 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToxic Memes: A Survey of Computational Perspectives on the Detection and Explanation of Meme Toxicities
Jun 11, 2024Internet memes, channels for humor, social commentary, and cultural expression, are increasingly used to spread toxic messages. Studies on the computational analyses of toxic memes have significantly grown over the past five years, and the only three surveys on computational toxic meme analysis cover only work published until 2022, leading to inconsistent terminology and unexplored trends. Our work fills this gap by surveying content-based computational perspectives on toxic memes, and reviewing key developments until early 2024. Employing the PRISMA methodology, we systematically extend the previously considered papers, achieving a threefold result. First, we survey 119 new papers, analyzing 158 computational works focused on content-based toxic meme analysis. We identify over 30 datasets used in toxic meme analysis and examine their labeling systems. Second, after observing the existence of unclear definitions of meme toxicity in computational works, we introduce a new taxonomy for categorizing meme toxicity types. We also note an expansion in computational tasks beyond the simple binary classification of memes as toxic or non-toxic, indicating a shift towards achieving a nuanced comprehension of toxicity. Third, we identify three content-based dimensions of meme toxicity under automatic study: target, intent, and conveyance tactics. We develop a framework illustrating the relationships between these dimensions and meme toxicities. The survey analyzes key challenges and recent trends, such as enhanced cross-modal reasoning, integrating expert and cultural knowledge, the demand for automatic toxicity explanations, and handling meme toxicity in low-resource languages. Also, it notes the rising use of Large Language Models (LLMs) and generative AI for detecting and generating toxic memes. Finally, it proposes pathways for advancing toxic meme detection and interpretation.
Dutch General Public Reaction on Governmental COVID-19 Measures and Announcements in Twitter Data
Jun 12, 2020
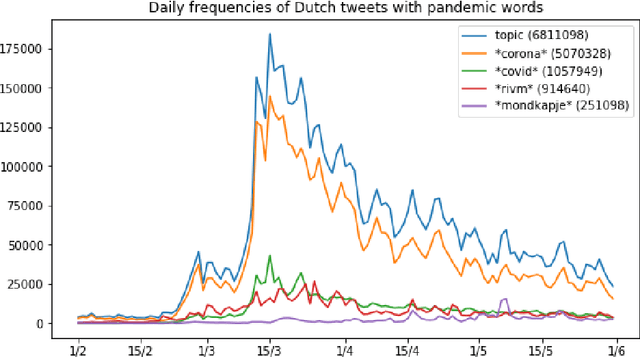
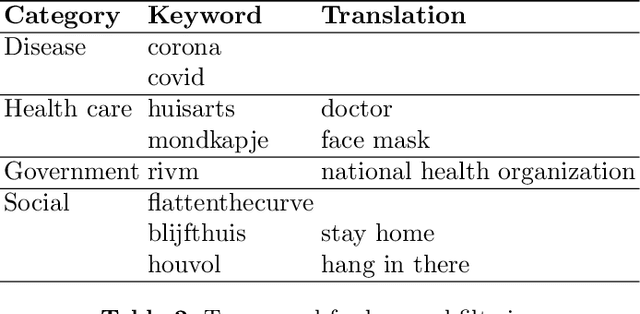
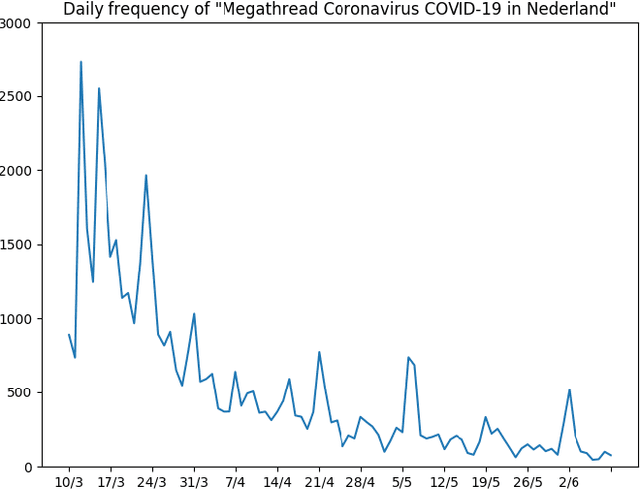
Public sentiment (the opinion, attitude or feeling that the public expresses) is a factor of interest for government, as it directly influences the implementation of policies. Given the unprecedented nature of the COVID-19 crisis, having an up-to-date representation of public sentiment on governmental measures and announcements is crucial. While the staying-at-home policy makes face-to-face interactions and interviews challenging, analysing real-time Twitter data that reflects public opinion toward policy measures is a cost-effective way to access public sentiment. In this paper, we collect streaming data using the Twitter API starting from the COVID-19 outbreak in the Netherlands in February 2020, and track Dutch general public reactions on governmental measures and announcements. We provide temporal analysis of tweet frequency and public sentiment over the past four months. We also identify public attitudes towards the Dutch policy on wearing face masks in a case study. By presenting those preliminary results, we aim to provide visibility into the social media discussions around COVID-19 to the general public, scientists and policy makers. The data collection and analysis will be updated and expanded over time.
Utilizing a Transparency-driven Environment toward Trusted Automatic Genre Classification: A Case Study in Journalism History
Oct 01, 2018
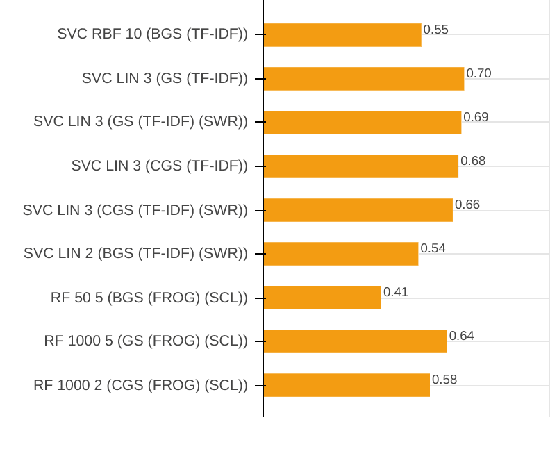
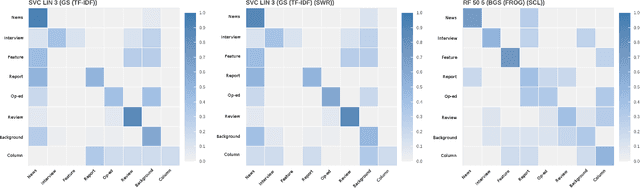
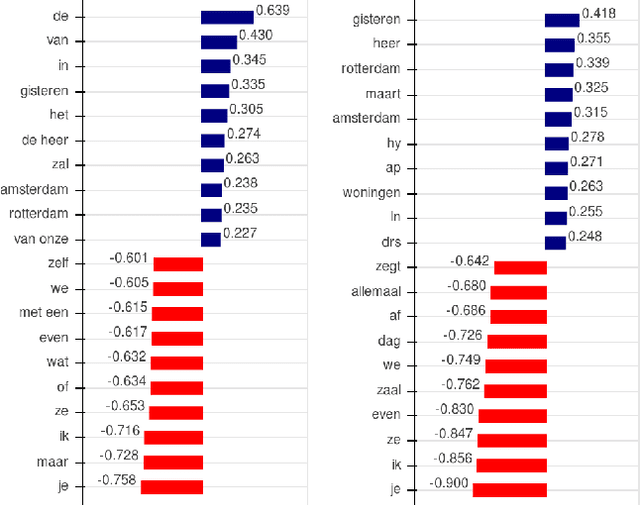
With the growing abundance of unlabeled data in real-world tasks, researchers have to rely on the predictions given by black-boxed computational models. However, it is an often neglected fact that these models may be scoring high on accuracy for the wrong reasons. In this paper, we present a practical impact analysis of enabling model transparency by various presentation forms. For this purpose, we developed an environment that empowers non-computer scientists to become practicing data scientists in their own research field. We demonstrate the gradually increasing understanding of journalism historians through a real-world use case study on automatic genre classification of newspaper articles. This study is a first step towards trusted usage of machine learning pipelines in a responsible way.
Meta-Learning for Phonemic Annotation of Corpora
Aug 18, 2000
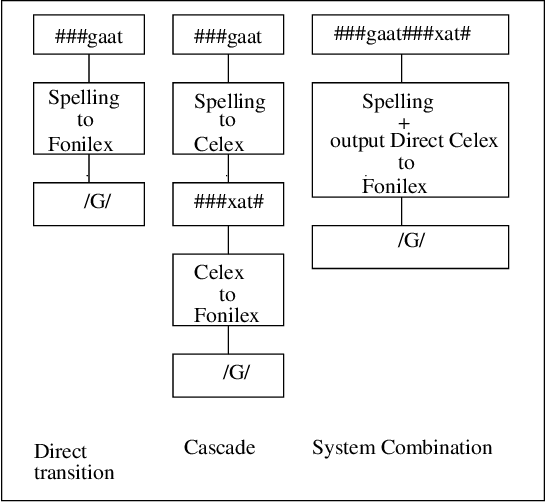

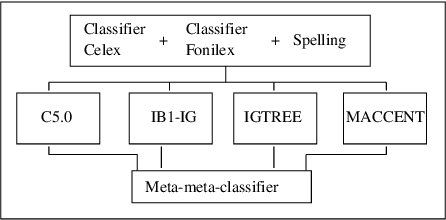
We apply rule induction, classifier combination and meta-learning (stacked classifiers) to the problem of bootstrapping high accuracy automatic annotation of corpora with pronunciation information. The task we address in this paper consists of generating phonemic representations reflecting the Flemish and Dutch pronunciations of a word on the basis of its orthographic representation (which in turn is based on the actual speech recordings). We compare several possible approaches to achieve the text-to-pronunciation mapping task: memory-based learning, transformation-based learning, rule induction, maximum entropy modeling, combination of classifiers in stacked learning, and stacking of meta-learners. We are interested both in optimal accuracy and in obtaining insight into the linguistic regularities involved. As far as accuracy is concerned, an already high accuracy level (93% for Celex and 86% for Fonilex at word level) for single classifiers is boosted significantly with additional error reductions of 31% and 38% respectively using combination of classifiers, and a further 5% using combination of meta-learners, bringing overall word level accuracy to 96% for the Dutch variant and 92% for the Flemish variant. We also show that the application of machine learning methods indeed leads to increased insight into the linguistic regularities determining the variation between the two pronunciation variants studied.
* 8 pages