 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRefract ICL: Rethinking Example Selection in the Era of Million-Token Models
Jun 14, 2025The emergence of long-context large language models (LLMs) has enabled the use of hundreds, or even thousands, of demonstrations for in-context learning (ICL) - a previously impractical regime. This paper investigates whether traditional ICL selection strategies, which balance the similarity of ICL examples to the test input (using a text retriever) with diversity within the ICL set, remain effective when utilizing a large number of demonstrations. Our experiments demonstrate that, while longer contexts can accommodate more examples, simply increasing the number of demonstrations does not guarantee improved performance. Smart ICL selection remains crucial, even with thousands of demonstrations. To further enhance ICL in this setting, we introduce Refract ICL, a novel ICL selection algorithm specifically designed to focus LLM attention on challenging examples by strategically repeating them within the context and incorporating zero-shot predictions as error signals. Our results show that Refract ICL significantly improves the performance of extremely long-context models such as Gemini 1.5 Pro, particularly on tasks with a smaller number of output classes.
KAFA: Rethinking Image Ad Understanding with Knowledge-Augmented Feature Adaptation of Vision-Language Models
May 28, 2023



Image ad understanding is a crucial task with wide real-world applications. Although highly challenging with the involvement of diverse atypical scenes, real-world entities, and reasoning over scene-texts, how to interpret image ads is relatively under-explored, especially in the era of foundational vision-language models (VLMs) featuring impressive generalizability and adaptability. In this paper, we perform the first empirical study of image ad understanding through the lens of pre-trained VLMs. We benchmark and reveal practical challenges in adapting these VLMs to image ad understanding. We propose a simple feature adaptation strategy to effectively fuse multimodal information for image ads and further empower it with knowledge of real-world entities. We hope our study draws more attention to image ad understanding which is broadly relevant to the advertising industry.
MetaCLUE: Towards Comprehensive Visual Metaphors Research
Dec 19, 2022



Creativity is an indispensable part of human cognition and also an inherent part of how we make sense of the world. Metaphorical abstraction is fundamental in communicating creative ideas through nuanced relationships between abstract concepts such as feelings. While computer vision benchmarks and approaches predominantly focus on understanding and generating literal interpretations of images, metaphorical comprehension of images remains relatively unexplored. Towards this goal, we introduce MetaCLUE, a set of vision tasks on visual metaphor. We also collect high-quality and rich metaphor annotations (abstract objects, concepts, relationships along with their corresponding object boxes) as there do not exist any datasets that facilitate the evaluation of these tasks. We perform a comprehensive analysis of state-of-the-art models in vision and language based on our annotations, highlighting strengths and weaknesses of current approaches in visual metaphor Classification, Localization, Understanding (retrieval, question answering, captioning) and gEneration (text-to-image synthesis) tasks. We hope this work provides a concrete step towards developing AI systems with human-like creative capabilities.
Question Generation for Evaluating Cross-Dataset Shifts in Multi-modal Grounding
Jan 24, 2022
Visual question answering (VQA) is the multi-modal task of answering natural language questions about an input image. Through cross-dataset adaptation methods, it is possible to transfer knowledge from a source dataset with larger train samples to a target dataset where training set is limited. Suppose a VQA model trained on one dataset train set fails in adapting to another, it is hard to identify the underlying cause of domain mismatch as there could exists a multitude of reasons such as image distribution mismatch and question distribution mismatch. At UCLA, we are working on a VQG module that facilitate in automatically generating OOD shifts that aid in systematically evaluating cross-dataset adaptation capabilities of VQA models.
CX-ToM: Counterfactual Explanations with Theory-of-Mind for Enhancing Human Trust in Image Recognition Models
Sep 06, 2021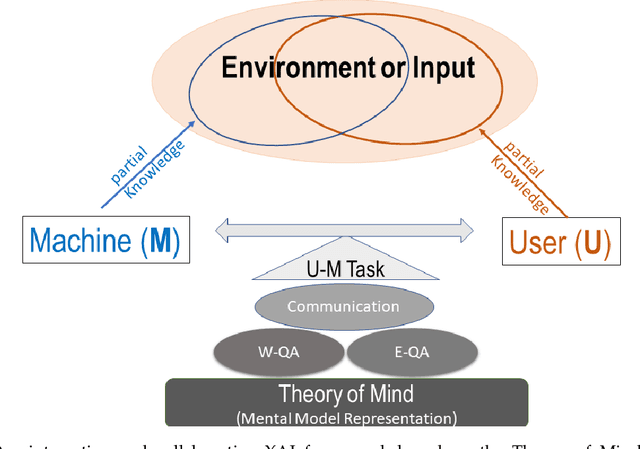
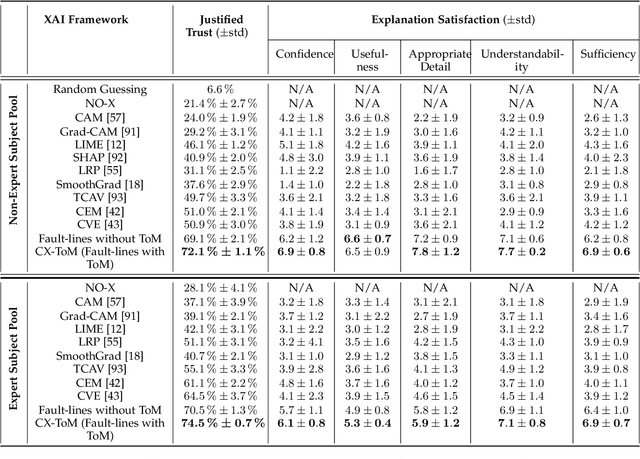
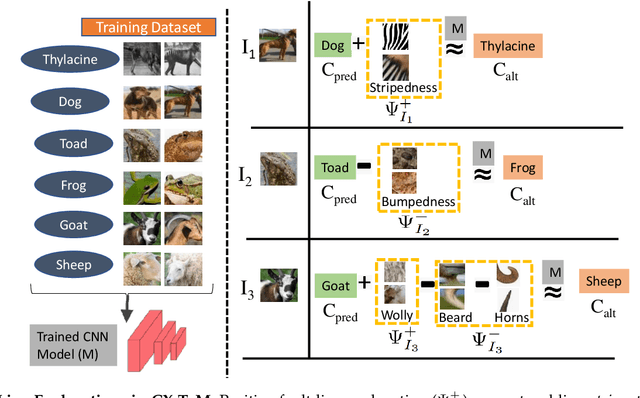
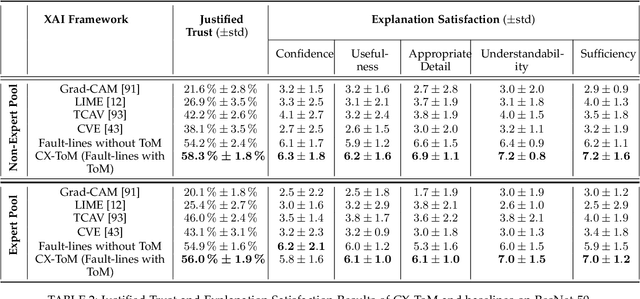
We propose CX-ToM, short for counterfactual explanations with theory-of mind, a new explainable AI (XAI) framework for explaining decisions made by a deep convolutional neural network (CNN). In contrast to the current methods in XAI that generate explanations as a single shot response, we pose explanation as an iterative communication process, i.e. dialog, between the machine and human user. More concretely, our CX-ToM framework generates sequence of explanations in a dialog by mediating the differences between the minds of machine and human user. To do this, we use Theory of Mind (ToM) which helps us in explicitly modeling human's intention, machine's mind as inferred by the human as well as human's mind as inferred by the machine. Moreover, most state-of-the-art XAI frameworks provide attention (or heat map) based explanations. In our work, we show that these attention based explanations are not sufficient for increasing human trust in the underlying CNN model. In CX-ToM, we instead use counterfactual explanations called fault-lines which we define as follows: given an input image I for which a CNN classification model M predicts class c_pred, a fault-line identifies the minimal semantic-level features (e.g., stripes on zebra, pointed ears of dog), referred to as explainable concepts, that need to be added to or deleted from I in order to alter the classification category of I by M to another specified class c_alt. We argue that, due to the iterative, conceptual and counterfactual nature of CX-ToM explanations, our framework is practical and more natural for both expert and non-expert users to understand the internal workings of complex deep learning models. Extensive quantitative and qualitative experiments verify our hypotheses, demonstrating that our CX-ToM significantly outperforms the state-of-the-art explainable AI models.
X-ToM: Explaining with Theory-of-Mind for Gaining Justified Human Trust
Sep 15, 2019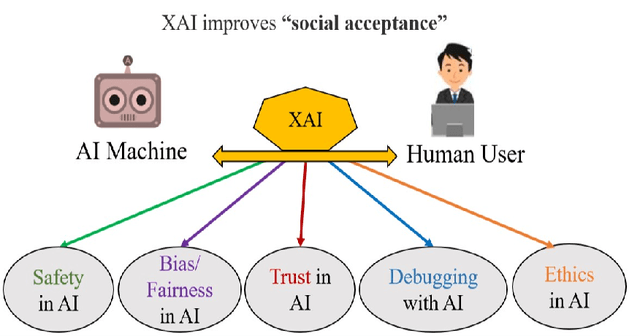

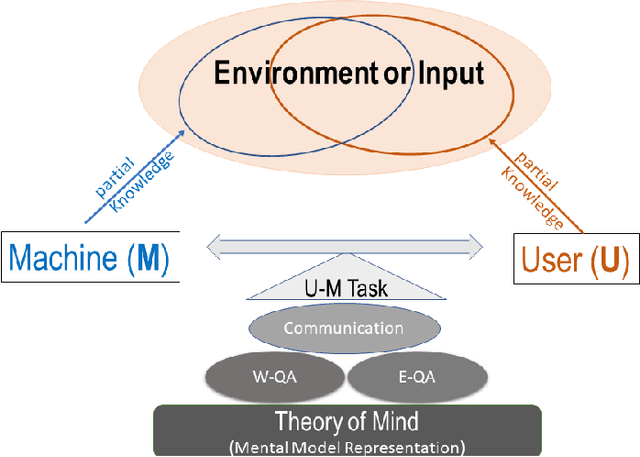
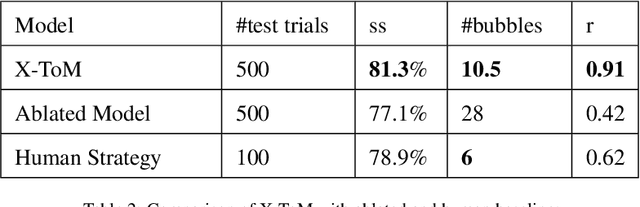
We present a new explainable AI (XAI) framework aimed at increasing justified human trust and reliance in the AI machine through explanations. We pose explanation as an iterative communication process, i.e. dialog, between the machine and human user. More concretely, the machine generates sequence of explanations in a dialog which takes into account three important aspects at each dialog turn: (a) human's intention (or curiosity); (b) human's understanding of the machine; and (c) machine's understanding of the human user. To do this, we use Theory of Mind (ToM) which helps us in explicitly modeling human's intention, machine's mind as inferred by the human as well as human's mind as inferred by the machine. In other words, these explicit mental representations in ToM are incorporated to learn an optimal explanation policy that takes into account human's perception and beliefs. Furthermore, we also show that ToM facilitates in quantitatively measuring justified human trust in the machine by comparing all the three mental representations. We applied our framework to three visual recognition tasks, namely, image classification, action recognition, and human body pose estimation. We argue that our ToM based explanations are practical and more natural for both expert and non-expert users to understand the internal workings of complex machine learning models. To the best of our knowledge, this is the first work to derive explanations using ToM. Extensive human study experiments verify our hypotheses, showing that the proposed explanations significantly outperform the state-of-the-art XAI methods in terms of all the standard quantitative and qualitative XAI evaluation metrics including human trust, reliance, and explanation satisfaction.