine-interpretable by expressing them with formal semantics from the start.In the work presented here,we set out to demonstrate that we can formally publish high-level scientific claims in formal logic,and publish the results in a special issue of an existing journal.We use the concept and technology of nanopublications for this endeavor,and represent not just the submissions and final papers in this RDF-based format,but also the whole process in between,including reviews,responses,and decisions.We do this by performing a field study with what we call formalization papers,which contribute a novel formalization of a previously published claim.We received 15 submissions from 18 authors,who then went through the whole publication process leading to the publication of their contributions in the special issue.Our evaluation shows the technical and practical feasibility of our approach.The participating authors mostly showed high levels of interest and confidence,and mostly experienced the process as not very difficult,despite the technical nature of the current user interfaces.We believe that these results indicate that it is possible to publish scientific results from different fields with machine-interpretable semantics from the start,which in turn opens countless possibilities to radically improve in the future the effectiveness and efficiency of the scientific endeavor as a whole.
Expressing High-Level Scientific Claims with Formal Semantics
Sep 27, 2021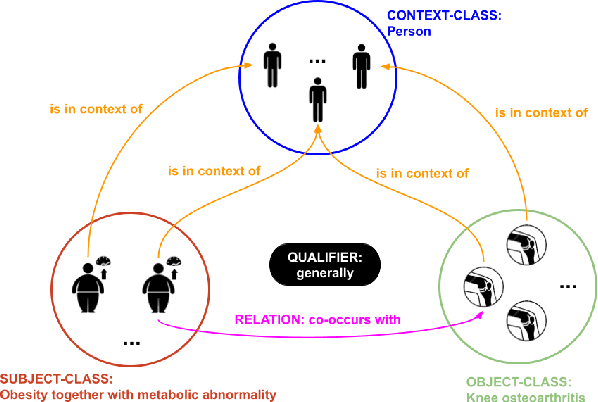
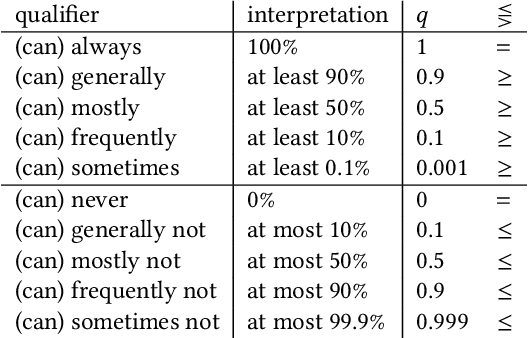
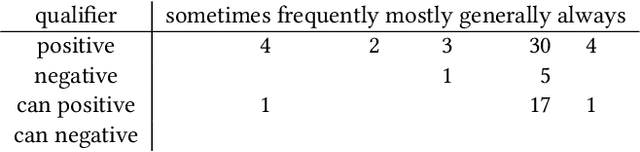
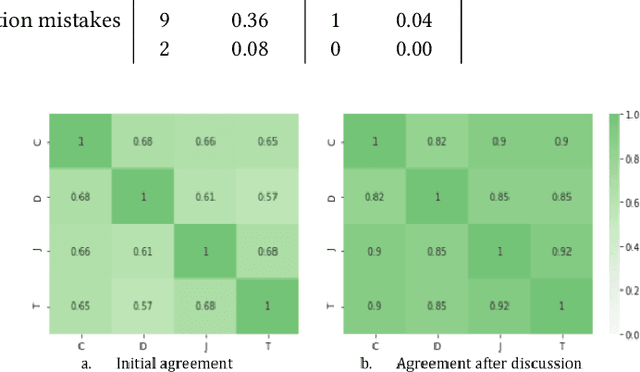
The use of semantic technologies is gaining significant traction in science communication with a wide array of applications in disciplines including the Life Sciences, Computer Science, and the Social Sciences. Languages like RDF, OWL, and other formalisms based on formal logic are applied to make scientific knowledge accessible not only to human readers but also to automated systems. These approaches have mostly focused on the structure of scientific publications themselves, on the used scientific methods and equipment, or on the structure of the used datasets. The core claims or hypotheses of scientific work have only been covered in a shallow manner, such as by linking mentioned entities to established identifiers. In this research, we therefore want to find out whether we can use existing semantic formalisms to fully express the content of high-level scientific claims using formal semantics in a systematic way. Analyzing the main claims from a sample of scientific articles from all disciplines, we find that their semantics are more complex than what a straight-forward application of formalisms like RDF or OWL account for, but we managed to elicit a clear semantic pattern which we call the 'super-pattern'. We show here how the instantiation of the five slots of this super-pattern leads to a strictly defined statement in higher-order logic. We successfully applied this super-pattern to an enlarged sample of scientific claims. We show that knowledge representation experts, when instructed to independently instantiate the super-pattern with given scientific claims, show a high degree of consistency and convergence given the complexity of the task and the subject. These results therefore open the door for expressing high-level scientific findings in a manner they can be automatically interpreted, which on the longer run can allow us to do automated consistency checking, and much more.
The Many Dimensions of Truthfulness: Crowdsourcing Misinformation Assessments on a Multidimensional Scale
Aug 23, 2021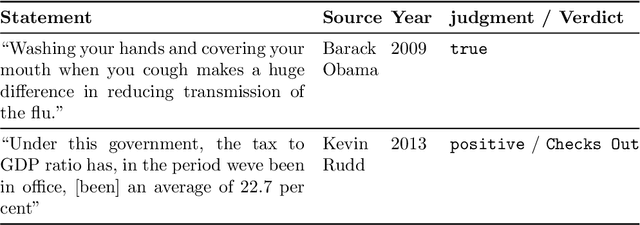
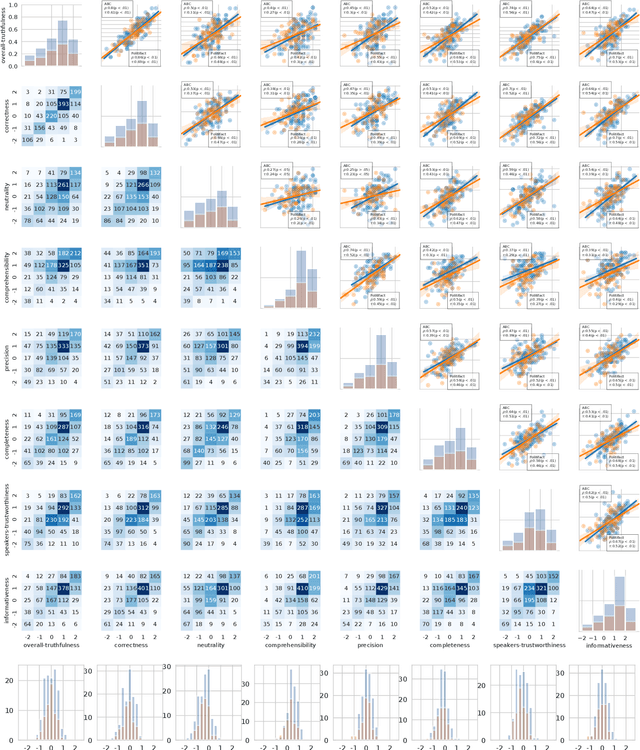
Recent work has demonstrated the viability of using crowdsourcing as a tool for evaluating the truthfulness of public statements. Under certain conditions such as: (1) having a balanced set of workers with different backgrounds and cognitive abilities; (2) using an adequate set of mechanisms to control the quality of the collected data; and (3) using a coarse grained assessment scale, the crowd can provide reliable identification of fake news. However, fake news are a subtle matter: statements can be just biased ("cherrypicked"), imprecise, wrong, etc. and the unidimensional truth scale used in existing work cannot account for such differences. In this paper we propose a multidimensional notion of truthfulness and we ask the crowd workers to assess seven different dimensions of truthfulness selected based on existing literature: Correctness, Neutrality, Comprehensibility, Precision, Completeness, Speaker's Trustworthiness, and Informativeness. We deploy a set of quality control mechanisms to ensure that the thousands of assessments collected on 180 publicly available fact-checked statements distributed over two datasets are of adequate quality, including a custom search engine used by the crowd workers to find web pages supporting their truthfulness assessments. A comprehensive analysis of crowdsourced judgments shows that: (1) the crowdsourced assessments are reliable when compared to an expert-provided gold standard; (2) the proposed dimensions of truthfulness capture independent pieces of information; (3) the crowdsourcing task can be easily learned by the workers; and (4) the resulting assessments provide a useful basis for a more complete estimation of statement truthfulness.
* 33 pages; Paper accepted at Information Processing & Management on July 28, 2021; IP&M Special Issue on Dis/Misinformation Mining from Social Media