 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Automatic Relevance Judgment using Vision--Language Models for Image--Text Retrieval Evaluation
Aug 02, 2024



Vision--Language Models (VLMs) have demonstrated success across diverse applications, yet their potential to assist in relevance judgments remains uncertain. This paper assesses the relevance estimation capabilities of VLMs, including CLIP, LLaVA, and GPT-4V, within a large-scale \textit{ad hoc} retrieval task tailored for multimedia content creation in a zero-shot fashion. Preliminary experiments reveal the following: (1) Both LLaVA and GPT-4V, encompassing open-source and closed-source visual-instruction-tuned Large Language Models (LLMs), achieve notable Kendall's $\tau \sim 0.4$ when compared to human relevance judgments, surpassing the CLIPScore metric. (2) While CLIPScore is strongly preferred, LLMs are less biased towards CLIP-based retrieval systems. (3) GPT-4V's score distribution aligns more closely with human judgments than other models, achieving a Cohen's $\kappa$ value of around 0.08, which outperforms CLIPScore at approximately -0.096. These findings underscore the potential of LLM-powered VLMs in enhancing relevance judgments.
Resources for Brewing BEIR: Reproducible Reference Models and an Official Leaderboard
Jun 13, 2023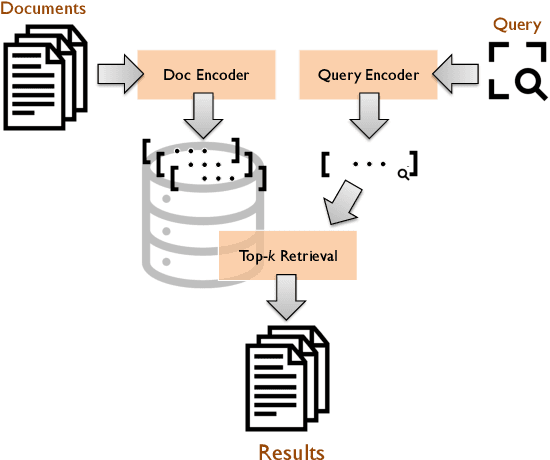
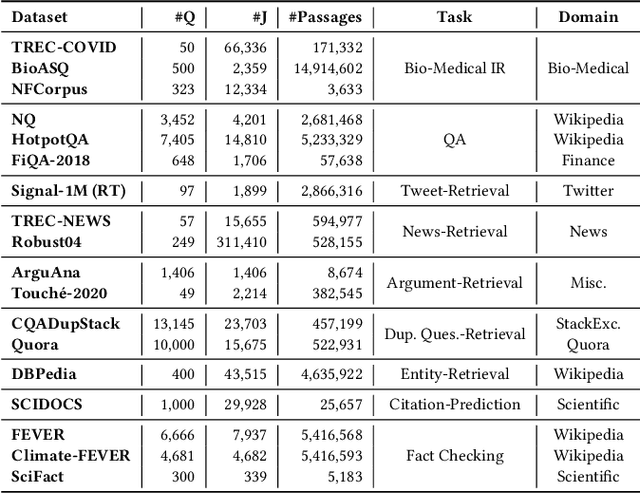

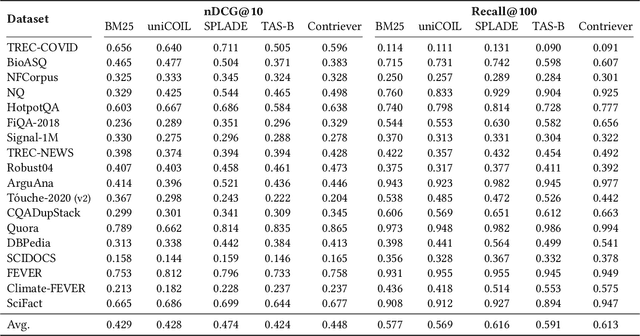
BEIR is a benchmark dataset for zero-shot evaluation of information retrieval models across 18 different domain/task combinations. In recent years, we have witnessed the growing popularity of a representation learning approach to building retrieval models, typically using pretrained transformers in a supervised setting. This naturally begs the question: How effective are these models when presented with queries and documents that differ from the training data? Examples include searching in different domains (e.g., medical or legal text) and with different types of queries (e.g., keywords vs. well-formed questions). While BEIR was designed to answer these questions, our work addresses two shortcomings that prevent the benchmark from achieving its full potential: First, the sophistication of modern neural methods and the complexity of current software infrastructure create barriers to entry for newcomers. To this end, we provide reproducible reference implementations that cover the two main classes of approaches: learned dense and sparse models. Second, there does not exist a single authoritative nexus for reporting the effectiveness of different models on BEIR, which has led to difficulty in comparing different methods. To remedy this, we present an official self-service BEIR leaderboard that provides fair and consistent comparisons of retrieval models. By addressing both shortcomings, our work facilitates future explorations in a range of interesting research questions that BEIR enables.
AToMiC: An Image/Text Retrieval Test Collection to Support Multimedia Content Creation
Apr 04, 2023



This paper presents the AToMiC (Authoring Tools for Multimedia Content) dataset, designed to advance research in image/text cross-modal retrieval. While vision-language pretrained transformers have led to significant improvements in retrieval effectiveness, existing research has relied on image-caption datasets that feature only simplistic image-text relationships and underspecified user models of retrieval tasks. To address the gap between these oversimplified settings and real-world applications for multimedia content creation, we introduce a new approach for building retrieval test collections. We leverage hierarchical structures and diverse domains of texts, styles, and types of images, as well as large-scale image-document associations embedded in Wikipedia. We formulate two tasks based on a realistic user model and validate our dataset through retrieval experiments using baseline models. AToMiC offers a testbed for scalable, diverse, and reproducible multimedia retrieval research. Finally, the dataset provides the basis for a dedicated track at the 2023 Text Retrieval Conference (TREC), and is publicly available at https://github.com/TREC-AToMiC/AToMiC.
Simple Yet Effective Neural Ranking and Reranking Baselines for Cross-Lingual Information Retrieval
Apr 03, 2023The advent of multilingual language models has generated a resurgence of interest in cross-lingual information retrieval (CLIR), which is the task of searching documents in one language with queries from another. However, the rapid pace of progress has led to a confusing panoply of methods and reproducibility has lagged behind the state of the art. In this context, our work makes two important contributions: First, we provide a conceptual framework for organizing different approaches to cross-lingual retrieval using multi-stage architectures for mono-lingual retrieval as a scaffold. Second, we implement simple yet effective reproducible baselines in the Anserini and Pyserini IR toolkits for test collections from the TREC 2022 NeuCLIR Track, in Persian, Russian, and Chinese. Our efforts are built on a collaboration of the two teams that submitted the most effective runs to the TREC evaluation. These contributions provide a firm foundation for future advances.
Evaluating Token-Level and Passage-Level Dense Retrieval Models for Math Information Retrieval
Mar 21, 2022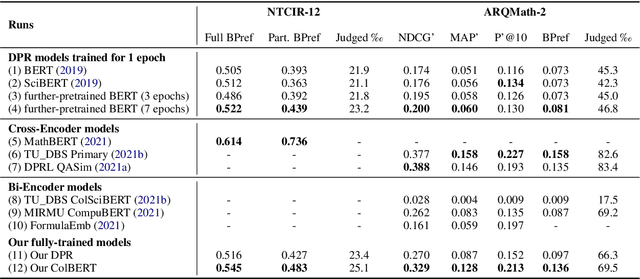
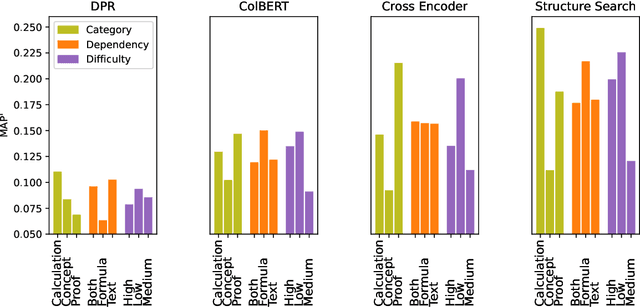
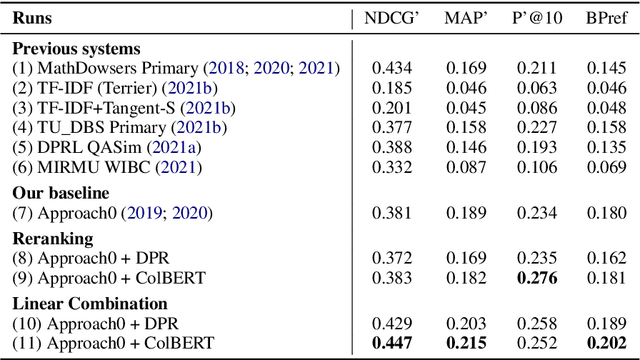
With the recent success of dense retrieval methods based on bi-encoders, a number of studies have applied this approach to various interesting downstream retrieval tasks with good efficiency and in-domain effectiveness. Recently, we have also seen the presence of dense retrieval models in Math Information Retrieval (MIR) tasks, but the most effective systems remain "classic" retrieval methods that consider rich structure features. In this work, we try to combine the best of both worlds: a well-defined structure search method for effective formula search and bi-encoder dense retrieval models to capture contextual similarities in mathematical documents. Specifically, we have evaluated two representative bi-encoder models (ColBERT and DPR) for token-level and passage-level dense retrieval on recent MIR tasks. To our best knowledge, this is the first time a DPR model has been evaluated in the MIR domain. Our result shows that bi-encoder models are complementary to existing structure search methods, and we are able to advance the state of the art on a recent MIR dataset. We have made our model checkpoints and source code publicly available for the reproduction of our results.
Sparsifying Sparse Representations for Passage Retrieval by Top-$k$ Masking
Dec 17, 2021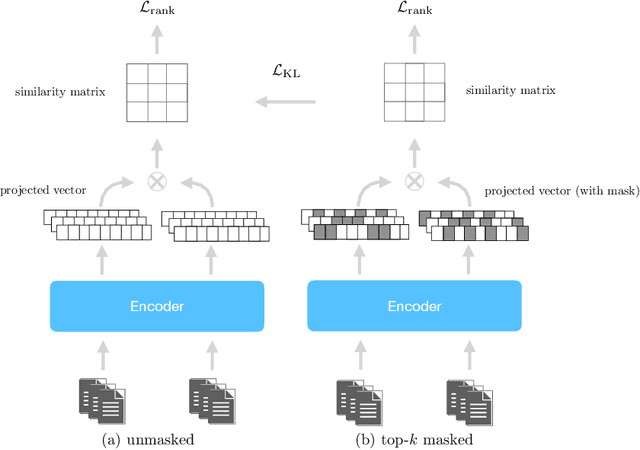
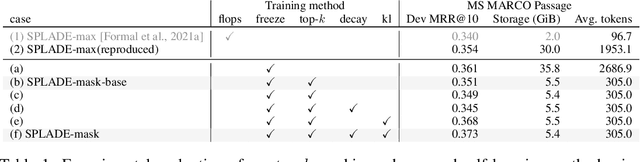
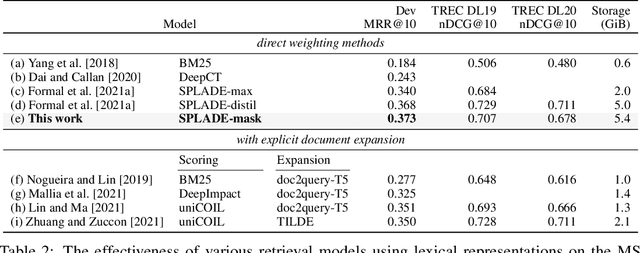
Sparse lexical representation learning has demonstrated much progress in improving passage retrieval effectiveness in recent models such as DeepImpact, uniCOIL, and SPLADE. This paper describes a straightforward yet effective approach for sparsifying lexical representations for passage retrieval, building on SPLADE by introducing a top-$k$ masking scheme to control sparsity and a self-learning method to coax masked representations to mimic unmasked representations. A basic implementation of our model is competitive with more sophisticated approaches and achieves a good balance between effectiveness and efficiency. The simplicity of our methods opens the door for future explorations in lexical representation learning for passage retrieval.
Text-to-Text Multi-view Learning for Passage Re-ranking
Apr 29, 2021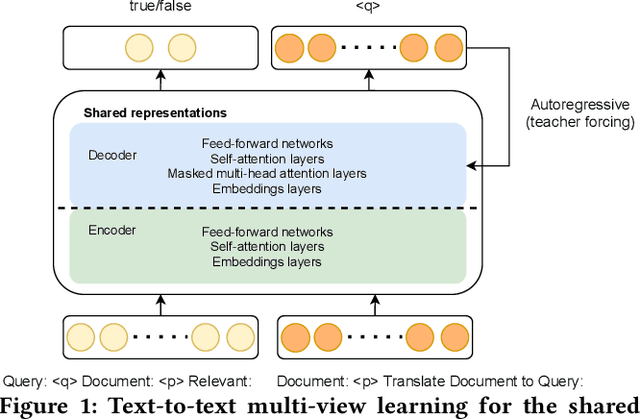
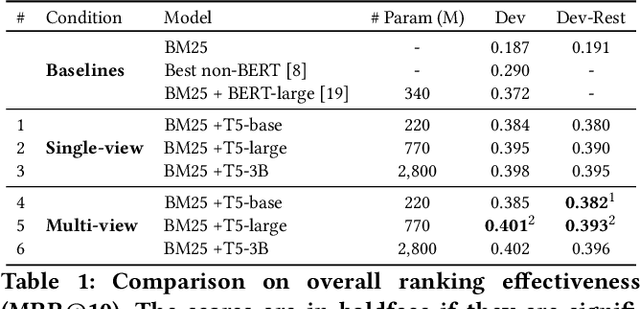
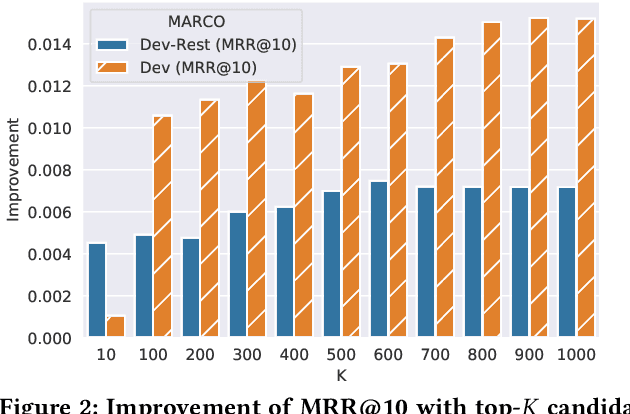
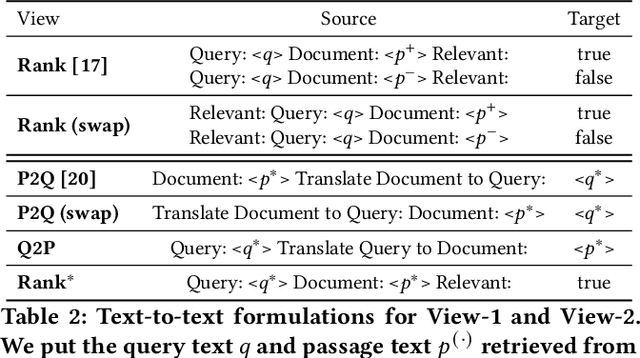
Recently, much progress in natural language processing has been driven by deep contextualized representations pretrained on large corpora. Typically, the fine-tuning on these pretrained models for a specific downstream task is based on single-view learning, which is however inadequate as a sentence can be interpreted differently from different perspectives. Therefore, in this work, we propose a text-to-text multi-view learning framework by incorporating an additional view -- the text generation view -- into a typical single-view passage ranking model. Empirically, the proposed approach is of help to the ranking performance compared to its single-view counterpart. Ablation studies are also reported in the paper.
Contextualized Query Embeddings for Conversational Search
Apr 18, 2021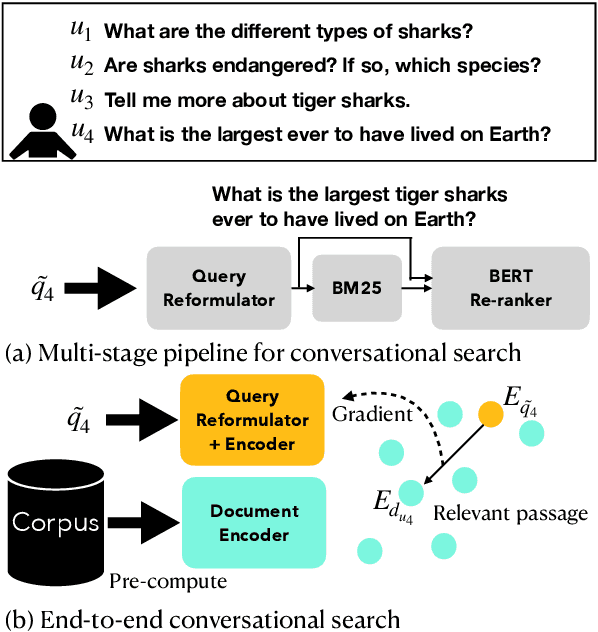
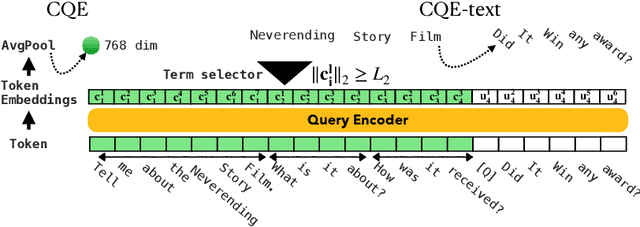
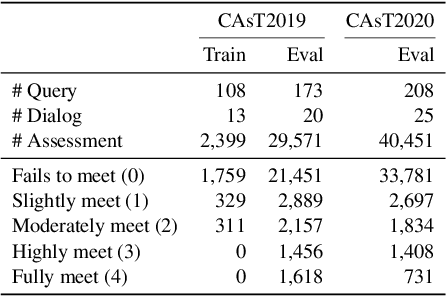
Conversational search (CS) plays a vital role in information retrieval. The current state of the art approaches the task using a multi-stage pipeline comprising conversational query reformulation and information seeking modules. Despite of its effectiveness, such a pipeline often comprises multiple neural models and thus requires long inference times. In addition, independently optimizing the effectiveness of each module does not consider the relation between modules in the pipeline. Thus, in this paper, we propose a single-stage design, which supports end-to-end training and low-latency inference. To aid in this goal, we create a synthetic dataset for CS to overcome the lack of training data and explore different training strategies using this dataset. Experiments demonstrate that our model yields competitive retrieval effectiveness against state-of-the-art multi-stage approaches but with lower latency. Furthermore, we show that improved retrieval effectiveness benefits the downstream task of conversational question answering.
Efficiently Teaching an Effective Dense Retriever with Balanced Topic Aware Sampling
Apr 14, 2021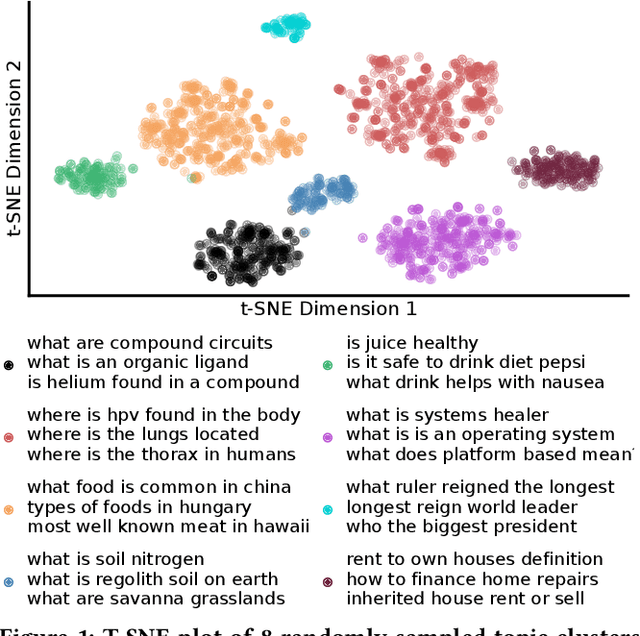
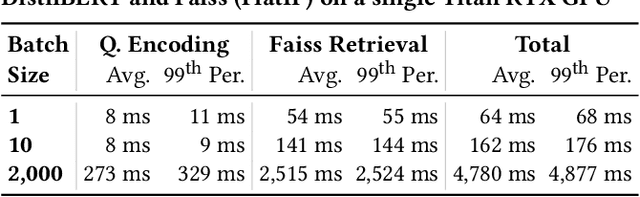
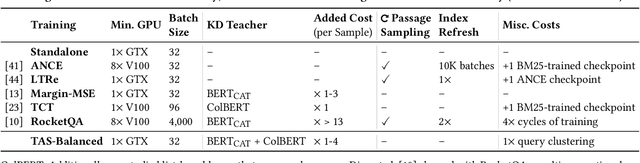
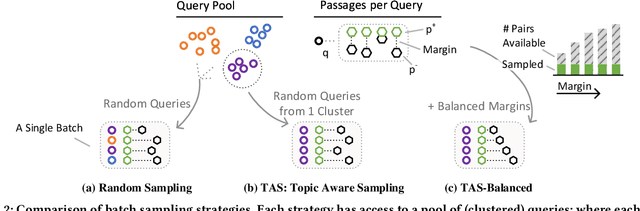
A vital step towards the widespread adoption of neural retrieval models is their resource efficiency throughout the training, indexing and query workflows. The neural IR community made great advancements in training effective dual-encoder dense retrieval (DR) models recently. A dense text retrieval model uses a single vector representation per query and passage to score a match, which enables low-latency first stage retrieval with a nearest neighbor search. Increasingly common, training approaches require enormous compute power, as they either conduct negative passage sampling out of a continuously updating refreshing index or require very large batch sizes for in-batch negative sampling. Instead of relying on more compute capability, we introduce an efficient topic-aware query and balanced margin sampling technique, called TAS-Balanced. We cluster queries once before training and sample queries out of a cluster per batch. We train our lightweight 6-layer DR model with a novel dual-teacher supervision that combines pairwise and in-batch negative teachers. Our method is trainable on a single consumer-grade GPU in under 48 hours (as opposed to a common configuration of 8x V100s). We show that our TAS-Balanced training method achieves state-of-the-art low-latency (64ms per query) results on two TREC Deep Learning Track query sets. Evaluated on NDCG@10, we outperform BM25 by 44%, a plainly trained DR by 19%, docT5query by 11%, and the previous best DR model by 5%. Additionally, TAS-Balanced produces the first dense retriever that outperforms every other method on recall at any cutoff on TREC-DL and allows more resource intensive re-ranking models to operate on fewer passages to improve results further.
Pyserini: An Easy-to-Use Python Toolkit to Support Replicable IR Research with Sparse and Dense Representations
Feb 19, 2021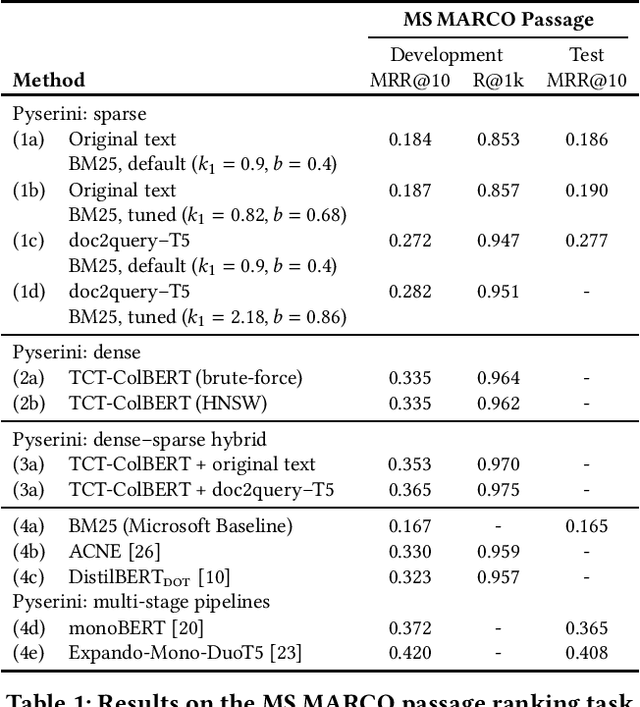
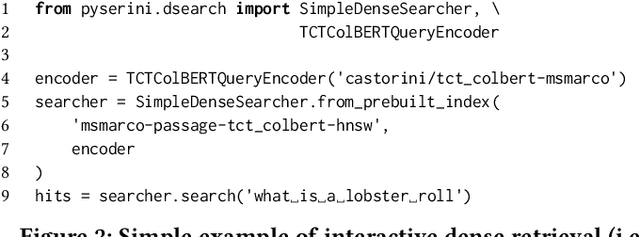
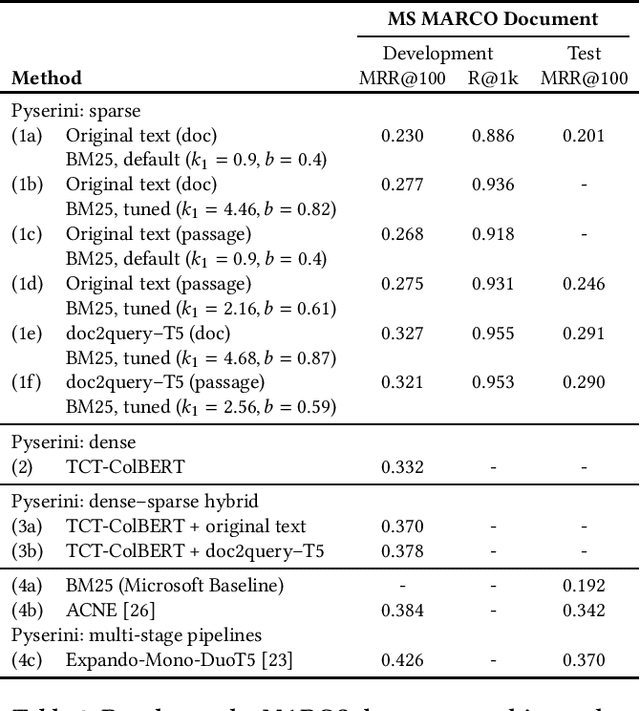
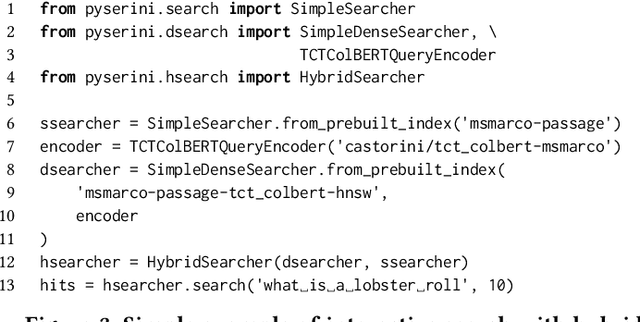
Pyserini is an easy-to-use Python toolkit that supports replicable IR research by providing effective first-stage retrieval in a multi-stage ranking architecture. Our toolkit is self-contained as a standard Python package and comes with queries, relevance judgments, pre-built indexes, and evaluation scripts for many commonly used IR test collections. We aim to support, out of the box, the entire research lifecycle of efforts aimed at improving ranking with modern neural approaches. In particular, Pyserini supports sparse retrieval (e.g., BM25 scoring using bag-of-words representations), dense retrieval (e.g., nearest-neighbor search on transformer-encoded representations), as well as hybrid retrieval that integrates both approaches. This paper provides an overview of toolkit features and presents empirical results that illustrate its effectiveness on two popular ranking tasks. We also describe how our group has built a culture of replicability through shared norms and tools that enable rigorous automated testing.