 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeta-Learning for Phonemic Annotation of Corpora
Aug 18, 2000
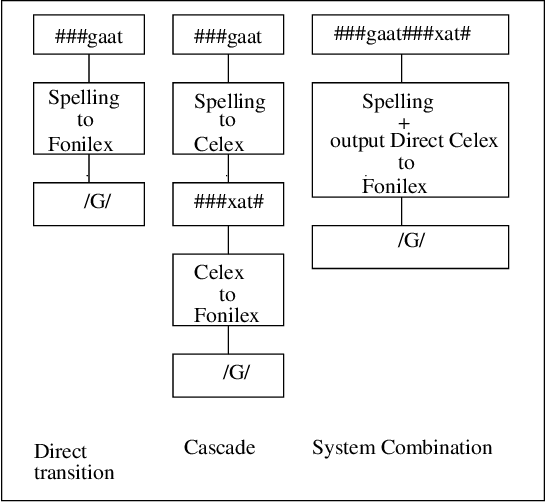

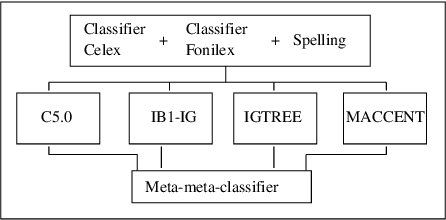
We apply rule induction, classifier combination and meta-learning (stacked classifiers) to the problem of bootstrapping high accuracy automatic annotation of corpora with pronunciation information. The task we address in this paper consists of generating phonemic representations reflecting the Flemish and Dutch pronunciations of a word on the basis of its orthographic representation (which in turn is based on the actual speech recordings). We compare several possible approaches to achieve the text-to-pronunciation mapping task: memory-based learning, transformation-based learning, rule induction, maximum entropy modeling, combination of classifiers in stacked learning, and stacking of meta-learners. We are interested both in optimal accuracy and in obtaining insight into the linguistic regularities involved. As far as accuracy is concerned, an already high accuracy level (93% for Celex and 86% for Fonilex at word level) for single classifiers is boosted significantly with additional error reductions of 31% and 38% respectively using combination of classifiers, and a further 5% using combination of meta-learners, bringing overall word level accuracy to 96% for the Dutch variant and 92% for the Flemish variant. We also show that the application of machine learning methods indeed leads to increased insight into the linguistic regularities determining the variation between the two pronunciation variants studied.
* 8 pages
Unsupervised Discovery of Phonological Categories through Supervised Learning of Morphological Rules
Jul 11, 1996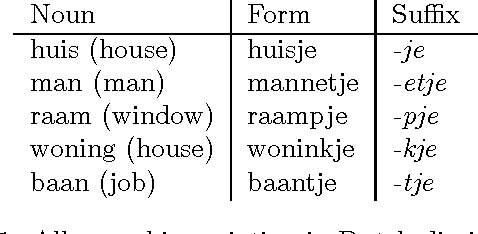
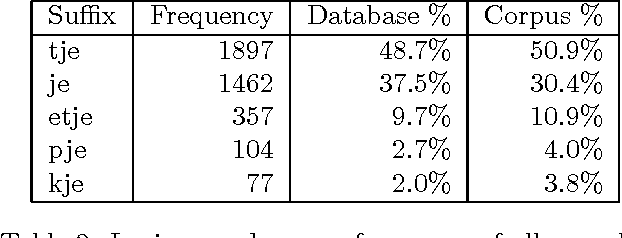
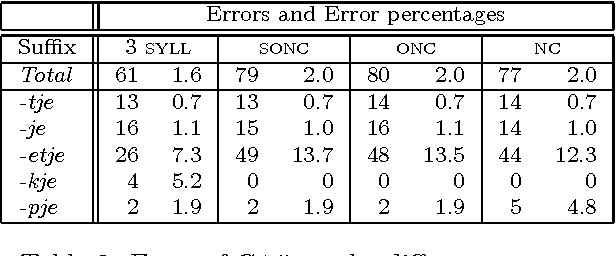
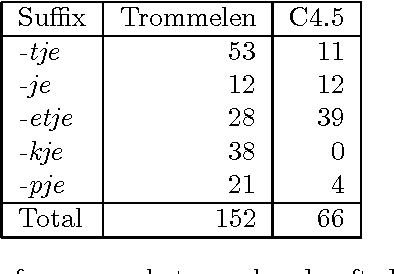
We describe a case study in the application of {\em symbolic machine learning} techniques for the discovery of linguistic rules and categories. A supervised rule induction algorithm is used to learn to predict the correct diminutive suffix given the phonological representation of Dutch nouns. The system produces rules which are comparable to rules proposed by linguists. Furthermore, in the process of learning this morphological task, the phonemes used are grouped into phonologically relevant categories. We discuss the relevance of our method for linguistics and language technology.
MBT: A Memory-Based Part of Speech Tagger-Generator
Jul 11, 1996



We introduce a memory-based approach to part of speech tagging. Memory-based learning is a form of supervised learning based on similarity-based reasoning. The part of speech tag of a word in a particular context is extrapolated from the most similar cases held in memory. Supervised learning approaches are useful when a tagged corpus is available as an example of the desired output of the tagger. Based on such a corpus, the tagger-generator automatically builds a tagger which is able to tag new text the same way, diminishing development time for the construction of a tagger considerably. Memory-based tagging shares this advantage with other statistical or machine learning approaches. Additional advantages specific to a memory-based approach include (i) the relatively small tagged corpus size sufficient for training, (ii) incremental learning, (iii) explanation capabilities, (iv) flexible integration of information in case representations, (v) its non-parametric nature, (vi) reasonably good results on unknown words without morphological analysis, and (vii) fast learning and tagging. In this paper we show that a large-scale application of the memory-based approach is feasible: we obtain a tagging accuracy that is on a par with that of known statistical approaches, and with attractive space and time complexity properties when using {\em IGTree}, a tree-based formalism for indexing and searching huge case bases.} The use of IGTree has as additional advantage that optimal context size for disambiguation is dynamically computed.
* 14 pages, 2 Postscript figures