 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToxic Memes: A Survey of Computational Perspectives on the Detection and Explanation of Meme Toxicities
Paper and Code

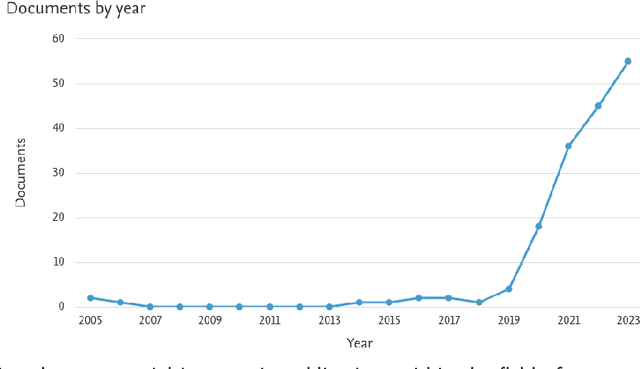


Internet memes, channels for humor, social commentary, and cultural expression, are increasingly used to spread toxic messages. Studies on the computational analyses of toxic memes have significantly grown over the past five years, and the only three surveys on computational toxic meme analysis cover only work published until 2022, leading to inconsistent terminology and unexplored trends. Our work fills this gap by surveying content-based computational perspectives on toxic memes, and reviewing key developments until early 2024. Employing the PRISMA methodology, we systematically extend the previously considered papers, achieving a threefold result. First, we survey 119 new papers, analyzing 158 computational works focused on content-based toxic meme analysis. We identify over 30 datasets used in toxic meme analysis and examine their labeling systems. Second, after observing the existence of unclear definitions of meme toxicity in computational works, we introduce a new taxonomy for categorizing meme toxicity types. We also note an expansion in computational tasks beyond the simple binary classification of memes as toxic or non-toxic, indicating a shift towards achieving a nuanced comprehension of toxicity. Third, we identify three content-based dimensions of meme toxicity under automatic study: target, intent, and conveyance tactics. We develop a framework illustrating the relationships between these dimensions and meme toxicities. The survey analyzes key challenges and recent trends, such as enhanced cross-modal reasoning, integrating expert and cultural knowledge, the demand for automatic toxicity explanations, and handling meme toxicity in low-resource languages. Also, it notes the rising use of Large Language Models (LLMs) and generative AI for detecting and generating toxic memes. Finally, it proposes pathways for advancing toxic meme detection and interpretation.