 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Optimizing Multi-Agent Systems for Deep Research
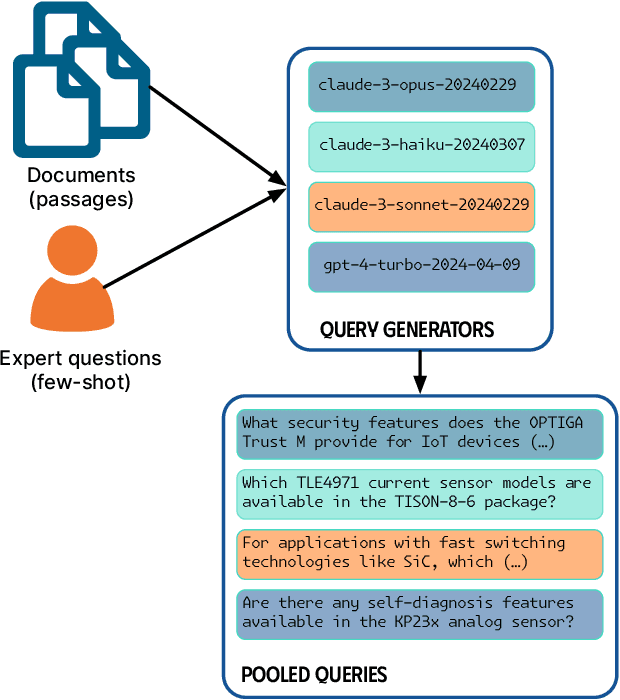
Apr 03, 2026Given a user's complex information need, a multi-agent Deep Research system iteratively plans, retrieves, and synthesizes evidence across hundreds of documents to produce a high-quality answer. In one possible architecture, an orchestrator agent coordinates the process, while parallel worker agents execute tasks. Current Deep Research systems, however, often rely on hand-engineered prompts and static architectures, making improvement brittle, expensive, and time-consuming. We therefore explore various multi-agent optimization methods to show that enabling agents to self-play and explore different prompt combinations can produce high-quality Deep Research systems that match or outperform expert-crafted prompts.
Evaluating RAG-Fusion with RAGElo: an Automated Elo-based Framework
Jun 20, 2024


Challenges in the automated evaluation of Retrieval-Augmented Generation (RAG) Question-Answering (QA) systems include hallucination problems in domain-specific knowledge and the lack of gold standard benchmarks for company internal tasks. This results in difficulties in evaluating RAG variations, like RAG-Fusion (RAGF), in the context of a product QA task at Infineon Technologies. To solve these problems, we propose a comprehensive evaluation framework, which leverages Large Language Models (LLMs) to generate large datasets of synthetic queries based on real user queries and in-domain documents, uses LLM-as-a-judge to rate retrieved documents and answers, evaluates the quality of answers, and ranks different variants of Retrieval-Augmented Generation (RAG) agents with RAGElo's automated Elo-based competition. LLM-as-a-judge rating of a random sample of synthetic queries shows a moderate, positive correlation with domain expert scoring in relevance, accuracy, completeness, and precision. While RAGF outperformed RAG in Elo score, a significance analysis against expert annotations also shows that RAGF significantly outperforms RAG in completeness, but underperforms in precision. In addition, Infineon's RAGF assistant demonstrated slightly higher performance in document relevance based on MRR@5 scores. We find that RAGElo positively aligns with the preferences of human annotators, though due caution is still required. Finally, RAGF's approach leads to more complete answers based on expert annotations and better answers overall based on RAGElo's evaluation criteria.
InPars Toolkit: A Unified and Reproducible Synthetic Data Generation Pipeline for Neural Information Retrieval
Jul 10, 2023Recent work has explored Large Language Models (LLMs) to overcome the lack of training data for Information Retrieval (IR) tasks. The generalization abilities of these models have enabled the creation of synthetic in-domain data by providing instructions and a few examples on a prompt. InPars and Promptagator have pioneered this approach and both methods have demonstrated the potential of using LLMs as synthetic data generators for IR tasks. This makes them an attractive solution for IR tasks that suffer from a lack of annotated data. However, the reproducibility of these methods was limited, because InPars' training scripts are based on TPUs -- which are not widely accessible -- and because the code for Promptagator was not released and its proprietary LLM is not publicly accessible. To fully realize the potential of these methods and make their impact more widespread in the research community, the resources need to be accessible and easy to reproduce by researchers and practitioners. Our main contribution is a unified toolkit for end-to-end reproducible synthetic data generation research, which includes generation, filtering, training and evaluation. Additionally, we provide an interface to IR libraries widely used by the community and support for GPU. Our toolkit not only reproduces the InPars method and partially reproduces Promptagator, but also provides a plug-and-play functionality allowing the use of different LLMs, exploring filtering methods and finetuning various reranker models on the generated data. We also made available all the synthetic data generated in this work for the 18 different datasets in the BEIR benchmark which took more than 2,000 GPU hours to be generated as well as the reranker models finetuned on the synthetic data. Code and data are available at https://github.com/zetaalphavector/InPars
InPars-v2: Large Language Models as Efficient Dataset Generators for Information Retrieval
Jan 14, 2023Recently, InPars introduced a method to efficiently use large language models (LLMs) in information retrieval tasks: via few-shot examples, an LLM is induced to generate relevant queries for documents. These synthetic query-document pairs can then be used to train a retriever. However, InPars and, more recently, Promptagator, rely on proprietary LLMs such as GPT-3 and FLAN to generate such datasets. In this work we introduce InPars-v2, a dataset generator that uses open-source LLMs and existing powerful rerankers to select synthetic query-document pairs for training. A simple BM25 retrieval pipeline followed by a monoT5 reranker finetuned on InPars-v2 data achieves new state-of-the-art results on the BEIR benchmark. To allow researchers to further improve our method, we open source the code, synthetic data, and finetuned models: https://github.com/zetaalphavector/inPars/tree/master/tpu
A New Neural Search and Insights Platform for Navigating and Organizing AI Research
Oct 30, 2020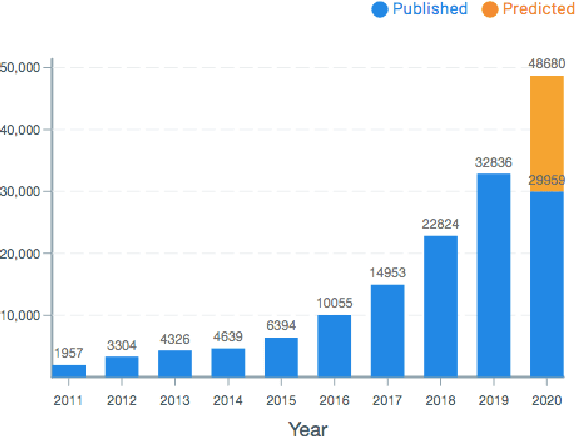
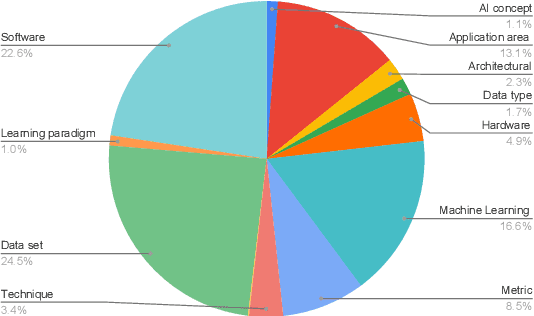
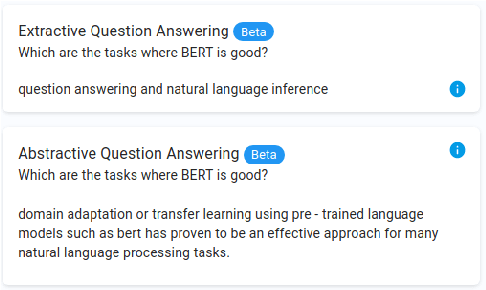
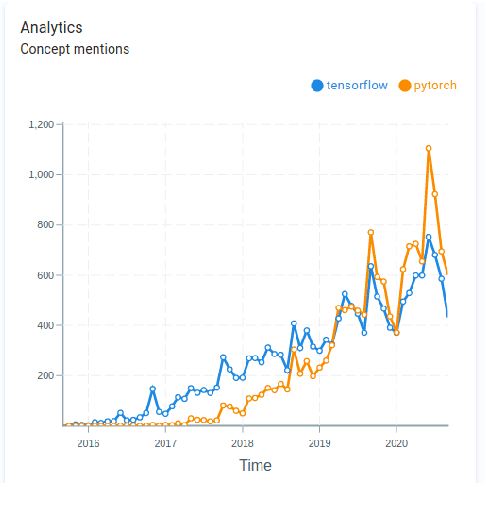
To provide AI researchers with modern tools for dealing with the explosive growth of the research literature in their field, we introduce a new platform, AI Research Navigator, that combines classical keyword search with neural retrieval to discover and organize relevant literature. The system provides search at multiple levels of textual granularity, from sentences to aggregations across documents, both in natural language and through navigation in a domain-specific Knowledge Graph. We give an overview of the overall architecture of the system and of the components for document analysis, question answering, search, analytics, expert search, and recommendations.
Effective Distributed Representations for Academic Expert Search
Oct 16, 2020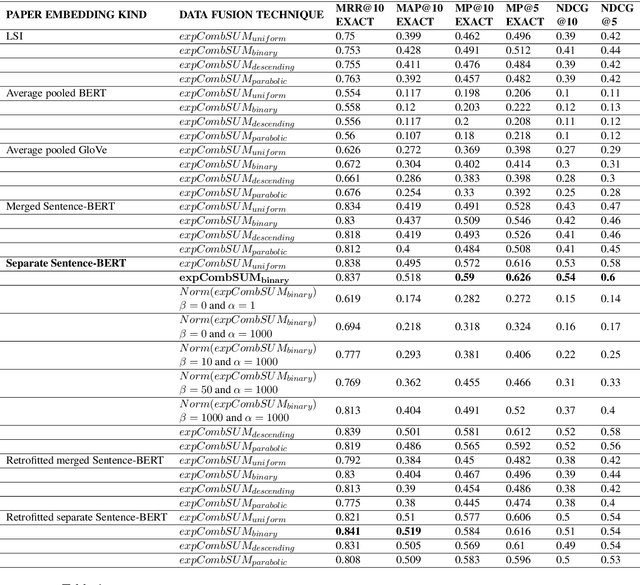


Expert search aims to find and rank experts based on a user's query. In academia, retrieving experts is an efficient way to navigate through a large amount of academic knowledge. Here, we study how different distributed representations of academic papers (i.e. embeddings) impact academic expert retrieval. We use the Microsoft Academic Graph dataset and experiment with different configurations of a document-centric voting model for retrieval. In particular, we explore the impact of the use of contextualized embeddings on search performance. We also present results for paper embeddings that incorporate citation information through retrofitting. Additionally, experiments are conducted using different techniques for assigning author weights based on author order. We observe that using contextual embeddings produced by a transformer model trained for sentence similarity tasks produces the most effective paper representations for document-centric expert retrieval. However, retrofitting the paper embeddings and using elaborate author contribution weighting strategies did not improve retrieval performance.
Bootstrapping a Tagged Corpus through Combination of Existing Heterogeneous Taggers
Jul 13, 2000
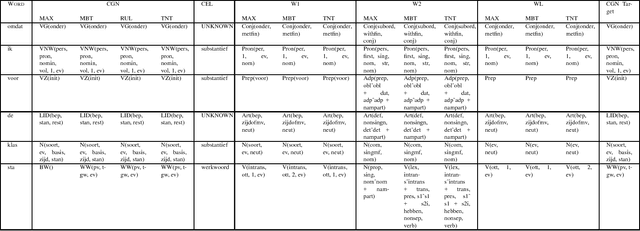
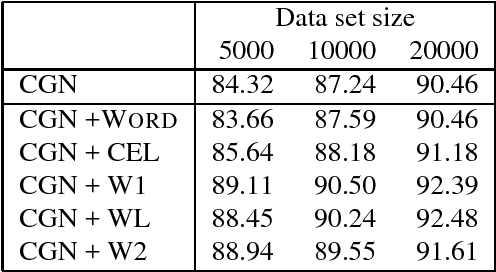

This paper describes a new method, Combi-bootstrap, to exploit existing taggers and lexical resources for the annotation of corpora with new tagsets. Combi-bootstrap uses existing resources as features for a second level machine learning module, that is trained to make the mapping to the new tagset on a very small sample of annotated corpus material. Experiments show that Combi-bootstrap: i) can integrate a wide variety of existing resources, and ii) achieves much higher accuracy (up to 44.7 % error reduction) than both the best single tagger and an ensemble tagger constructed out of the same small training sample.
* 4 pages
Forgetting Exceptions is Harmful in Language Learning
Dec 22, 1998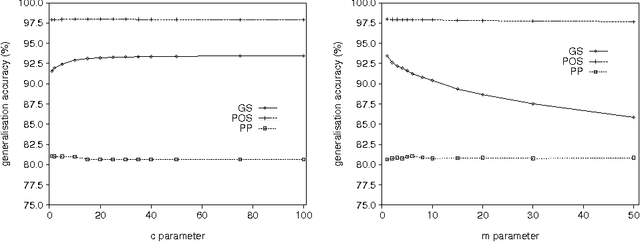
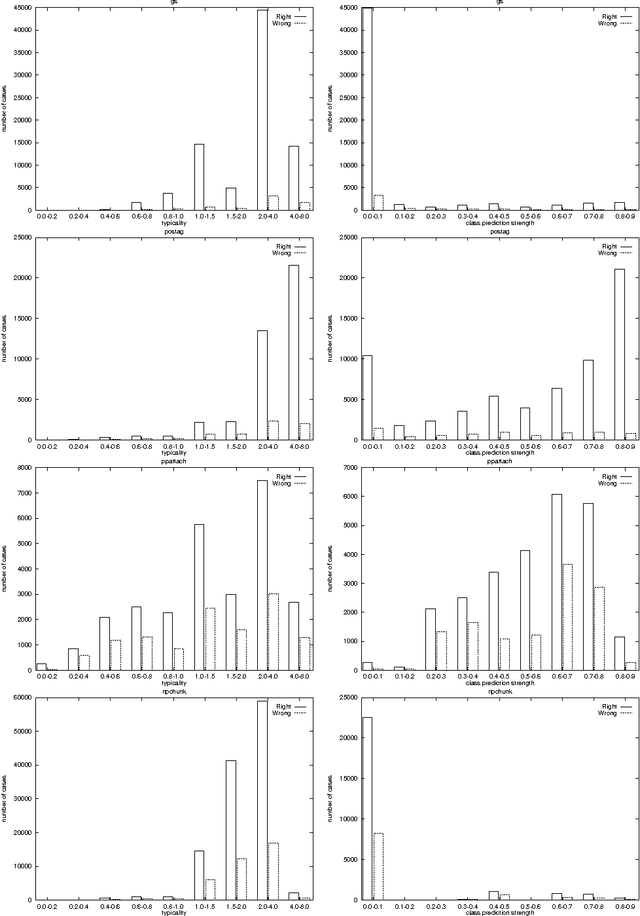
We show that in language learning, contrary to received wisdom, keeping exceptional training instances in memory can be beneficial for generalization accuracy. We investigate this phenomenon empirically on a selection of benchmark natural language processing tasks: grapheme-to-phoneme conversion, part-of-speech tagging, prepositional-phrase attachment, and base noun phrase chunking. In a first series of experiments we combine memory-based learning with training set editing techniques, in which instances are edited based on their typicality and class prediction strength. Results show that editing exceptional instances (with low typicality or low class prediction strength) tends to harm generalization accuracy. In a second series of experiments we compare memory-based learning and decision-tree learning methods on the same selection of tasks, and find that decision-tree learning often performs worse than memory-based learning. Moreover, the decrease in performance can be linked to the degree of abstraction from exceptions (i.e., pruning or eagerness). We provide explanations for both results in terms of the properties of the natural language processing tasks and the learning algorithms.
Improving Data Driven Wordclass Tagging by System Combination
Jul 31, 1998
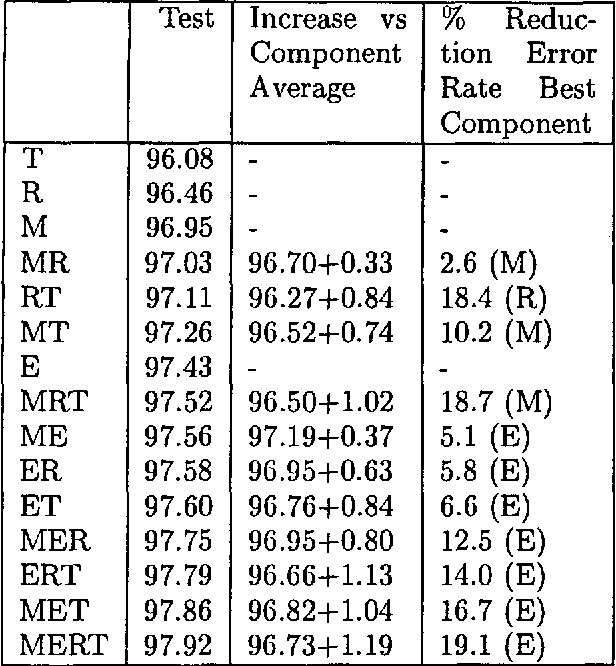
In this paper we examine how the differences in modelling between different data driven systems performing the same NLP task can be exploited to yield a higher accuracy than the best individual system. We do this by means of an experiment involving the task of morpho-syntactic wordclass tagging. Four well-known tagger generators (Hidden Markov Model, Memory-Based, Transformation Rules and Maximum Entropy) are trained on the same corpus data. After comparison, their outputs are combined using several voting strategies and second stage classifiers. All combination taggers outperform their best component, with the best combination showing a 19.1% lower error rate than the best individual tagger.
* 7 pages, LaTeX, uses acl.bst, colacl.sty
Memory-Based Learning: Using Similarity for Smoothing
May 12, 1997
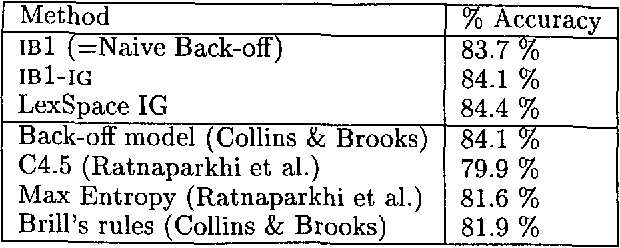

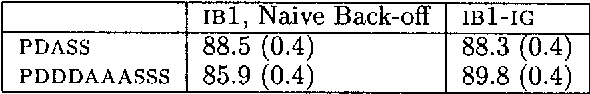
This paper analyses the relation between the use of similarity in Memory-Based Learning and the notion of backed-off smoothing in statistical language modeling. We show that the two approaches are closely related, and we argue that feature weighting methods in the Memory-Based paradigm can offer the advantage of automatically specifying a suitable domain-specific hierarchy between most specific and most general conditioning information without the need for a large number of parameters. We report two applications of this approach: PP-attachment and POS-tagging. Our method achieves state-of-the-art performance in both domains, and allows the easy integration of diverse information sources, such as rich lexical representations.