 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefract ICL: Rethinking Example Selection in the Era of Million-Token Models
Jun 14, 2025The emergence of long-context large language models (LLMs) has enabled the use of hundreds, or even thousands, of demonstrations for in-context learning (ICL) - a previously impractical regime. This paper investigates whether traditional ICL selection strategies, which balance the similarity of ICL examples to the test input (using a text retriever) with diversity within the ICL set, remain effective when utilizing a large number of demonstrations. Our experiments demonstrate that, while longer contexts can accommodate more examples, simply increasing the number of demonstrations does not guarantee improved performance. Smart ICL selection remains crucial, even with thousands of demonstrations. To further enhance ICL in this setting, we introduce Refract ICL, a novel ICL selection algorithm specifically designed to focus LLM attention on challenging examples by strategically repeating them within the context and incorporating zero-shot predictions as error signals. Our results show that Refract ICL significantly improves the performance of extremely long-context models such as Gemini 1.5 Pro, particularly on tasks with a smaller number of output classes.
Ambiguity-Aware In-Context Learning with Large Language Models
Sep 14, 2023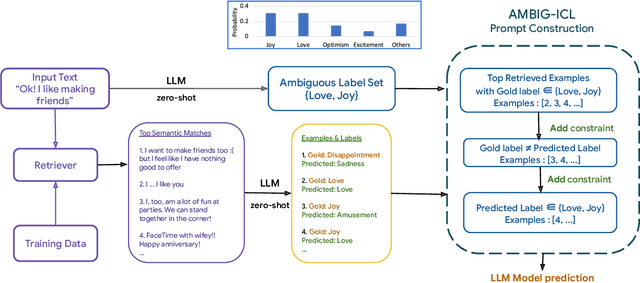
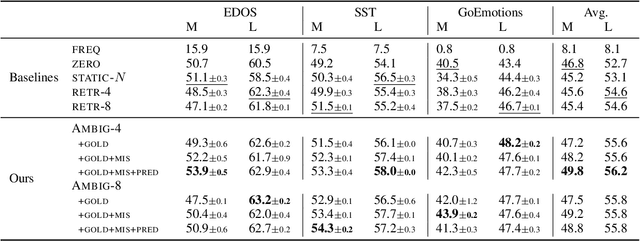
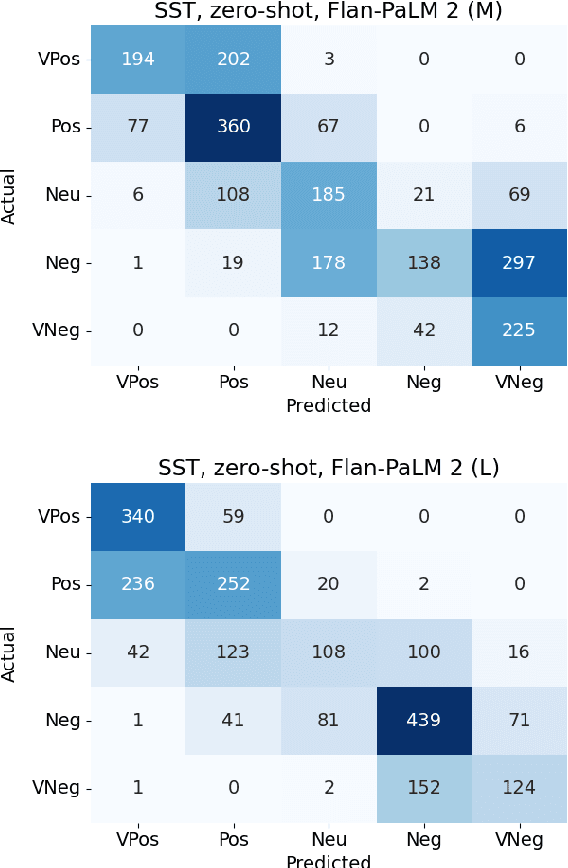
In-context learning (ICL) i.e. showing LLMs only a few task-specific demonstrations has led to downstream gains with no task-specific fine-tuning required. However, LLMs are sensitive to the choice of prompts, and therefore a crucial research question is how to select good demonstrations for ICL. One effective strategy is leveraging semantic similarity between the ICL demonstrations and test inputs by using a text retriever, which however is sub-optimal as that does not consider the LLM's existing knowledge about that task. From prior work (Min et al., 2022), we already know that labels paired with the demonstrations bias the model predictions. This leads us to our hypothesis whether considering LLM's existing knowledge about the task, especially with respect to the output label space can help in a better demonstration selection strategy. Through extensive experimentation on three text classification tasks, we find that it is beneficial to not only choose semantically similar ICL demonstrations but also to choose those demonstrations that help resolve the inherent label ambiguity surrounding the test example. Interestingly, we find that including demonstrations that the LLM previously mis-classified and also fall on the test example's decision boundary, brings the most performance gain.
Exploring the Viability of Synthetic Query Generation for Relevance Prediction
May 19, 2023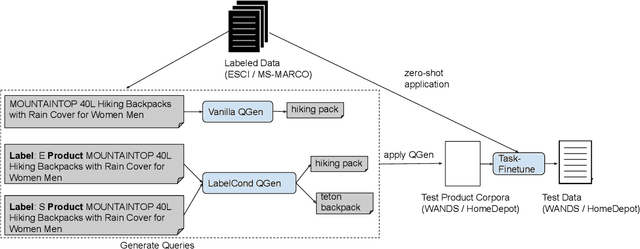
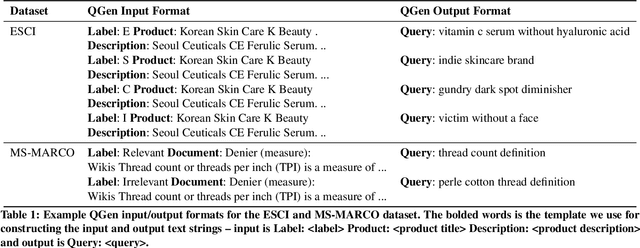

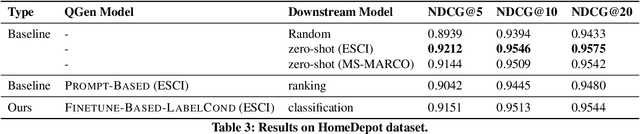
Query-document relevance prediction is a critical problem in Information Retrieval systems. This problem has increasingly been tackled using (pretrained) transformer-based models which are finetuned using large collections of labeled data. However, in specialized domains such as e-commerce and healthcare, the viability of this approach is limited by the dearth of large in-domain data. To address this paucity, recent methods leverage these powerful models to generate high-quality task and domain-specific synthetic data. Prior work has largely explored synthetic data generation or query generation (QGen) for Question-Answering (QA) and binary (yes/no) relevance prediction, where for instance, the QGen models are given a document, and trained to generate a query relevant to that document. However in many problems, we have a more fine-grained notion of relevance than a simple yes/no label. Thus, in this work, we conduct a detailed study into how QGen approaches can be leveraged for nuanced relevance prediction. We demonstrate that -- contrary to claims from prior works -- current QGen approaches fall short of the more conventional cross-domain transfer-learning approaches. Via empirical studies spanning 3 public e-commerce benchmarks, we identify new shortcomings of existing QGen approaches -- including their inability to distinguish between different grades of relevance. To address this, we introduce label-conditioned QGen models which incorporates knowledge about the different relevance. While our experiments demonstrate that these modifications help improve performance of QGen techniques, we also find that QGen approaches struggle to capture the full nuance of the relevance label space and as a result the generated queries are not faithful to the desired relevance label.
WikiWeb2M: A Page-Level Multimodal Wikipedia Dataset
May 09, 2023


Webpages have been a rich resource for language and vision-language tasks. Yet only pieces of webpages are kept: image-caption pairs, long text articles, or raw HTML, never all in one place. Webpage tasks have resultingly received little attention and structured image-text data underused. To study multimodal webpage understanding, we introduce the Wikipedia Webpage 2M (WikiWeb2M) suite; the first to retain the full set of images, text, and structure data available in a page. WikiWeb2M can be used for tasks like page description generation, section summarization, and contextual image captioning.
A Suite of Generative Tasks for Multi-Level Multimodal Webpage Understanding
May 05, 2023Webpages have been a rich, scalable resource for vision-language and language only tasks. Yet only pieces of webpages are kept: image-caption pairs, long text articles, or raw HTML, never all in one place. Webpage tasks have resultingly received little attention and structured image-text data left underused. To study multimodal webpage understanding, we introduce the Wikipedia Webpage suite (WikiWeb2M) of 2M pages. We verify its utility on three generative tasks: page description generation, section summarization, and contextual image captioning. We design a novel attention mechanism Prefix Global, which selects the most relevant image and text content as global tokens to attend to the rest of the webpage for context. By using page structure to separate such tokens, it performs better than full attention with lower computational complexity. Experiments show that the new annotations from WikiWeb2M improve task performance compared to data from prior work. We also include ablations on sequence length, input features, and model size.
AToMiC: An Image/Text Retrieval Test Collection to Support Multimedia Content Creation
Apr 04, 2023



This paper presents the AToMiC (Authoring Tools for Multimedia Content) dataset, designed to advance research in image/text cross-modal retrieval. While vision-language pretrained transformers have led to significant improvements in retrieval effectiveness, existing research has relied on image-caption datasets that feature only simplistic image-text relationships and underspecified user models of retrieval tasks. To address the gap between these oversimplified settings and real-world applications for multimedia content creation, we introduce a new approach for building retrieval test collections. We leverage hierarchical structures and diverse domains of texts, styles, and types of images, as well as large-scale image-document associations embedded in Wikipedia. We formulate two tasks based on a realistic user model and validate our dataset through retrieval experiments using baseline models. AToMiC offers a testbed for scalable, diverse, and reproducible multimedia retrieval research. Finally, the dataset provides the basis for a dedicated track at the 2023 Text Retrieval Conference (TREC), and is publicly available at https://github.com/TREC-AToMiC/AToMiC.
QUILL: Query Intent with Large Language Models using Retrieval Augmentation and Multi-stage Distillation
Oct 27, 2022Large Language Models (LLMs) have shown impressive results on a variety of text understanding tasks. Search queries though pose a unique challenge, given their short-length and lack of nuance or context. Complicated feature engineering efforts do not always lead to downstream improvements as their performance benefits may be offset by increased complexity of knowledge distillation. Thus, in this paper we make the following contributions: (1) We demonstrate that Retrieval Augmentation of queries provides LLMs with valuable additional context enabling improved understanding. While Retrieval Augmentation typically increases latency of LMs (thus hurting distillation efficacy), (2) we provide a practical and effective way of distilling Retrieval Augmentation LLMs. Specifically, we use a novel two-stage distillation approach that allows us to carry over the gains of retrieval augmentation, without suffering the increased compute typically associated with it. (3) We demonstrate the benefits of the proposed approach (QUILL) on a billion-scale, real-world query understanding system resulting in huge gains. Via extensive experiments, including on public benchmarks, we believe this work offers a recipe for practical use of retrieval-augmented query understanding.
Transforming Sequence Tagging Into A Seq2Seq Task
Mar 16, 2022

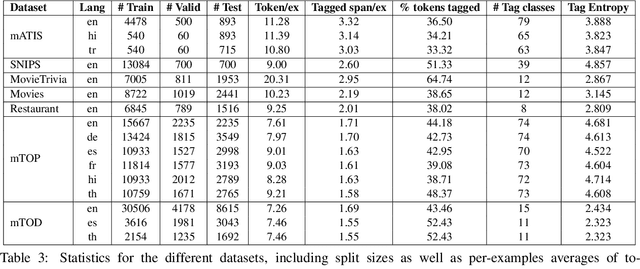
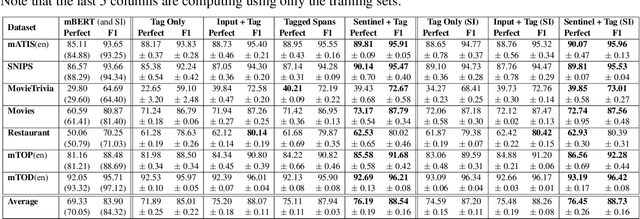
Pretrained, large, generative language models (LMs) have had great success in a wide range of sequence tagging and structured prediction tasks. Casting a sequence tagging task as a Seq2Seq one requires deciding the formats of the input and output sequences. However, we lack a principled understanding of the trade-offs associated with these formats (such as the effect on model accuracy, sequence length, multilingual generalization, hallucination). In this paper, we rigorously study different formats one could use for casting input text sentences and their output labels into the input and target (i.e., output) of a Seq2Seq model. Along the way, we introduce a new format, which we show to not only be simpler but also more effective. Additionally the new format demonstrates significant gains in the multilingual settings -- both zero-shot transfer learning and joint training. Lastly, we find that the new format is more robust and almost completely devoid of hallucination -- an issue we find common in existing formats. With well over a 1000 experiments studying 14 different formats, over 7 diverse public benchmarks -- including 3 multilingual datasets spanning 7 languages -- we believe our findings provide a strong empirical basis in understanding how we should tackle sequence tagging tasks.
MURAL: Multimodal, Multitask Retrieval Across Languages
Sep 10, 2021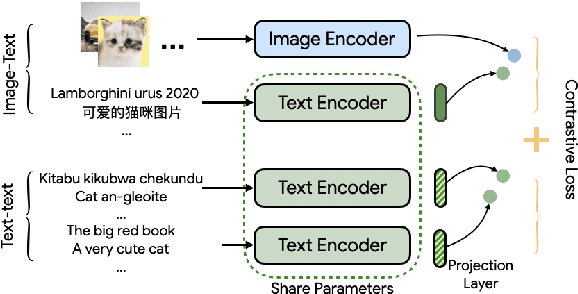
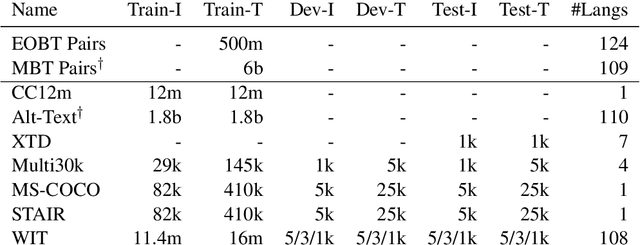
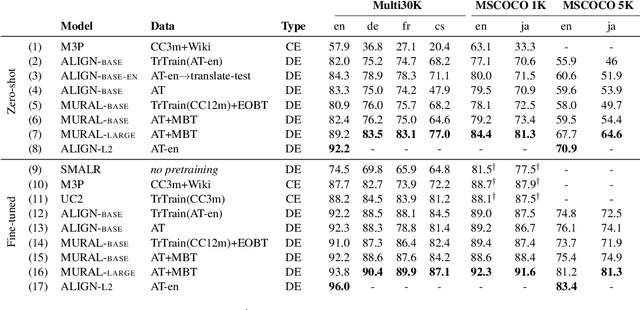
Both image-caption pairs and translation pairs provide the means to learn deep representations of and connections between languages. We use both types of pairs in MURAL (MUltimodal, MUltitask Representations Across Languages), a dual encoder that solves two tasks: 1) image-text matching and 2) translation pair matching. By incorporating billions of translation pairs, MURAL extends ALIGN (Jia et al. PMLR'21)--a state-of-the-art dual encoder learned from 1.8 billion noisy image-text pairs. When using the same encoders, MURAL's performance matches or exceeds ALIGN's cross-modal retrieval performance on well-resourced languages across several datasets. More importantly, it considerably improves performance on under-resourced languages, showing that text-text learning can overcome a paucity of image-caption examples for these languages. On the Wikipedia Image-Text dataset, for example, MURAL-base improves zero-shot mean recall by 8.1% on average for eight under-resourced languages and by 6.8% on average when fine-tuning. We additionally show that MURAL's text representations cluster not only with respect to genealogical connections but also based on areal linguistics, such as the Balkan Sprachbund.
WIT: Wikipedia-based Image Text Dataset for Multimodal Multilingual Machine Learning
Mar 03, 2021
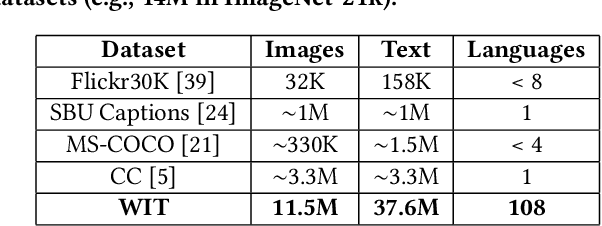
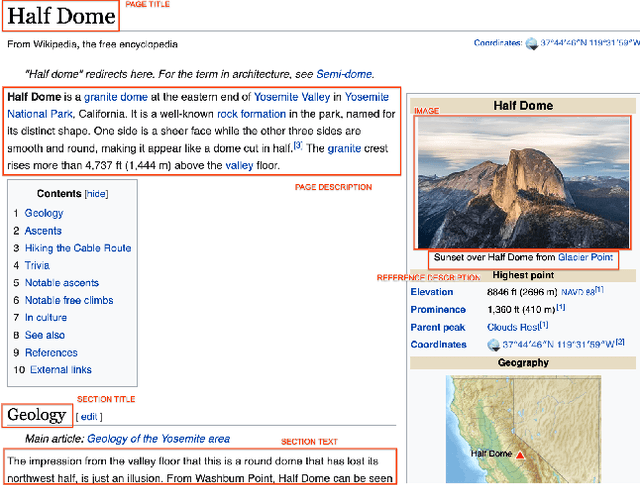
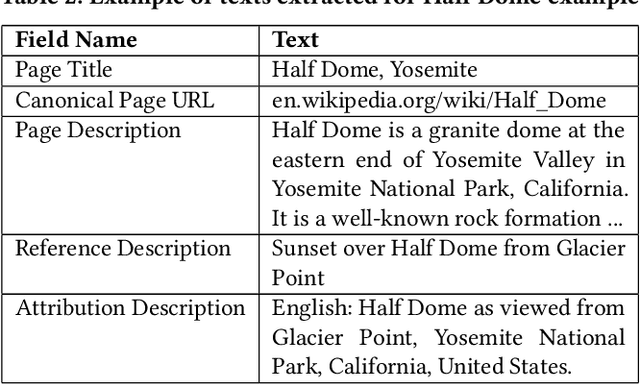
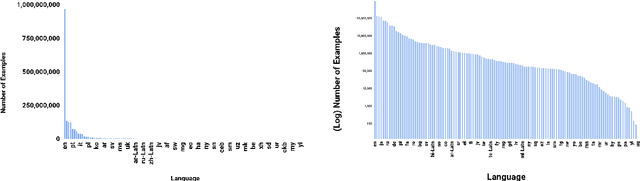
The milestone improvements brought about by deep representation learning and pre-training techniques have led to large performance gains across downstream NLP, IR and Vision tasks. Multimodal modeling techniques aim to leverage large high-quality visio-linguistic datasets for learning complementary information (across image and text modalities). In this paper, we introduce the Wikipedia-based Image Text (WIT) Dataset (https://github.com/google-research-datasets/wit) to better facilitate multimodal, multilingual learning. WIT is composed of a curated set of 37.6 million entity rich image-text examples with 11.5 million unique images across 108 Wikipedia languages. Its size enables WIT to be used as a pretraining dataset for multimodal models, as we show when applied to downstream tasks such as image-text retrieval. WIT has four main and unique advantages. First, WIT is the largest multimodal dataset by the number of image-text examples by 3x (at the time of writing). Second, WIT is massively multilingual (first of its kind) with coverage over 100+ languages (each of which has at least 12K examples) and provides cross-lingual texts for many images. Third, WIT represents a more diverse set of concepts and real world entities relative to what previous datasets cover. Lastly, WIT provides a very challenging real-world test set, as we empirically illustrate using an image-text retrieval task as an example.