 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFilling in the Gaps: Efficient Event Coreference Resolution using Graph Autoencoder Networks
Oct 18, 2023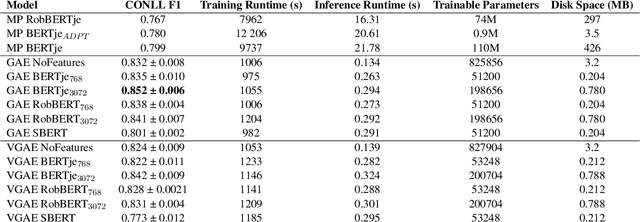



We introduce a novel and efficient method for Event Coreference Resolution (ECR) applied to a lower-resourced language domain. By framing ECR as a graph reconstruction task, we are able to combine deep semantic embeddings with structural coreference chain knowledge to create a parameter-efficient family of Graph Autoencoder models (GAE). Our method significantly outperforms classical mention-pair methods on a large Dutch event coreference corpus in terms of overall score, efficiency and training speed. Additionally, we show that our models are consistently able to classify more difficult coreference links and are far more robust in low-data settings when compared to transformer-based mention-pair coreference algorithms.
Nearest neighbour approaches for Emotion Detection in Tweets
Jul 08, 2021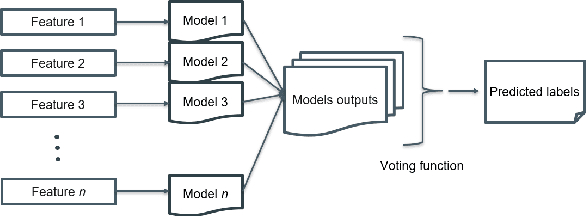
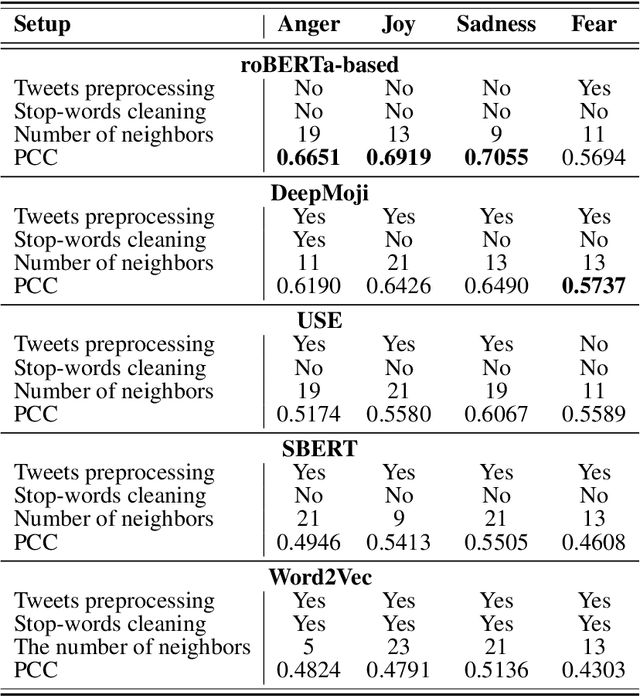
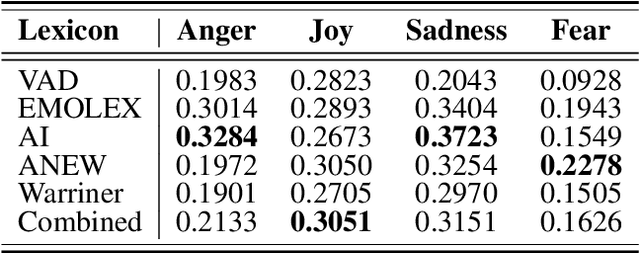

Emotion detection is an important task that can be applied to social media data to discover new knowledge. While the use of deep learning methods for this task has been prevalent, they are black-box models, making their decisions hard to interpret for a human operator. Therefore, in this paper, we propose an approach using weighted $k$ Nearest Neighbours (kNN), a simple, easy to implement, and explainable machine learning model. These qualities can help to enhance results' reliability and guide error analysis. In particular, we apply the weighted kNN model to the shared emotion detection task in tweets from SemEval-2018. Tweets are represented using different text embedding methods and emotion lexicon vocabulary scores, and classification is done by an ensemble of weighted kNN models. Our best approaches obtain results competitive with state-of-the-art solutions and open up a promising alternative path to neural network methods.
Fuzzy-Rough Nearest Neighbour Approaches for Emotion Detection in Tweets
Jul 08, 2021Social media are an essential source of meaningful data that can be used in different tasks such as sentiment analysis and emotion recognition. Mostly, these tasks are solved with deep learning methods. Due to the fuzzy nature of textual data, we consider using classification methods based on fuzzy rough sets. Specifically, we develop an approach for the SemEval-2018 emotion detection task, based on the fuzzy rough nearest neighbour (FRNN) classifier enhanced with ordered weighted average (OWA) operators. We use tuned ensembles of FRNN--OWA models based on different text embedding methods. Our results are competitive with the best SemEval solutions based on more complicated deep learning methods.
Meta-Learning for Phonemic Annotation of Corpora
Aug 18, 2000
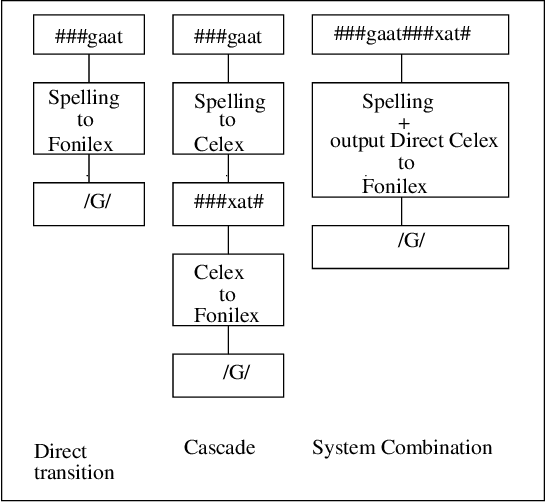

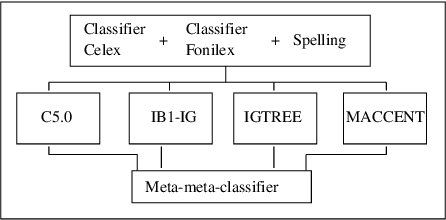
We apply rule induction, classifier combination and meta-learning (stacked classifiers) to the problem of bootstrapping high accuracy automatic annotation of corpora with pronunciation information. The task we address in this paper consists of generating phonemic representations reflecting the Flemish and Dutch pronunciations of a word on the basis of its orthographic representation (which in turn is based on the actual speech recordings). We compare several possible approaches to achieve the text-to-pronunciation mapping task: memory-based learning, transformation-based learning, rule induction, maximum entropy modeling, combination of classifiers in stacked learning, and stacking of meta-learners. We are interested both in optimal accuracy and in obtaining insight into the linguistic regularities involved. As far as accuracy is concerned, an already high accuracy level (93% for Celex and 86% for Fonilex at word level) for single classifiers is boosted significantly with additional error reductions of 31% and 38% respectively using combination of classifiers, and a further 5% using combination of meta-learners, bringing overall word level accuracy to 96% for the Dutch variant and 92% for the Flemish variant. We also show that the application of machine learning methods indeed leads to increased insight into the linguistic regularities determining the variation between the two pronunciation variants studied.
* 8 pages