Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Data Driven Wordclass Tagging by System Combination
Paper and Code
Jul 31, 1998
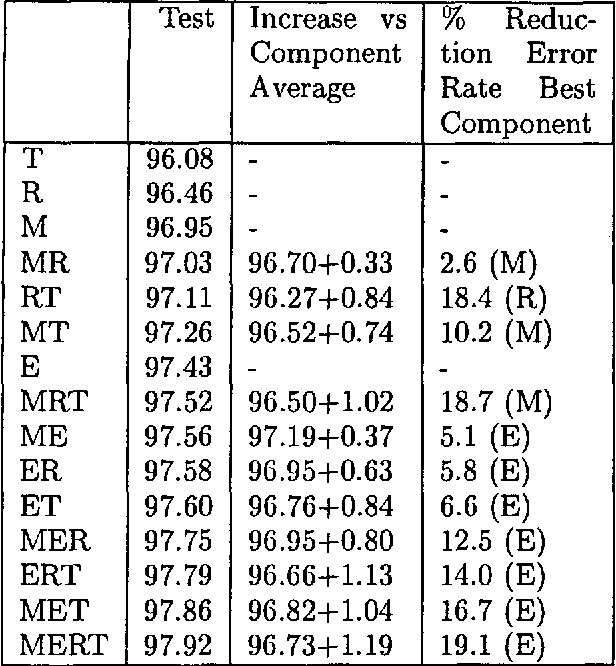
In this paper we examine how the differences in modelling between different data driven systems performing the same NLP task can be exploited to yield a higher accuracy than the best individual system. We do this by means of an experiment involving the task of morpho-syntactic wordclass tagging. Four well-known tagger generators (Hidden Markov Model, Memory-Based, Transformation Rules and Maximum Entropy) are trained on the same corpus data. After comparison, their outputs are combined using several voting strategies and second stage classifiers. All combination taggers outperform their best component, with the best combination showing a 19.1% lower error rate than the best individual tagger.
* Proceedings of the 17th International Conference on Computational
Linguistics (COLING-ACL'98) * 7 pages, LaTeX, uses acl.bst, colacl.sty
View paper on