 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCompressing Language Models for Specialized Domains
Feb 25, 2025Compression techniques such as pruning and quantization offer a solution for more efficient deployment of language models (LMs), albeit with small performance drops in benchmark performance. However, general-purpose LM compression methods can negatively affect performance in specialized domains (e.g. biomedical or legal). Recent work has sought to address this, yet requires computationally expensive full-parameter fine-tuning. To this end, we propose cross-calibration, a novel training-free approach for improving the domain performance of compressed LMs. Our approach effectively leverages Hessian-based sensitivity to identify weights that are influential for both in-domain and general performance. Through extensive experimentation, we demonstrate that cross-calibration substantially outperforms existing approaches on domain-specific tasks, without compromising general performance. Notably, these gains come without additional computational overhead, displaying remarkable potential towards extracting domain-specialized compressed models from general-purpose LMs.
InPars Toolkit: A Unified and Reproducible Synthetic Data Generation Pipeline for Neural Information Retrieval
Jul 10, 2023Recent work has explored Large Language Models (LLMs) to overcome the lack of training data for Information Retrieval (IR) tasks. The generalization abilities of these models have enabled the creation of synthetic in-domain data by providing instructions and a few examples on a prompt. InPars and Promptagator have pioneered this approach and both methods have demonstrated the potential of using LLMs as synthetic data generators for IR tasks. This makes them an attractive solution for IR tasks that suffer from a lack of annotated data. However, the reproducibility of these methods was limited, because InPars' training scripts are based on TPUs -- which are not widely accessible -- and because the code for Promptagator was not released and its proprietary LLM is not publicly accessible. To fully realize the potential of these methods and make their impact more widespread in the research community, the resources need to be accessible and easy to reproduce by researchers and practitioners. Our main contribution is a unified toolkit for end-to-end reproducible synthetic data generation research, which includes generation, filtering, training and evaluation. Additionally, we provide an interface to IR libraries widely used by the community and support for GPU. Our toolkit not only reproduces the InPars method and partially reproduces Promptagator, but also provides a plug-and-play functionality allowing the use of different LLMs, exploring filtering methods and finetuning various reranker models on the generated data. We also made available all the synthetic data generated in this work for the 18 different datasets in the BEIR benchmark which took more than 2,000 GPU hours to be generated as well as the reranker models finetuned on the synthetic data. Code and data are available at https://github.com/zetaalphavector/InPars
Simple Yet Effective Neural Ranking and Reranking Baselines for Cross-Lingual Information Retrieval
Apr 03, 2023The advent of multilingual language models has generated a resurgence of interest in cross-lingual information retrieval (CLIR), which is the task of searching documents in one language with queries from another. However, the rapid pace of progress has led to a confusing panoply of methods and reproducibility has lagged behind the state of the art. In this context, our work makes two important contributions: First, we provide a conceptual framework for organizing different approaches to cross-lingual retrieval using multi-stage architectures for mono-lingual retrieval as a scaffold. Second, we implement simple yet effective reproducible baselines in the Anserini and Pyserini IR toolkits for test collections from the TREC 2022 NeuCLIR Track, in Persian, Russian, and Chinese. Our efforts are built on a collaboration of the two teams that submitted the most effective runs to the TREC evaluation. These contributions provide a firm foundation for future advances.
NeuralMind-UNICAMP at 2022 TREC NeuCLIR: Large Boring Rerankers for Cross-lingual Retrieval
Mar 28, 2023This paper reports on a study of cross-lingual information retrieval (CLIR) using the mT5-XXL reranker on the NeuCLIR track of TREC 2022. Perhaps the biggest contribution of this study is the finding that despite the mT5 model being fine-tuned only on query-document pairs of the same language it proved to be viable for CLIR tasks, where query-document pairs are in different languages, even in the presence of suboptimal first-stage retrieval performance. The results of the study show outstanding performance across all tasks and languages, leading to a high number of winning positions. Finally, this study provides valuable insights into the use of mT5 in CLIR tasks and highlights its potential as a viable solution. For reproduction refer to https://github.com/unicamp-dl/NeuCLIR22-mT5
InPars-v2: Large Language Models as Efficient Dataset Generators for Information Retrieval
Jan 14, 2023Recently, InPars introduced a method to efficiently use large language models (LLMs) in information retrieval tasks: via few-shot examples, an LLM is induced to generate relevant queries for documents. These synthetic query-document pairs can then be used to train a retriever. However, InPars and, more recently, Promptagator, rely on proprietary LLMs such as GPT-3 and FLAN to generate such datasets. In this work we introduce InPars-v2, a dataset generator that uses open-source LLMs and existing powerful rerankers to select synthetic query-document pairs for training. A simple BM25 retrieval pipeline followed by a monoT5 reranker finetuned on InPars-v2 data achieves new state-of-the-art results on the BEIR benchmark. To allow researchers to further improve our method, we open source the code, synthetic data, and finetuned models: https://github.com/zetaalphavector/inPars/tree/master/tpu
In Defense of Cross-Encoders for Zero-Shot Retrieval
Dec 12, 2022Bi-encoders and cross-encoders are widely used in many state-of-the-art retrieval pipelines. In this work we study the generalization ability of these two types of architectures on a wide range of parameter count on both in-domain and out-of-domain scenarios. We find that the number of parameters and early query-document interactions of cross-encoders play a significant role in the generalization ability of retrieval models. Our experiments show that increasing model size results in marginal gains on in-domain test sets, but much larger gains in new domains never seen during fine-tuning. Furthermore, we show that cross-encoders largely outperform bi-encoders of similar size in several tasks. In the BEIR benchmark, our largest cross-encoder surpasses a state-of-the-art bi-encoder by more than 4 average points. Finally, we show that using bi-encoders as first-stage retrievers provides no gains in comparison to a simpler retriever such as BM25 on out-of-domain tasks. The code is available at https://github.com/guilhermemr04/scaling-zero-shot-retrieval.git
mRobust04: A Multilingual Version of the TREC Robust 2004 Benchmark
Sep 27, 2022
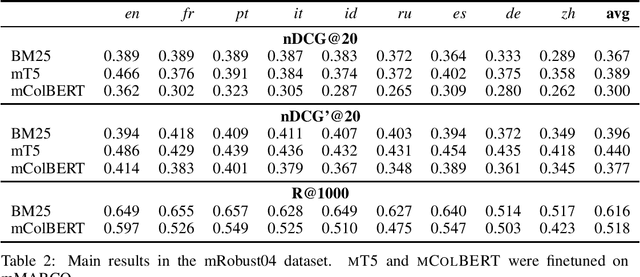
Robust 2004 is an information retrieval benchmark whose large number of judgments per query make it a reliable evaluation dataset. In this paper, we present mRobust04, a multilingual version of Robust04 that was translated to 8 languages using Google Translate. We also provide results of three different multilingual retrievers on this dataset. The dataset is available at https://huggingface.co/datasets/unicamp-dl/mrobust
A Boring-yet-effective Approach for the Product Ranking Task of the Amazon KDD Cup 2022
Aug 09, 2022
In this work we describe our submission to the product ranking task of the Amazon KDD Cup 2022. We rely on a receipt that showed to be effective in previous competitions: we focus our efforts towards efficiently training and deploying large language odels, such as mT5, while reducing to a minimum the number of task-specific adaptations. Despite the simplicity of our approach, our best model was less than 0.004 nDCG@20 below the top submission. As the top 20 teams achieved an nDCG@20 close to .90, we argue that we need more difficult e-Commerce evaluation datasets to discriminate retrieval methods.
No Parameter Left Behind: How Distillation and Model Size Affect Zero-Shot Retrieval
Jun 06, 2022



Recent work has shown that small distilled language models are strong competitors to models that are orders of magnitude larger and slower in a wide range of information retrieval tasks. This has made distilled and dense models, due to latency constraints, the go-to choice for deployment in real-world retrieval applications. In this work, we question this practice by showing that the number of parameters and early query-document interaction play a significant role in the generalization ability of retrieval models. Our experiments show that increasing model size results in marginal gains on in-domain test sets, but much larger gains in new domains never seen during fine-tuning. Furthermore, we show that rerankers largely outperform dense ones of similar size in several tasks. Our largest reranker reaches the state of the art in 12 of the 18 datasets of the Benchmark-IR (BEIR) and surpasses the previous state of the art by 3 average points. Finally, we confirm that in-domain effectiveness is not a good indicator of zero-shot effectiveness. Code is available at https://github.com/guilhermemr04/scaling-zero-shot-retrieval.git
Billions of Parameters Are Worth More Than In-domain Training Data: A case study in the Legal Case Entailment Task
May 30, 2022
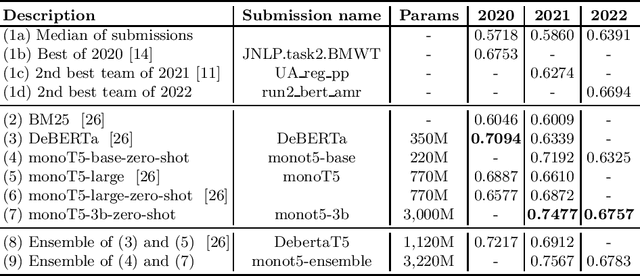
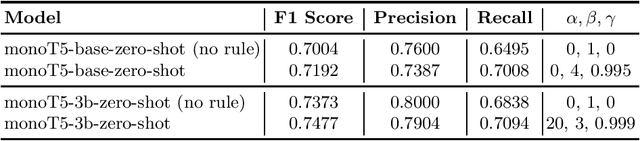
Recent work has shown that language models scaled to billions of parameters, such as GPT-3, perform remarkably well in zero-shot and few-shot scenarios. In this work, we experiment with zero-shot models in the legal case entailment task of the COLIEE 2022 competition. Our experiments show that scaling the number of parameters in a language model improves the F1 score of our previous zero-shot result by more than 6 points, suggesting that stronger zero-shot capability may be a characteristic of larger models, at least for this task. Our 3B-parameter zero-shot model outperforms all models, including ensembles, in the COLIEE 2021 test set and also achieves the best performance of a single model in the COLIEE 2022 competition, second only to the ensemble composed of the 3B model itself and a smaller version of the same model. Despite the challenges posed by large language models, mainly due to latency constraints in real-time applications, we provide a demonstration of our zero-shot monoT5-3b model being used in production as a search engine, including for legal documents. The code for our submission and the demo of our system are available at https://github.com/neuralmind-ai/coliee and https://neuralsearchx.neuralmind.ai, respectively.